
- 1很薄很经典,这套写给程序员的技术书凭什么销量10万+
- 2Vue根据网络文件路径下载文件【自定义属性 v-down】_vue下载文件存放路径自定义
- 3Java教父Joshua Bloch访谈_josh bloch
- 4python开心消消乐辅助_用Python写个开心消消乐小游戏
- 5达梦数据库工具使用_达梦 truncate和replace
- 6AI编程篇-python高级进阶_ai辅助python编程
- 7如何在Windows环境下安装mysql并且设置自动启动(超详细)_windows设置mysql服务开机自启
- 8YOLOv5-Fog: A Multiobjective Visual DetectionAlgorithm for Fog Driving Scenes Based onImproved YOLOv_yolov5去雾
- 9Flink内核源码(七)Flink SQL提交流程_flinksql提交流程
- 10python一维数组排序_【Python】数组排序
CVPR2024《RMT: Retentive Networks Meet Vision Transformers》论文阅读笔记
赞
踩
论文链接:https://arxiv.org/pdf/2309.11523
代码链接:https://github.com/qhfan/RMT
引言

ViT近年来在计算机视觉领域受到了越来越多的关注。然而,作为ViT的核心模块--自注意力缺乏空间先验知识。此外,自注意力的二次计算复杂度在建模全局信息时的计算成本过高。这些问题限制了ViT的应用。许多先前的工作已经尝试缓解这些问题。例如,在Swin Transformer中,作者通过应用窗口化操作来划分用于自注意力的tokens。这一操作不仅减少了自注意力的计算成本,而且还通过窗口和相对位置编码的使用向模型引入了空间先验。除此之外,NAT改变了自注意力的感受野以匹配卷积的形状,在减少计算成本的同时,也使模型能够通过其感受野的形状感知空间先验。与之前的方法不同,作者从最近在NLP领域取得成功的保留网络(Retentive Network,简称RetNet)中获得灵感。RetNet利用依赖于距离的时间衰减矩阵为一维和单向文本数据提供显式的时间先验。作者将这种时间衰减矩阵扩展到空间领域,提出基于tokens间的曼哈顿距离的二维双向空间衰减矩阵。在空间衰减矩阵中,对于一个目标token,周围的tokens越远,它们的注意力得分衰减程度越大。这种属性允许目标token在感知全局信息的同时,对不同距离的tokens分配不同程度的注意力。作者使用这种空间衰减矩阵向视觉骨干引入显式的空间先验。将这种受RetNet启发并结合曼哈顿距离作为显式空间先验的自注意力机制命名为曼哈顿自注意力(Manhattan Self-Attention,简称MaSA)。除了显式的空间先验外,由自注意力进行全局建模引起的另一个问题是巨大的计算负担。以前的稀疏注意力机制以及RetNet中保留的分解方式大多会破坏基于曼哈顿距离的空间衰减矩阵,使它们不适用于MaSA。为了在不破坏空间衰减矩阵的情况下稀疏地建模全局信息,作者提出沿图像的两个轴分解自注意力的方法。这种分解方法在不丢失先验信息的情况下分解了自注意力和空间衰减矩阵。分解后的MaSA以线性复杂度对全局信息进行建模,并具有与原始MaSA相同的感受野形状。

在MaSA中,较深的颜色表示较小的空间衰减率,而较浅的颜色表示较大的空间衰减率。随着距离变化的空间衰减率为模型提供了丰富的空间先验信息。
创新点
1、提出基于曼哈顿距离的空间衰减矩阵MaSA来增强自注意力
2、提出MaSA的分解形式,使得全局信息建模具有线性复杂度,同时不破坏空间衰减矩阵
3、利用MaSA,构建RMT。RMT在ImageNet-1k图像分类上取得了高top-1准确率,无需额外训练数据,并在目标检测、实例分割和语义分割等任务中表现出色
方法论
RetNet的时间衰减
RetNet是一种强大的语言模型架构。这项工作提出了一种用于序列建模的保留机制。保留机制将时间衰减引入到语言模型中。保留机制首先以一种递归的方式考虑序列建模问题。可以用如下公式表示,

在序列处理任务中,单向模型只能利用当前时间步之前的所有信息。例如,在自然语言处理中的自回归模型,当前词的预测只能基于之前的词,而不能使用之后的词。因此只有当n≥m时,才会有权重
MaSA
从RetNet中的保留机制出发,作者将其改写为MaSA。在MaSA中,作者将保留机制中观察到的单向和一维的时间衰减转变为双向和二维的空间衰减。这种空间衰减引入了一个与曼哈顿距离相关的显式空间先验到视觉骨干中。此外,作者还设计了一种简单的方法来同时分解自注意力和空间衰减矩阵。
从单向衰减到双向衰减
在RetNet中,由于文本数据的因果特性,保留机制是单向的,只允许每个token关注前面的tokens而不是后面的tokens。这一特性不适用于缺乏因果属性的任务,例如图像识别。因此,作者首先将保留扩展为双向形式,表示为,
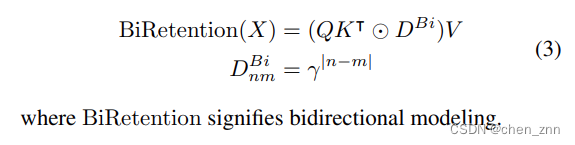
从一维衰减到二维衰减
虽然修改后的Retention支持双向建模,但这种能力仍然局限于一维,对于二维图像来说是不够的。为了解决这个限制,作者将一维保留扩展到二维。在图像的上下文中,每个token在平面内具有唯一的二维坐标位置,第n个token的坐标表示为(xn, yn)。为了适应这一点,作者将矩阵D中的每个元素调整为基于它们2D坐标的曼哈顿距离。矩阵D重新定义如下,

