
- 1hive修改schema的location_hive location alter
- 2【随记】元学习
- 3uniapp项目实战+springboot的知识分享学习头条App[源码+文档+答疑+远程_uniapp小程序项目头条
- 4分布式计算概述_分布式计算是如何把一个任务分成许多小的部分
- 5内网渗透-smb&wmi_wmi渗透
- 6大数据最全深度学习(五)—— 卷积神经网络(CNN(3),2024年最新面试大数据开发卡顿_卷积神经网络数据集处理
- 7C语言字符串库常用函数_c语言 字符串长度 指定编码 计算函数
- 8程序员被公司辞退12天,前领导要求回公司讲清楚代码,结果蒙了_代码看不懂是否还和离职员工有关系
- 9Android 13 SystemUI 屏蔽导航栏;屏蔽锁屏;隐藏状态栏;禁止状态栏下拉;屏蔽Camera绿色图标;屏蔽原生音量条;屏蔽原生亮度条。_android 隐藏状态栏
- 10华为OD机试Js - 根据IP查找城市_某业务需要根据终端的ip地址获取该终端归属的城市,可以根据公开的ip地址池信息查
【Text2SQL 经典模型】TypeSQL
赞
踩
论文:TypeSQL: Knowledge-Based Type-Aware Neural Text-to-SQL Generation
⭐⭐⭐
Code: TypeSQL | GitHub
一、论文速读
本论文是在 SQLNet 网络上做的改进,其思路也是先预先构建一个 SQL sketch,然后再填充 slots 从而生成 SQL。
论文发现:在 question 中往往包含与特定数据相关的 rare entity 和 number,这对于在 SQL 查询中推断 column name 和 WHERE condition value 很重要,但这些 entity 和 number 缺乏准确的 embedding。为了解决这个问题,本工作为 question 的每个 word 分配了一个 type:知识图谱中的 entity、“COLUMN” 或者一个 number,如下图的最下面的 input 所示,为 question 的每个 word 都分配了一个 type:
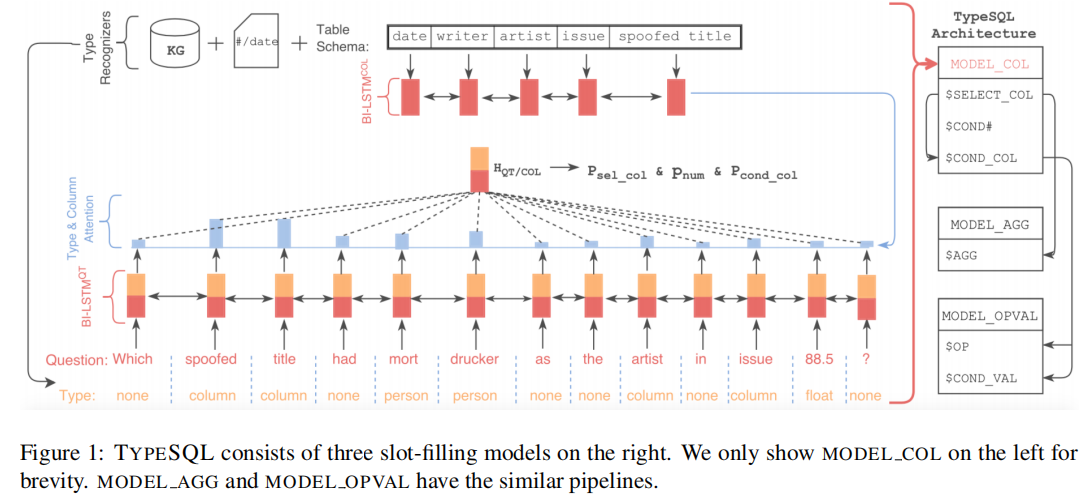
具体来说,首先对 question 做分词,切分成长度为 2~6 的 n-grams,然后:
- 使用 gram 检索数据库的 table schema,如果能检索到相应的 column name,那就将其 type 标注为
COLUMN - 为 number 和 date 标注为以下四个类别之一:
INTEGER、FLOAR、DARE、YEAR - 为了识别命名实体,用 gram 作为 keyword 在 Freebase 上做检索五类实体:
PERSON、PLACE、COUNTRY、ORGANIZATION、SPORT,并做相应的 type 标注,这五类实体已经可以覆盖了数据集中的绝大多数实体
由此,我们才可以看到上图中对 question 的 type 标注结果。
拓展来开的话,如果 database 的内容也可以访问,那我们在做 type 标注时,还会将 gram 从 table schema、column content 和 column label 中做检索,并将 type 标注为具体的 column name。比如上图中,question 中的 mort drucker 可以被标注为 artist,因为我们能在数据库中检索到这个 gram 并发现对应的 column name 为 artist。
对 question 做完 type 标注后,在之后做编码时,就可以将 question 中的原 token 和对应的 type 一起做 embedding,并将两个 embedding 连接在一起做 encode 并进一步处理。
在之后填充 SQL sketch 做 slots 预测时,原来的 SQLNet 模型是为五种 slots 设计了五个 model 来分别训练和预测,而本文的 TypeSQL 将其中功能相似的 model 做了合并,最终只需要 3 个 model 来完成填充任务,架构上做了简化。具体公式可以参考原论文。
二、总结
这篇论文的工作主要是对 SQLNet 做的改进,改进主要有如下:
- 借助于数据库的 table schema 检索和 knowledge graph 的检索,为 question 的每个 word 标注一个 type,从而提高 embedding 的效果
- 当 database content 可用时,type 标注时还会进一步对 column content 做检索,并为其标注 column name,这样当用户的 question 中的所提到的列名或者条目不精确时,也可以通过这个步骤来对应到具体的数据库 column,从而提高效果,实现所谓的“内容敏感性”。
- 改进了 SQLNet 的 slots 填充步骤,减少了所需要的 model 数量,架构上也做了简化

