
热门标签
热门文章
- 1CV2的conda安装_cv2 conda
- 2ROS小车(SLAM+物体追踪)_视觉slam 智能车循迹
- 3【独家OD2023C卷真题】20天拿下华为OD笔试【DFS/BFS】2023C-地图寻宝【欧弟算法】全网注释最详细分类最全的华为OD真题题解_小华按照地图去寻宝,地图上被划分成
- 4网站localhost和127.0.0.1可以访问,本地ip不可访问解决方案_本机ip访问不了,只能用localhost
- 5boss直聘改回系统头像_Boss直聘CEO回应“求职少年之死”:之前没做好,愧对当事人...
- 6使用Python进行大数据处理和分析:Hadoop和Spark
- 7Wireshark抓包分析TCP协议:三次握手和四次挥手_捕获tcp数据包并分析,包括三次握手,四次挥手等
- 8docker使用示例_docker应用实例
- 9UNITY动画播放暂停_unity 动画在某一帧暂停
- 10please declare environment variable 'SUMO_HOME'
当前位置: article > 正文
LLama学习记录
作者:花生_TL007 | 2024-05-30 20:55:33
赞
踩
LLama学习记录
学习前:
五大问题:
- 为什么SwiGLU激活函数能够提升模型性能?
- RoPE位置编码是什么?怎么用的?还有哪些位置编码方式?
GQA(Grouped-Query Attention, GQA)分组查询注意力机制是什么?- Pre-normalization前置了层归一化,使用
RMSNorm作为层归一化方法,这是什么意思?还有哪些归一化方法?LayerNorm? - 将self-attention改进为使用
KV-Cache的Grouped Query,怎么实现的?原理是什么?
Embedding
Embedding的过程:word -> token_id -> embedding_vector,其中第一步转化使用tokenizer的词表进行,第二步转化使用 learnable 的 Embedding layer。
这里的第二步,不是很明白怎么实现的,需要再细化验证

RMS Norm
对比Batch Norm 和 Layer Norm:都是减去均值Mean,除以方差Var(还加有一个极小值),最终将归一化为正态分布N(0,1)。只不过两者是在不同的维度(batch还是feature)求均值和方差,(其中,减均值:re-centering 将均值mean变换为0,除方差:re-scaling将方差varance变换为1)。
RoPE(Rotary Positional Encodding)
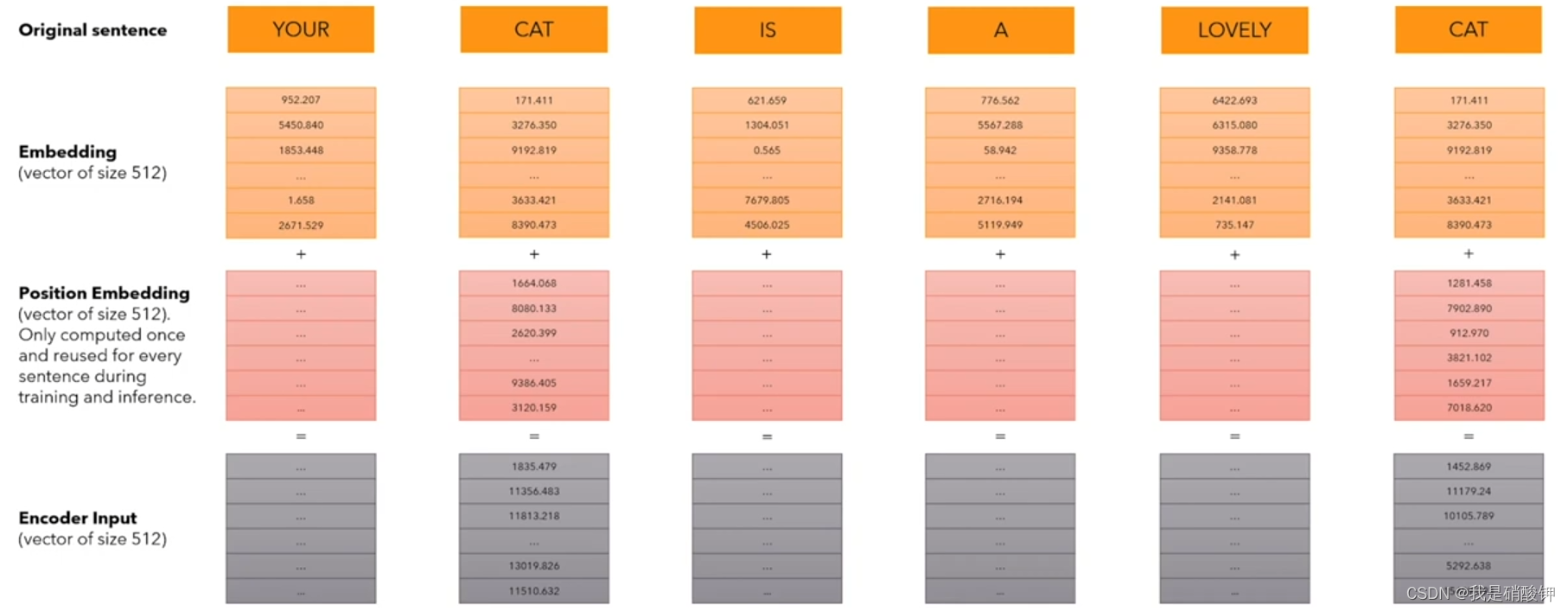
绝对Positional Encodding的使用过程:word -> token_id -> embedding_vector + position_encodding -> Encoder_Input,其中第一步转化使用tokenizer的词表进行,第二步转化使用 learnable 的 Embedding layer。将得到的embedding_vector 和 position_encodding 进行element-wise的相加,然后才做为input送入LLM的encoder。
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/花生_TL007/article/detail/648571
推荐阅读
相关标签

