
- 1Flink 内核原理与实现-状态原理_flink state实现
- 2gerrit submit撤回_Gerrit使用篇-提交代码,合并代码
- 3关系抽取(三)实体关系联合抽取:CasRel_最新的实体关系抽取工具
- 4webpack-theme-color-replacer自定义element-ui主题
- 5【Unity】天气特效:打雷下雨_unity落雷特效制作
- 6Cognex VisionPro连接USB相机的两种品牌
- 7极其强大的数据统计软件 Stata 安装教程_如何把stata装到硬盘里面
- 8Oracle使用序列触发器实现主键id自动增长_oracle的id自增序列
- 9蚁剑下载、安装_蚁剑 下载 csdn
- 10AI+AR,二维码还能这么玩儿!优质提示词的12个技巧;LLM学习路径和资料汇总;AI二维码工具大盘点 | ShowMeAI日报_quick qr提示词
新闻网站封锁AI爬虫 AI与新闻媒体博弈继续
赞
踩

随着ChatGPT等新兴AI模型的兴起,它们所依赖的网络爬虫正面临来自全球主流新闻网站的大规模封锁。Richard Fletcher博士团队对十个国家主流新闻网站的统计发现,到2023年底,48%的网站屏蔽了OpenAI的爬虫,24%屏蔽了Google的爬虫。那么究竟有多少新闻网站封锁了AI爬虫?
一、AI的网络爬虫
网络爬虫,有时称为“蜘蛛”或“机器人”,会自动浏览网络,系统地收集数据。搜索引擎依赖其网络爬虫收集的数据来对网络上的页面进行索引,以便快速响应搜索查询。
AI公司如OpenAI可以使用爬虫从网络中收集数据来训练它们的模型。大型语言模型(LLMs)需要在大量数据上进行训练才能发挥作用,而网络是高质量文本和视听数据的重要来源。
一旦训练完成,像GPT这样的LLMs可以通过ChatGPT等生成、输出并回答用户的问题。虽然这些模型在执行时无需与互联网连接,但一旦训练完成,它们也可以连接到网络,实时从网站检索信息,然后作为输出的一部分。
然而,出于各种可能的原因,新闻媒体可能不希望他们的内容被AI公司使用。
二、追踪调查:差异显著
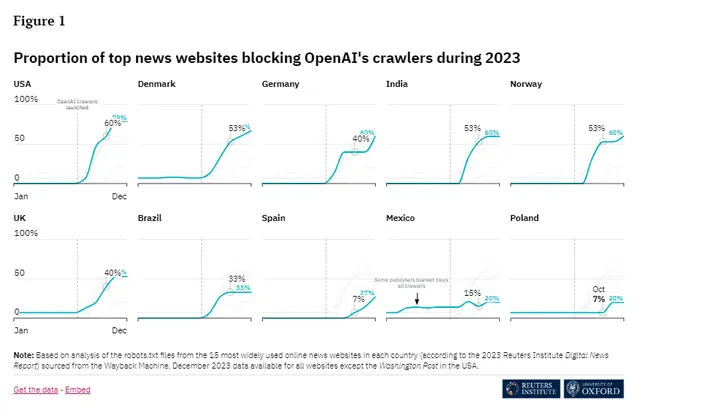
为了解各国主流新闻网站对AI爬虫的封锁政策,Richard Fletcher博士团队启动了一项追踪调查。对十个国家2023年度15大主流新闻网站爬虫屏蔽政策的跟踪统计,通过定期抓取主要新闻网站的robots.txt文件,他们监测了不同国家和不同时间节点上,新闻网站屏蔽OpenAI和Google等公司爬虫的比例,并发布了调查结果。
1.屏蔽比例差异大
不同国家主流新闻网站对AI爬虫的屏蔽态度存在显著差异。以OpenAI为例,美国高达79%的新闻网站进行了屏蔽,而墨西哥和波兰仅为20%左右。Google爬虫也存在类似差异,德国屏蔽比例为60%,波兰和西班牙则仅为7%。

2.屏蔽时间点差异大
在大多数国家,部分新闻网站会在AI爬虫面世后很快行动起来进行屏蔽;而在西班牙、墨西哥、波兰等国,主流媒体的举措显得更为迟缓保守。这可能与不同国家对AI态度的差异有关。
3.Google遭双重打击
97%屏蔽Google爬虫的网站,同时也屏蔽了OpenAI。尽管二者属于不同系统,但新闻媒体并未在政策上给予区分对待。这预示Google在新闻AI领域可能会面临比竞争对手更多的限制。
不难看出,全球主流媒体对第三方AI平台的警惕性正在上升。这会对AI相关模型的训练和应用形成一定负面影响。
三、主流媒体更保守
调查结果也反映出,主流媒体在AI政策上总体更为谨慎保守。
具体来看,相对于网络用户群体较小的垂直媒体,大众化口碑网站更倾向设置AI爬虫屏蔽。同样,拥有深厚印刷传统的报纸杂志,其网络版块屏蔽AI爬虫的可能性也远高于电视台及数字首发平台。
这种精神保守的态度与多重考量相关:
第一,主流媒体的内容价值更高,更看重知识产权,不希望AI平台免费获取利益;
第二,大众化媒体更担心错误信息误导公众,损害自己公信力;
第三,传统媒体从业人员了解AI偏少,更难理解长期利益均衡。
所有参与调查的新闻网站和每天在屏蔽 AI 爬虫后没有任何取消屏蔽的迹象。这表明新闻界对 AI 公司的态度趋于保守,出于内容价值、信息安全等多方面考量,主流媒体不太可能在短期内解除限制,除非双方达成新的利益均衡,例如授权使用商业合作模式等。
结语:
不难看出,此次调查结果表明,到2023年底,全球主流新闻网站对第三方AI平台的信息采集基本持防御态势。AI公司与新闻界之间利益博弈的大势仍在持续,未来双方关系究竟会走向何处呢?
参考信息来源网络,如有问题,请联系删除。

