- 1【毕业设计】Java开发环境搭建-看这篇就够了_java开发环境的搭建步骤
- 2IDEA便捷开发之生成对象所有set方法插件---GenerateAllSetter_idea 输出类的所有set
- 3postgresql数据库允许某些网段内远程访问_pg数据库设置访问连接网段区间
- 4VSCode 插件_prettier不把大写字母改成小写
- 5【Leetcode】261. Graph Valid Tree_leetcode 261
- 6C++——cmath_c++ cmath
- 7人工智能OCR领域安全应用措施_ocr技术 涉密信息流向控制
- 8深度学习(五十六)tensorflow项目构建流程_tensorflow各种框架搭建
- 9蓝桥杯_显然,这些数字串都仅包含 1, 2, 4, 6 这四个数字。 输入整数 n 和数字串 s,请你求
- 10根据身份证号码前14位计算全部有效后四位_身份证号码有前14位 如何根据性别 随机生成一个后四位,且符合身份证校验逻辑
Megatron-LM源码系列(一): 模型并行初始化_megatron-lm 源码
赞
踩
在本系列中,我们将探讨Megatron-LM的源代码。Megatron-LM是由Nvidia开发的一个大规模语言模型训练框架,它采用模型并行的方式实现分布式训练。在本篇文章中,我们将关注模型并行初始化的过程。
1. pretrain
在Megatron中pretrain函数是框架执行的入口,定义在megatron/training.py文件中。
def pretrain(train_valid_test_dataset_provider,
model_provider,
model_type,
forward_step_func,
process_non_loss_data_func=None,
extra_args_provider=None,
args_defaults={}):
...
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
以gpt训练为例,在pretrain_gpt.py中使用如下:
if __name__ == "__main__":
pretrain(train_valid_test_datasets_provider,
model_provider,
ModelType.encoder_or_decoder,
forward_step,
args_defaults={'tokenizer_type': 'GPT2BPETokenizer'})
- 1
- 2
- 3
- 4
- 5
- 6
Pretrain训练的流程分为四步:
- 初始化Megatron
initialize_megatron(extra_args_provider=extra_args_provider,
args_defaults=args_defaults)
- 1
- 2
- 使用
model_provider设置model、optimizert和lr schedule
model, optimizer, opt_param_scheduler = setup_model_and_optimizer(
model_provider, model_type)
- 1
- 2
- 使用
train_val_test_data_provider获取train/val/test数据集
train_data_iterator, valid_data_iterator, test_data_iterator \
= build_train_valid_test_data_iterators(
train_valid_test_dataset_provider)
- 1
- 2
- 3
- 使用
forward_step_func去训练模型
iteration = train(forward_step_func,
model, optimizer, opt_param_scheduler,
train_data_iterator, valid_data_iterator,
process_non_loss_data_func)
- 1
- 2
- 3
- 4
2. initialize_megatron
initialize_megatron 初始化定义在文件 megatron/initialize.py中。初始化分为3步:mpu初始化、autoresume自动恢复初始化、依赖编译。
mpu全称是model parallelism unit,定义在megatron/core/__init__.py中,mpu = parallel_state。
# Megatron's MPU is the master. Complete initialization right away.
finish_mpu_init()
# Autoresume.
_init_autoresume()
# Compile dependencies.
_compile_dependencies()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
3. _initialize_distributed
