
热门标签
热门文章
- 1官宣正式成为 PostgreSQL Contributor,Richard 有何秘诀?
- 2[Go]三、最简单的RestFul API服务器_go 简单的api
- 3AIGC技术的现状与未来发展趋势_aigc目前现状
- 4Fiddler抓包工具应用_安卓抓包工具fiddler
- 5一些易被忽视且难度较高的Web前端面试题汇总_前端面试超难
- 6web测试用例_点击当前用例显示子用例
- 7Numpy学习之np.argsort()函数
- 8mac安装暴雪战网卡在45%的解决方法_mac战网安装程序卡在45%
- 9Git push 时如何避免出现 Merge branch 'master' of xxx
- 10php 截取图片 透明背景且超出后无黑边_php 图片透明背景设置
当前位置: article > 正文
Hadoop伪分布式的搭建_hadoop伪分布式运行环境副本数量设置为几个
作者:我家自动化 | 2024-05-31 07:38:20
赞
踩
hadoop伪分布式运行环境副本数量设置为几个
伪分布式:并不是真正的分布式,是将多台机器的任务放到一台机器上运行
一、安装jdk
1. 解压安装包
tar -zxvf jdk-8u161-linux-x64.tar.gz
- 1
2. 配置jdk环境变量
export JAVA_HOME=/home/java/jdk1.8.0_161
export JRE_HOME=${JAVA_HOME}/jre
export CLASSPATH=.:${JAVA_HOME}/lib/dt.jar:${JAVA_HOME}/lib/tools.jar
export PATH=${JAVA_HOME}/bin:$PATH
- 1
- 2
- 3
- 4
3. 检验是否安装成功
输入java -version

出现上述图片即可
二、安装Hadoop及配置文件
1. 解压安装包
tar -zxvf hadoop-2.7.1_64bit.tar.gz
- 1
在解压完的安装包里创建俩个目录
创建存储临时文件的目录mkdir tmp
创建日志目录mkdir logs

2. 配置hadoop环境变量
export HADOOP_HOME=/home/hadoop/hadoop-2.7.1
export PATH=.:$HADOOP_HOME/bin:$JAVA_HOME/bin:$PATH
- 1
- 2
- 输入
hadoop version验证是否安装成功

3. 配置hadoop-env.sh

这里是刚才JDK的安装路径
4. 配置core.site.xml
- 第一个属性用来指定HDFS老大得地址,也就是NameNode的地址
value值是主机名加端口号,如果在host文件中添加了主机名和ip映射,主机名也可以用ip地址替换 - 第二个属性用来指定hadoop运行时产生临时文件的路径
<property>
<name>fs.defaultFS</name>
<value>hdfs://master:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/home/hadoop/hadoop-2.7.1/tmp</value>
</property>
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
5. 配置hdfs.site.xml
- 指定hdfs保存数据的副本数量,如果是2,总共有2份,因为是伪分布式,所以是1
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
- 1
- 2
- 3
- 4
6. 配置mapred-site.xml文件
- 如果没有mapred-site.xml,可以使用命令将mapred-site.xml.template 重命名
mv mapred-site.xml.template mapred-site.xml
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
- 1
- 2
- 3
- 4
- 这是指定mapreduce使用yarn框架
7. 配置yarn.site.xml文件
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>master</value>
</property>
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 第一个告诉nodemanager获取数据的方式为shuffle
- 第二个指定yarn的老大Resourcemanagger的地址
8. 格式化
1.在bin目录下输入hadoop namenode -format
三、启动集群
- 在sbin目录上输入
start-all.sh启动集群 - 在sbin目录上输入
stop-all.sh关闭集群
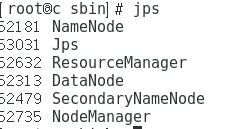
- 出现上面的则启动成功
- 在浏览器输入http://主机IP:50070和 http://主机IP:8088是否访问,如果可以访问则安装成功


声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/我家自动化/article/detail/651139
推荐阅读

相关标签