此外,在Retention中,softmax被替换为门控函数(gating function)。这种变化为RetNet提供了多种灵活的计算形式,使其能够适应并行训练和递归推理过程。但作者发现,这种修改对于视觉模型来说,并没有改进;相反,它引入了额外的参数和计算复杂性。因此,作者继续使用softmax来为模型引入非线性。结合上述步骤,曼哈顿自注意力表示为,

分解的MaSA
在ViT backbone的早期阶段,大量的tokens导致在尝试对全局信息进行建模时自注意力的计算成本巨大。使用现有的稀疏注意力机制或者直接使用RetNet的递归/分块递归形式,会破坏基于曼哈顿距离的空间衰减矩阵,丢失显式空间先验。为了在不破坏空间衰减矩阵的情况下稀疏地建模全局信息,作者引入了一种简单的分解方法,该方法不仅分解了自注意力,还分解了空间衰减矩阵。分解的MaSA如下,
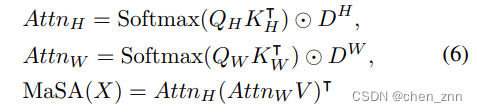
![]()
具体来说,作者分别计算图像水平和垂直方向的注意力分数。然后,将一维双向衰减矩阵应用于这些注意力权重。
基于MaSA的分解,每个tokens的感受野形状如下图所示,它与完整MaSA的感受野形状相同。该图表明分解方法完全保留了显式的空间先验。

为了进一步增强MaSA的局部表达能力,作者引入了一个局部上下文增强模块(local context enhancement module,简称LCE,由深度可分离卷积构成),