- 先设置当前cuda device,并调用init_process_group
if args.rank == 0: print('> initializing torch distributed ...', flush=True) # Manually set the device ids. if device_count > 0: device = args.rank % device_count if args.local_rank is not None: assert args.local_rank == device, \ 'expected local-rank to be the same as rank % device-count.' else: args.local_rank = device torch.cuda.set_device(device) # Call the init process torch.distributed.init_process_group( backend=args.distributed_backend, world_size=args.world_size, rank=args.rank, timeout=timedelta(minutes=args.distributed_timeout_minutes))

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 进行模型并行的初始化
args.pipeline_model_parallel_size,
args.virtual_pipeline_model_parallel_size,
args.pipeline_model_parallel_split_rank)
- 1
- 2
- 3
4. initialize_model_parallel
4.1 基本概念
-
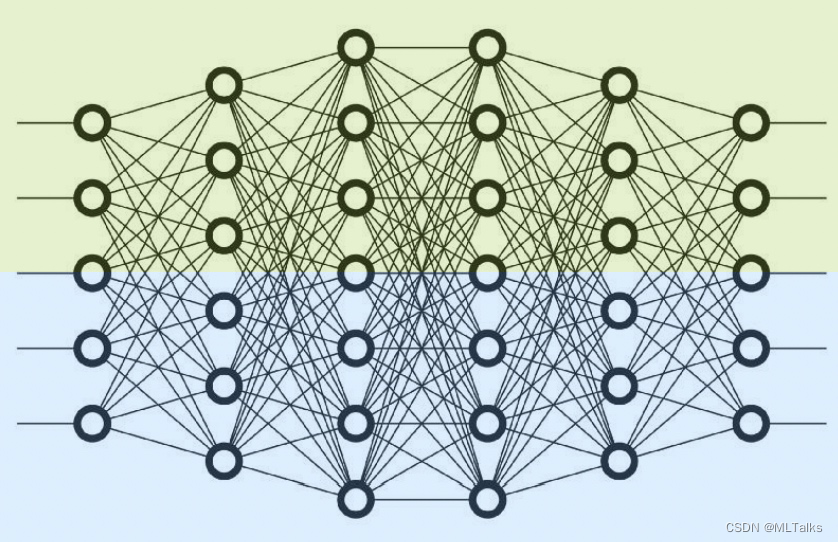
Tensor并行,也称为层内并行(Tensor/Intra-Layer Parallelism)。如下图,没有使用pipeline并行的情况下,tensor并行度设为2,表示每层layer都会被横向切成两部分,每部分会分别被不同的device处理。例如以单机8卡为例,tensor并行度设为2,总共会分为4组tensor并行组,每一组都会保存一份完整的网络,每组会各有两卡GPU,每张GPU卡处理所有网络层的一半。对应可以进行的数据并行度也就是4。
-
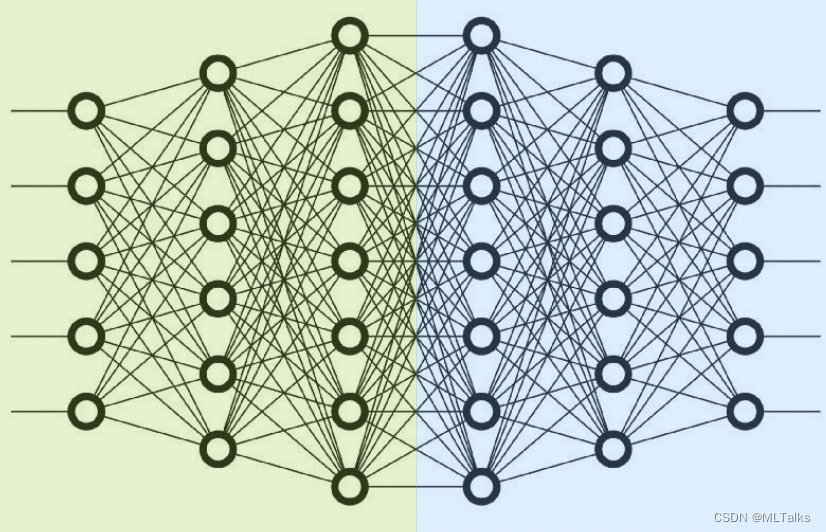
Pipeline并行,也称为层间并行(Pipeline/Inter-Layer Parallelism)。如下图,没有使用tensor并行的情况下,pipeline并行度设为2,表示网络的所有layer会被分为两组(纵向切),每组layer会和由一个device进行处理。例如以单机8卡为例,pipeline并行度设为2,总共会分为4组pipeline并行组,每一组都会保存一份完整的网络,每组会各有两卡GPU,每张GPU卡处理一半的网络。对应可以进行的数据并行度也就是4。
-
在
Megatron-LM中Pipeline并行支持阶段穿插调度(interleaved stage schedule), 流水线分为多个stage的时候,每个device会处理多个流水线中的stage。例如每连续的4个layer是做为pipeline的一个stage,每个device处理4个layer的话,之前流水线做法是device顺序划分处理pipeline stage,device1支持stage1(layer[1/2/3/4]),device2支持stage2([layer5/6/7/8]),device3支持stage3([layer9/10/11/12]), 以此类推; 现在流水线处理是间隔处理,每个device处理涉及两个stage,device1支持[layer1/2/9/10],device2支持[layer3/4/11/12], 以此类推。 -
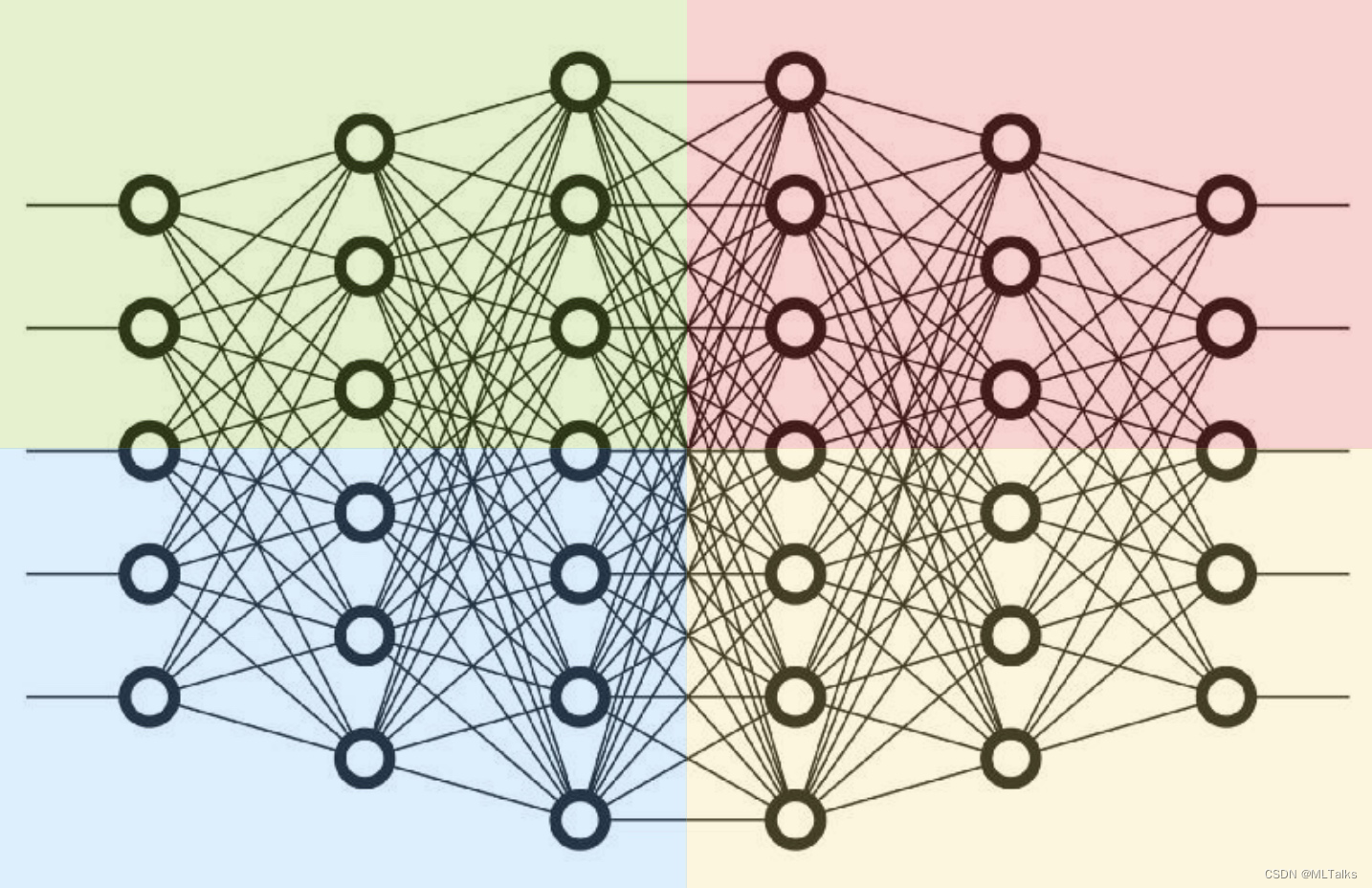
Tensor并行+Pipeline并行混合并行。如下图,当同时设置了pipeline并行度为2,tensor并行度为2,表示一个网络先被纵向为左右两部分(也就是pipeline并行),然后每一部分被横向切开,被应用上2块gpu卡的tensor并行,总体上来看一个网络总共会被( p i p e l i n e 并行度 × t e n s o r 并行度 = 4 pipeline并行度 \times tensor并行度 = 4 pipeline并行度×tensor并行度=4 )块gpu卡处理。例如以单机8卡为例,在pipeline并行度为2且tensor并行度为2的情况下,可以同时保存2份相同的网络,对应可以进行的数据并行度等同于2( $ total_cards_num \div 4 = 2$ )。
4.2 initialize_model_parallel函数定义
initialize_model_parallel是模型初始化的重点,定义在megatron/core/parallel_state.py
def initialize_model_parallel(
tensor_model_parallel_size: int = 1,
pipeline_model_parallel_size: int = 1,
virtual_pipeline_model_parallel_size: Optional[int] = None,
pipeline_model_parallel_split_rank: Optional[int] = None,
use_fp8: bool = False,
) -> None:
...
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
先看下传入参数定义:
-
tensor_model_parallel_size(必选,默认为1): 每个tensor并行组中的GPU卡数,默认为1
-
pipeline_model_parallel_size(必选,默认为1): 表示一个pipeline模型并行通信组中的GPU卡数,pipeline并行相当于把layer纵向切为了N个stage阶段,每个阶段对应一个卡,所以这里也就等于stage阶段数。例如
pipeline_model_parallel_size为2,tensor_model_parallel_size为4,表示一个模型会被纵向分为2个stage进行pipeline并行,每个组(stage)内会对应有一个tensor并行组进行4卡gpu的tensor并行。如下图分为2个阶段,每个阶段按列[g0, g1, g2, g3]和[g4, g5, g6, g7]分别对应两个tensor并行通信组; 按行分别有4个pipeline并行通信组,通信方向是从阶段一到阶段二,分别是[g0->g4], [g1->g5], [g2->g6], [g3->g7]阶段一 阶段二 g0 g4 g1 g5 g2 g6 g3 g7 -
virtual_pipeline_model_parallel_size(可选,默认为None): 为了支持
interleaved schedule,例如在一个模型网络中有16层transformer, 设置【tensor_model_parallel_size=1, pipeline_model_parallel_size=4, virtual_pipeline_model_parallel_size=2】,一个完整的模型会由【pipeline_model_parallel_size * tensor_model_parallel_size = 4】张gpu卡进行处理,模型运行会被分为4*2=8个stage,每个tensor并行组(这里一个组里只有一张卡)对应处理两个stage。virtual_pipeline_model_parallel_size也就是对应一张卡上处理的stage个数。 -
pipeline_model_parallel_split_rank(可选,默认为None):针对encoder-decoder模型结构,用于区分,例如
tensor_model_parallel_size=1, pipeline_model_parallel_size=8对有8个stage的pipeline, 每个stage对应有一张卡,pipeline_model_parallel_split_rank=3表示rank0-2的4张卡属于encoder,rank3-7的4张卡属于decoder。 -
use_fp8(默认为False): 使用FP8训练
在initialize_model_parallel中会进行5种类型的分组:
- data parallel,对应变量
_DATA_PARALLEL_GROUP - model parallel,对应变量
_MODEL_PARALLEL_GROUP - tensor model parallel,对应变量
_TENSOR_MODEL_PARALLEL_GROUP - pipeline model parallel,对应变量
_PIPELINE_MODEL_PARALLEL_GROUP - embedding groups,对应变量
_EMBEDDING_GROUP
4.3 data parallel数据并行通信组初始化
数据并行度data_parallel_size是自动算出来的, 表示总共有data_parallel_size个模型可以同时训练。
data_parallel_size: int = world_size // (tensor_model_parallel_size * pipeline_model_parallel_size)
- 1
通信初始化先以pipeline_model_parallel_size(表示pipeline并行的stage个数/tensor并行组的个数)为外循环,以tensor_model_parallel_size为内循环(表示一个tensor并行组内gpu卡的个数), 并按tensor_model_parallel_size大小为间隔来创建通信组。
data_parallel_size: int = world_size // (tensor_model_parallel_size *
pipeline_model_parallel_size)
......