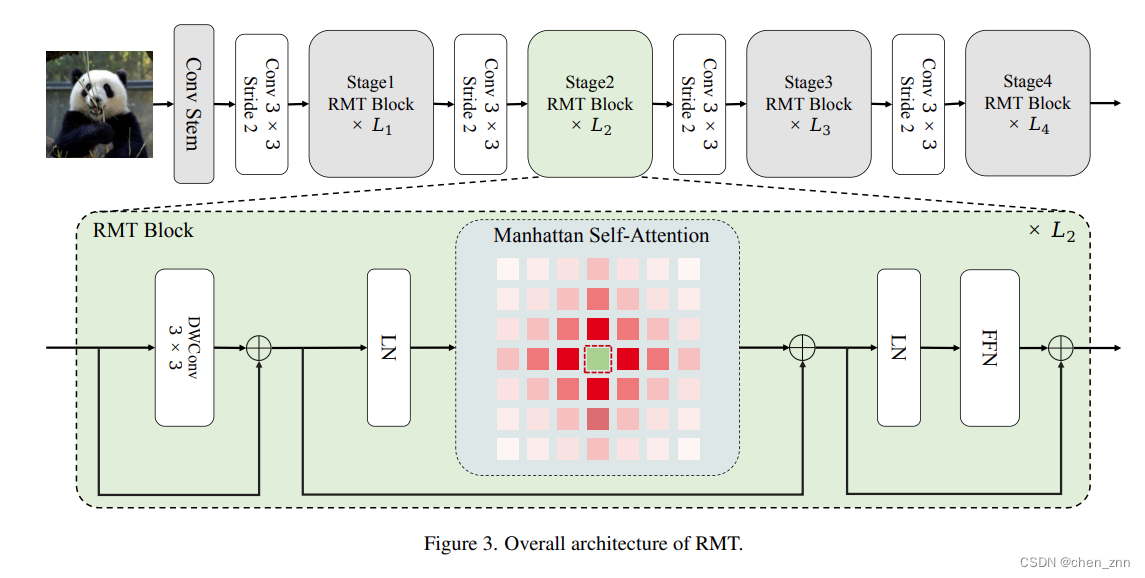
整体架构
与之前的通用ViT骨干网络类似,RMT分成了4个阶段。前3个阶段使用分解的MaSA,最后一个阶段使用原始的MaSA。此外,作者将条件位置编码(conditional positional encodings,简称CPE)集成到模型中。
实验
图像分类
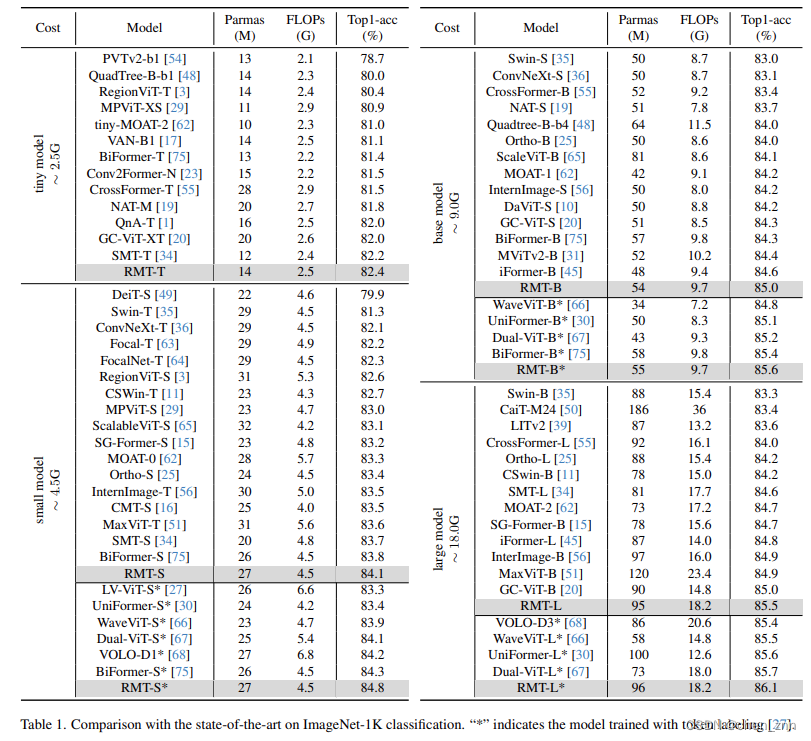
结果表明,RMT在所有设置中一致优于先前的模型。具体来说,RMT-S仅使用4.5 GFLOPs就达到了84.1%的Top1准确率。RMT-B也在类似FLOPs的情况下比iFormer增加了0.4%。此外,RMT-L模型在top1准确率上比MaxViT-B提升了0.6%,同时使用的FLOPs更少。RMT-T也在许多轻量级模型中表现突出。至于使用token标签训练的模型,RMT-S比当前最先进的BiFormer-S提高了0.5%。
目标检测与实例分割
结果表明,作者的RMT在所有比较中表现最佳。对于RetinaNet框架,RMT-T比MPViT-XS高出+1.3 AP,而S/B/L也在其他方法上表现更好。对于使用“1×”计划的Mask R-CNN,RMT-L比最近的InternImage-B高出+2.8 box AP和+1.9 mask AP。对于“3×+MS”计划,RMTS比InternImage-T高出+1.6 box AP和+1.2 mask AP。此外,关于Cascade Mask R-CNN,RMT仍然比其他骨干网络表现得更好。所有以上结果表明,RMT以明显的优势超越了其竞争对手。


语义分割
除了RMT-T(以512×512的分辨率测试)所有FLOPs都是以512×2048的分辨率测试的。所有的RMT模型在所有比较中都取得了最佳性能。具体来说,,RMT-S在Semantic FPN中比Shunted-S高出+1.2 mIoU。此外,RMT-B比最近的InternImage-S高出+1.8 mIoU。所有以上结果证明了RMT模型在密集预测方面的优越性。

消融实验
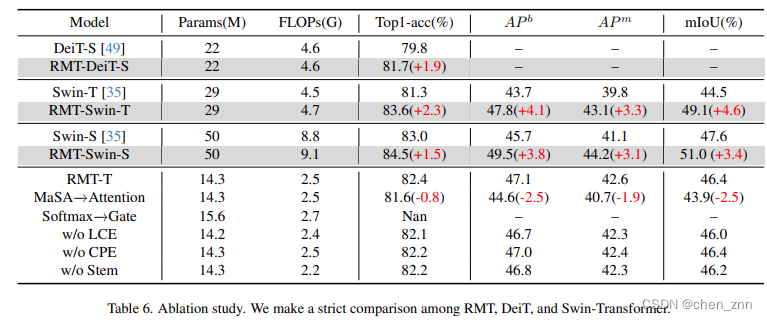

结论
在这项工作中,作者提出了RMT,这是一种具有显式空间先验的视觉骨干网络。RMT将用于NLP中因果建模的时间衰减扩展到空间层面,并引入了基于曼哈顿距离的空间衰减矩阵。该矩阵将显式的空间先验融入到自注意力机制中。此外,RMT采用了一种自注意力分解形式,能够在不破坏空间衰减矩阵的情况下稀疏地对全局信息进行建模。空间衰减矩阵和注意力分解形式的结合使RMT具备了显式的空间先验和线性复杂度。在图像分类、目标检测、实例分割和语义分割等多个视觉任务中的广泛实验验证了RMT的优越性。