# Build the data-parallel groups.
all_data_parallel_group_ranks = []
for i in range(pipeline_model_parallel_size):
start_rank = i * num_pipeline_model_parallel_groups
end_rank = (i + 1) * num_pipeline_model_parallel_groups
for j in range(tensor_model_parallel_size):
ranks = range(start_rank + j, end_rank, tensor_model_parallel_size)
all_data_parallel_group_ranks.append(list(ranks))
group = torch.distributed.new_group(ranks)
if rank in ranks:
_DATA_PARALLEL_GROUP = group
_DATA_PARALLEL_GLOBAL_RANKS = ranks
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
以两机共16卡(2台gpu机器,每个机器8卡,以g0 ... g15表示16块gpu卡)为例,当tensor_model_parallel_size=2, pipeline_model_parallel_size=4时, data_parallel_size等于16/(2*4)=2。all_data_parallel_group_ranks数据并行通信组对应为 [g0, g2], [g1, g3], [g4, g6], [g5, g7], [g8, g10], [g9, g11], [g12, g14], [g13, g15]

从机器视角来看如下图,
g
n
g_n
gn 表示一张卡,卡与卡之间的连线表示在同一个通信组中:
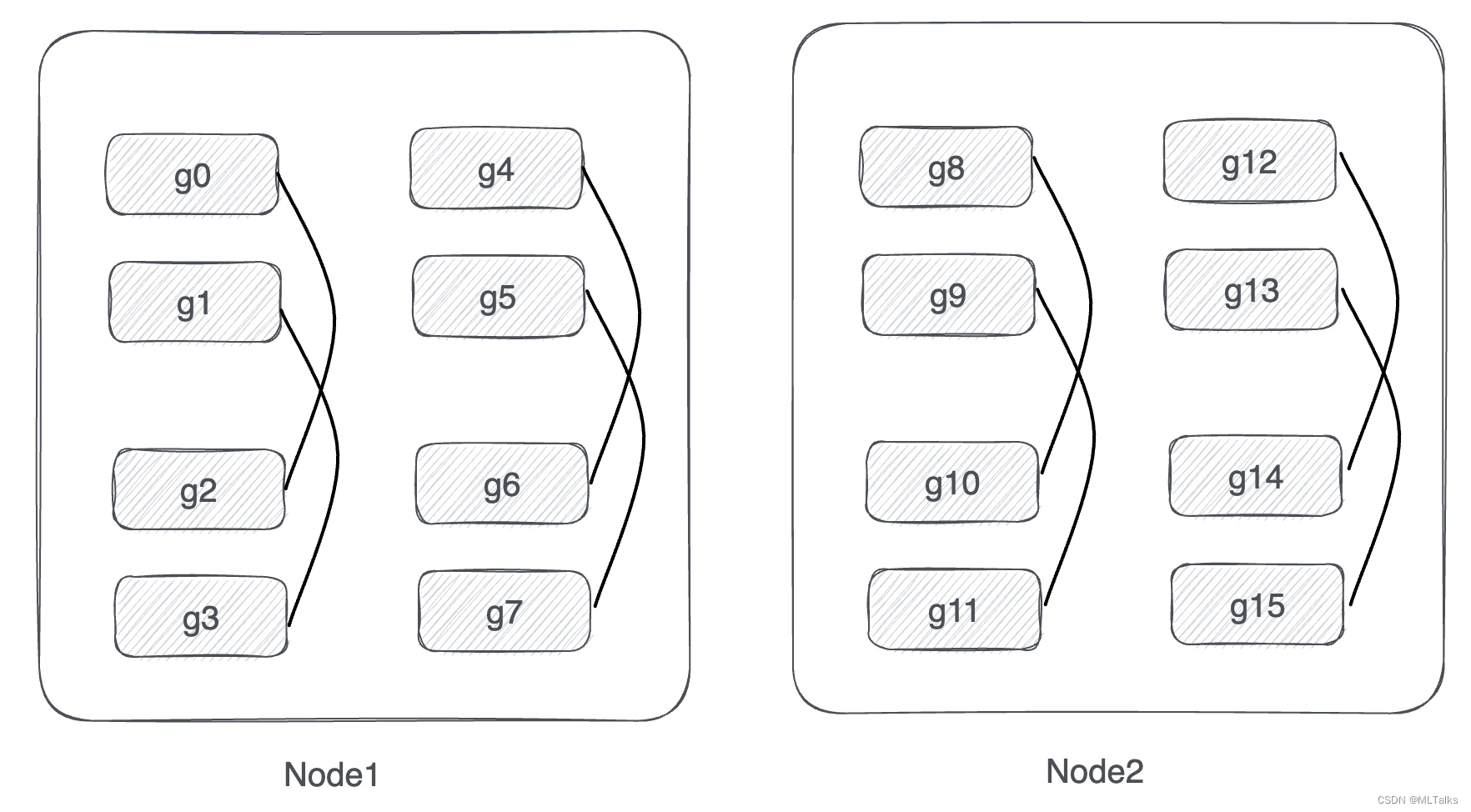
4.4 model parallel模型并行通信组初始化
这里的模型并行通信组相当于同时包含了tensor模型并行组和pipeline模型并行组(不区分是tensor还是pipeline),也就是对应包含训练整个模型的所有gpu卡的通信组,组的个数对应数据并行的data_parallel_size,组内卡的个数对应tensor_model_parallel_size * pipeline_model_parallel_size。代码如下:
# Build the model-parallel groups.
global _MODEL_PARALLEL_GROUP
assert _MODEL_PARALLEL_GROUP is None, 'model parallel group is already initialized'
for i in range(data_parallel_size):
ranks = [data_parallel_group_ranks[i]
for data_parallel_group_ranks in all_data_parallel_group_ranks]
group = torch.distributed.new_group(ranks)
if rank in ranks:
_MODEL_PARALLEL_GROUP = group
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
以两机共16卡(2台gpu机器,每个机器8卡,以g0 ... g15表示16块gpu卡)为例,当tensor_model_parallel_size=2, pipeline_model_parallel_size=4时, data_parallel_size等于16/(2*4)=2,模型并行通信组也是2个。基于all_data_parallel_group_ranks分组中来得到模型并行通信组,结果为[g0, g1, g4, g5, g8, g9, g12, g13]和[g2, g3, g6, g7, g10, g11, g14, g15]。
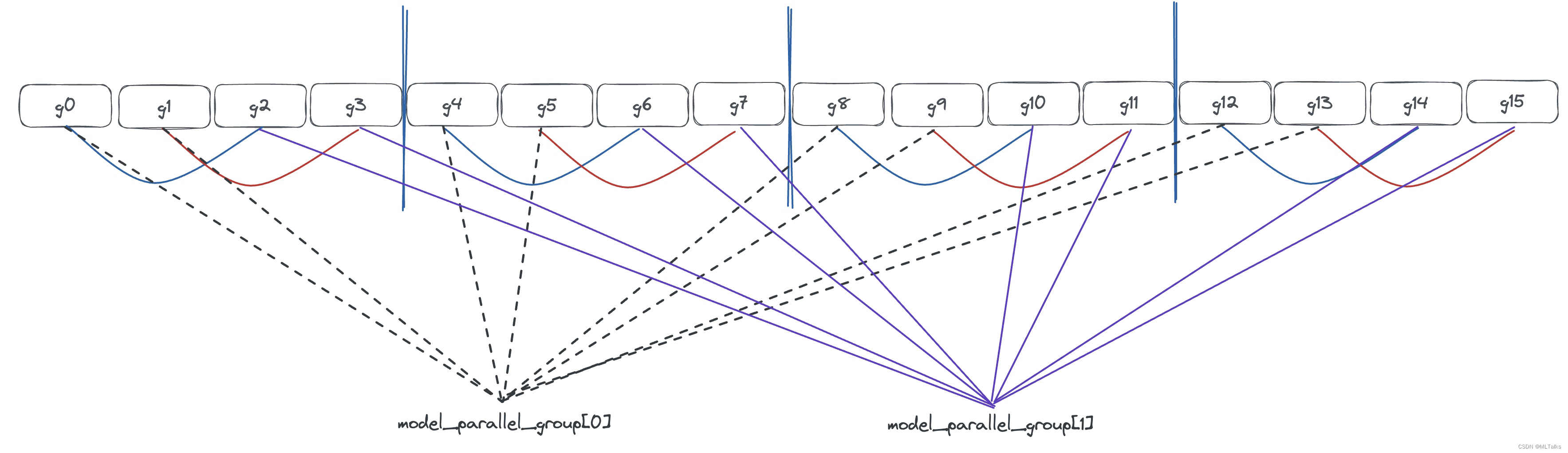
从机器视角来看数据并行如下图,黄色和绿色的块表示整体模型并行的通信组,每个通信组中有8张卡,每组各负责训练一个完整的模型,数据同时分发给两块:
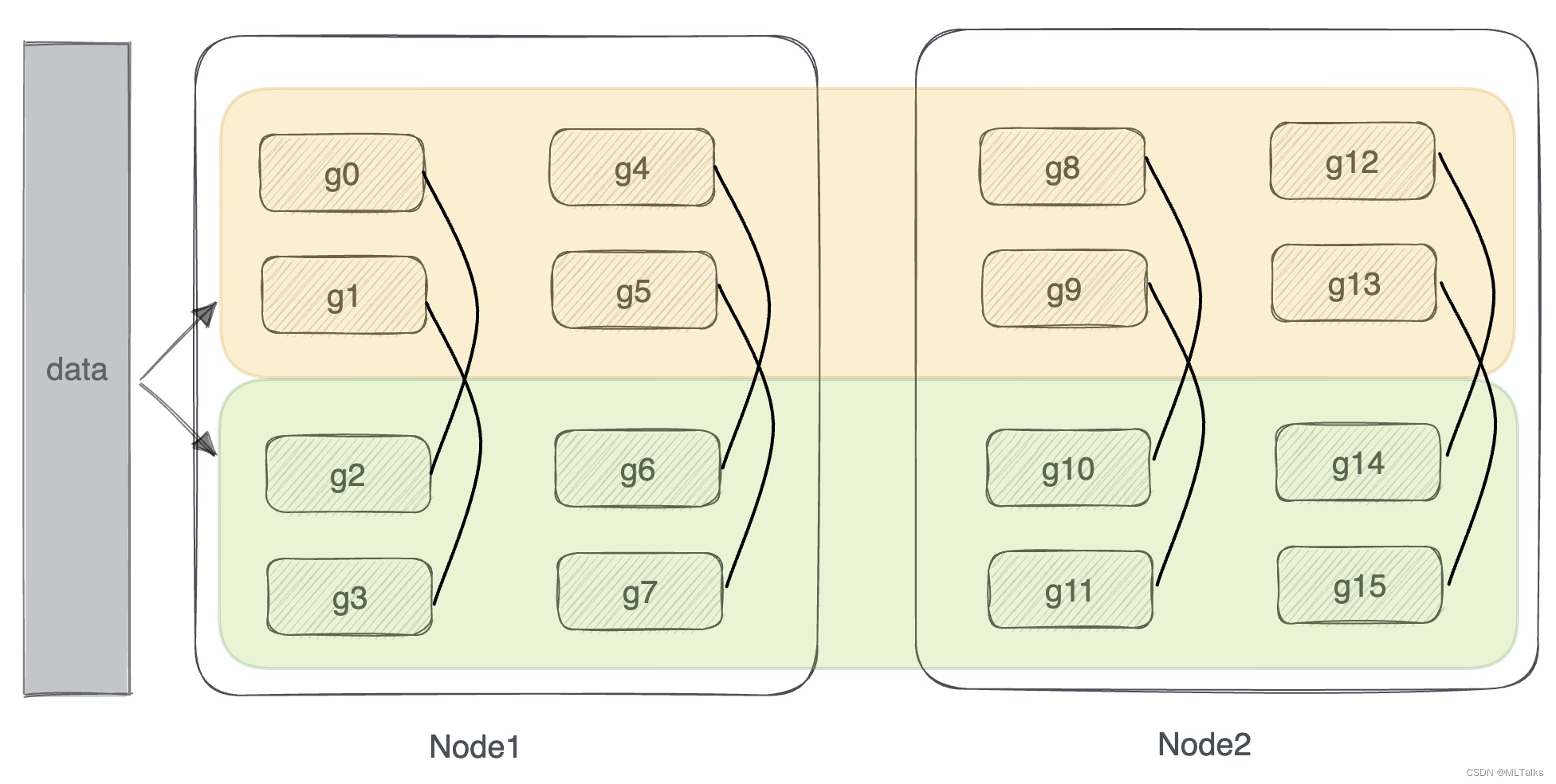
4.5 tensor model parallel通信组初始化
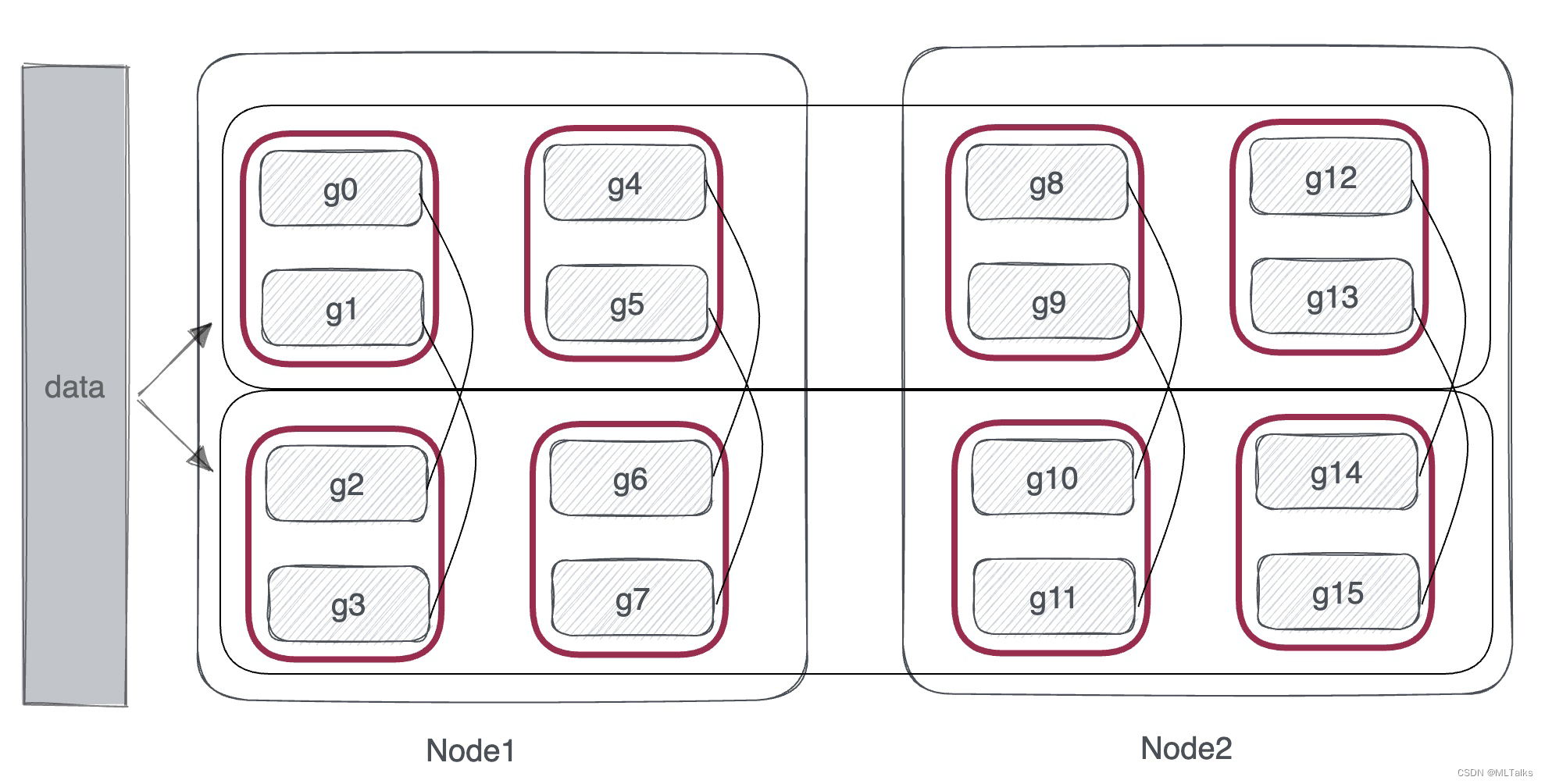
tensor模型并行组内gpu卡数由tensor_model_parallel_size来指定。以两机共16卡(2台gpu机器,每个机器8卡)为例,tensor_model_parallel_size=2, pipeline_model_parallel_size=4情况下,tensor并行通信组创建按顺序来取,即为 [g0, g1], [g2, g3], [g4, g5], [g6, g7], [g8, g9], [g10, g11], [g12, g13], [g14, g15]。代码如下:
# Build the tensor model-parallel groups.
global _TENSOR_MODEL_PARALLEL_GROUP
assert _TENSOR_MODEL_PARALLEL_GROUP is None, \
'tensor model parallel group is already initialized'
for i in range(num_tensor_model_parallel_groups):
ranks = range(i * tensor_model_parallel_size,
(i + 1) * tensor_model_parallel_size)
group = torch.distributed.new_group(ranks)
if rank in ranks:
_TENSOR_MODEL_PARALLEL_GROUP = group
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
从机器视角来看数据并行如下图, 每一个红色框相当于一个tensor并行通信组:
4.6 pipeline model parallel通信组初始化
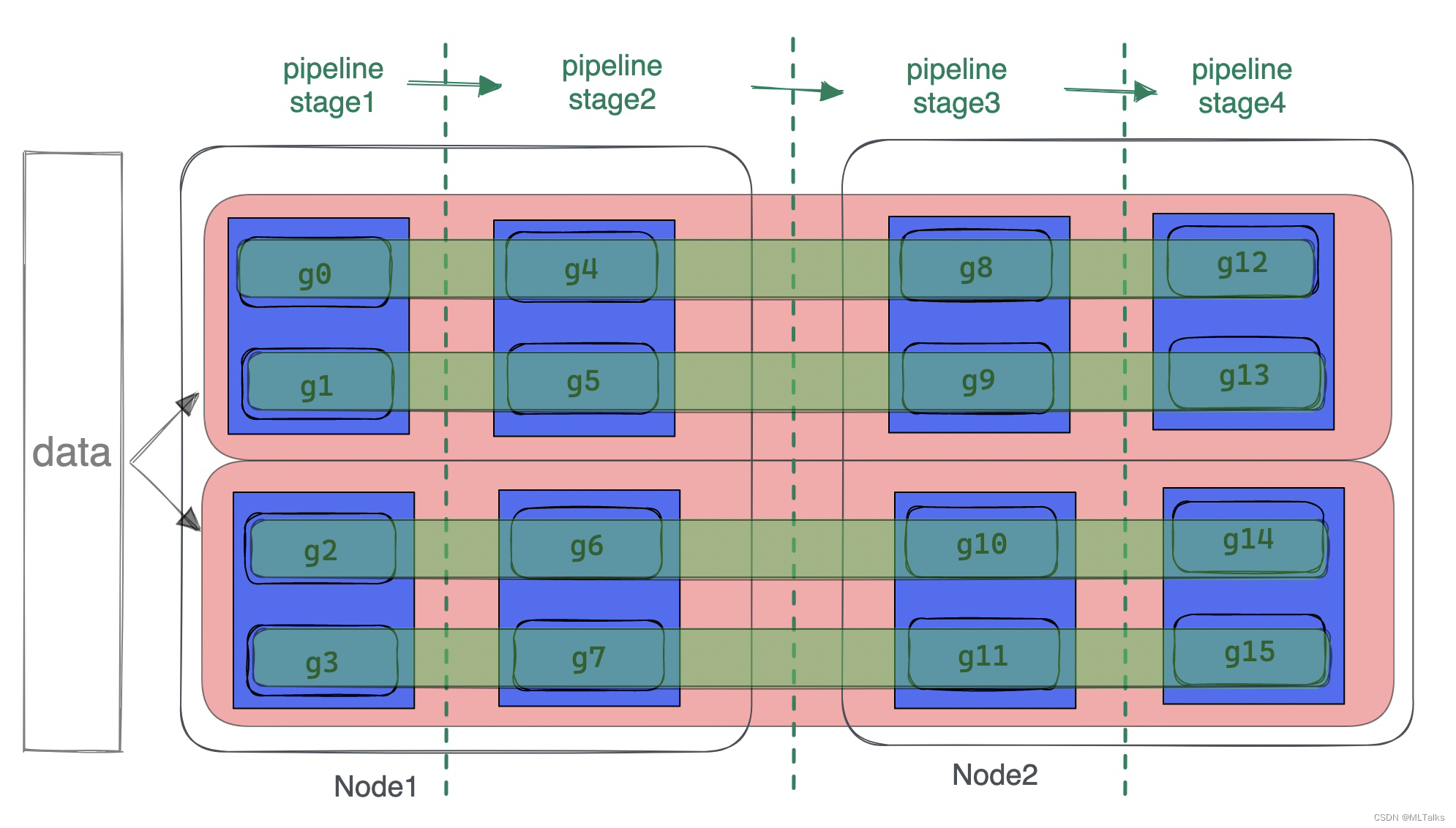
pipeline模型并行pipeline_model_parallel_size来指定, 有。以两机共16卡(2台gpu机器,每个机器8卡)为例,tensor_model_parallel_size=2, pipeline_model_parallel_size=4情况下,表示一个模型训练过程会被分为4个stage(每个stage对应一个tensor并行组)。流水线并行分组按parallel_groups的个数为间隔来取,即为 [g0, g4, g8, g12], [g1, g5, g9, g13], [g2, g6, g10, g14], [g3, g7, g11, g15]。
for i in range(num_pipeline_model_parallel_groups):
ranks = range(i, world_size, num_pipeline_model_parallel_groups)
group = torch.distributed.new_group(ranks)
if rank in ranks:
_PIPELINE_MODEL_PARALLEL_GROUP = group
_PIPELINE_GLOBAL_RANKS = ranks
- 1
- 2
- 3
- 4
- 5
- 6
从机器视角来看pipeline并行如下图, 每一大列都是pipeline中的一个stage,stage的处理是从左往右依次进行,为了解决不同stage的通信,所以需要创建四个通信组(每个色块表示一个通信组):
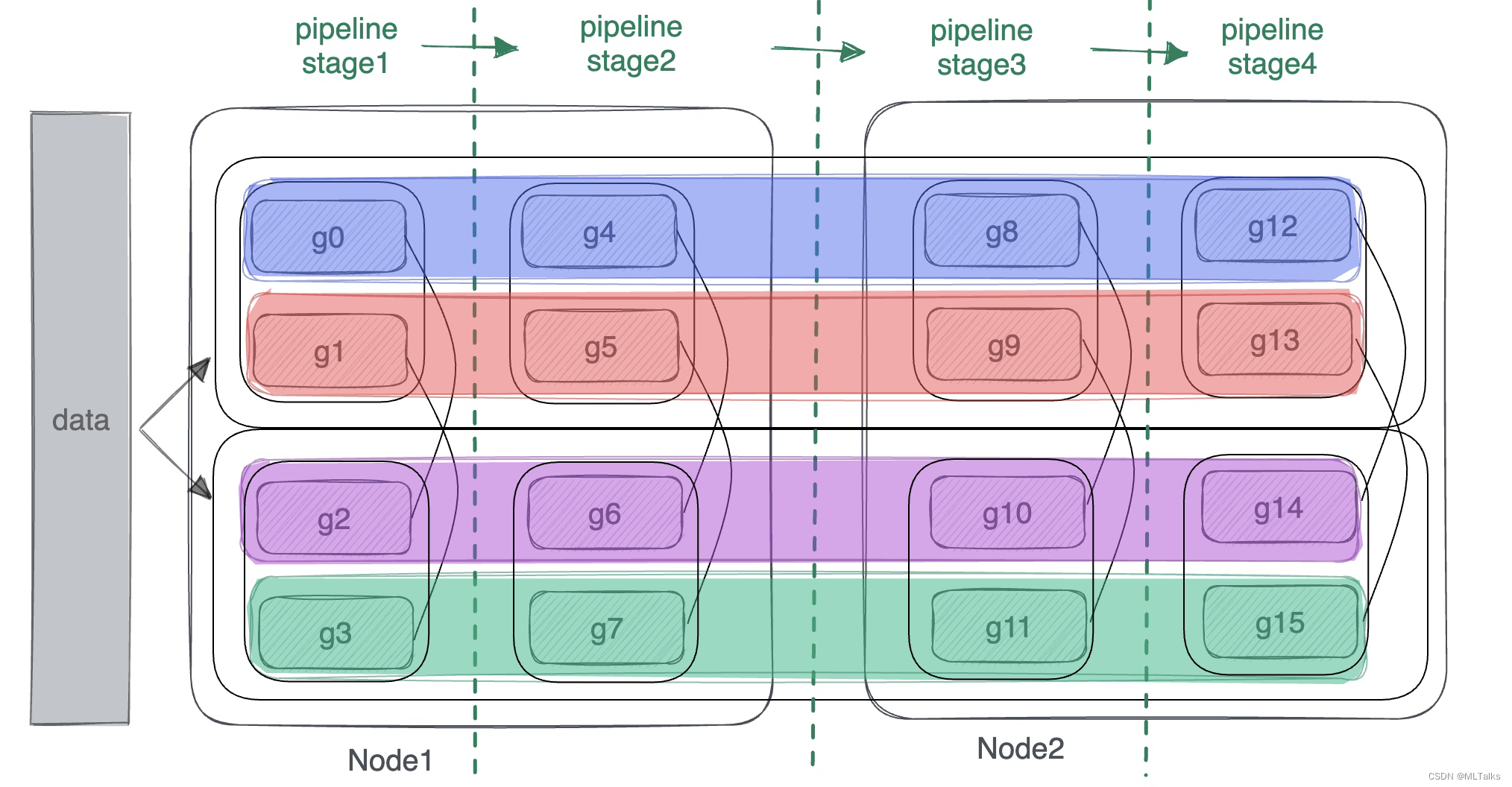
通信时上下游用到的rank号获取通过如下方法获取:
def get_pipeline_model_parallel_next_rank(): """Return the global rank that follows the caller in the pipeline""" assert _PIPELINE_GLOBAL_RANKS is not None, \ "Pipeline parallel group is not initialized" rank_in_pipeline = get_pipeline_model_parallel_rank() world_size = get_pipeline_model_parallel_world_size() return _PIPELINE_GLOBAL_RANKS[(rank_in_pipeline + 1) % world_size] def get_pipeline_model_parallel_prev_rank(): """Return the global rank that preceeds the caller in the pipeline""" assert _PIPELINE_GLOBAL_RANKS is not None, \ "Pipeline parallel group is not initialized" rank_in_pipeline = get_pipeline_model_parallel_rank() world_size = get_pipeline_model_parallel_world_size() return _PIPELINE_GLOBAL_RANKS[(rank_in_pipeline - 1) % world_size]
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
4.7 汇总说明如下
以两机共16卡(2台gpu机器,每个机器8卡)为例,tensor_model_parallel_size=2, pipeline_model_parallel_size=4情况下。如下图, 蓝色表示8个tensor并行组,每个组内有2张卡(tensor_model_parallel_size=2);绿色表示4个pipeline并行组,每个组内有4张卡(pipeline_model_parallel_size=4);红色表示两个数据并行组,每个组内有8张卡;从模型切分的粒度从小到大来说,tensor并行(tensor分组) < pipeline并行(layer分组) < 数据并行(整个模型复制)