
热门标签
热门文章
- 1基于VITA57.4标准的单通道6GSPS 12位采样ADC,单通道 6GSPS 16位采样DAC子卡模块_1.采样率:6gsps 2.采样精度:12bit; 3.实时带宽:500mhz; 4.耦合方式:ac
- 2Transformer模型-数据预处理,训练,推理(预测)的简明介绍_transformer部署 训练 推理
- 3某个网站(比如CSDN、GitHub)突然打开、加载很慢,有些途径访问正常、其他网站访问正常,可尝试指定域名服务器的IP地址,不走DNS查询。_csdn太卡
- 4xtrabackup备份还原_percona xtrabackup windows
- 5NLP最新趋势,7个主流业务场景!
- 6Redis scan命令 基本使用
- 7前端Web怎么插图:深入解析与实用技巧
- 8数据迁移一致性测试探索与实践_数据迁移验证一致性方法
- 9ARM32开发——LED点灯
- 10【夜深人静学数据结构与算法 | 第一篇】KMP算法_已知,模式字符串为aabacfb 在kmp中,前缀表是
当前位置: article > 正文
车牌识别(基于模板匹配算法)_车牌模板匹配算法
作者:我家自动化 | 2024-06-04 04:32:09
赞
踩
车牌模板匹配算法
vehicle_license_plate_recognition
车牌识别(基于模板匹配)
一、车牌识别的步骤
一般车牌识别分为4步:图像获取、车牌定位、车牌字符分割和车牌字符识别。
1.Candy边缘检测
Canny的步骤如下:
1.对输入图像进行高斯平滑,降低错误率。
2.计算梯度幅度和方向来估计每一点处的边缘强度与方向。
3.根据梯度方向,对梯度幅值进行非极大值抑制。本质上是对Sobel、Prewitt等算子结果的进一步细化。
4.用双阈值处理和连接边缘。
实例如下
import cv2
img = cv2.imread('car.jpg', flags=cv2.IMREAD_GRAYSCALE)
GBlur = cv2.GaussianBlur(img, (3, 3), 0)
canny = cv2.Canny(GBlur, 50, 150)
cv2.imshow('canny', canny)
cv2.waitKey(0)
cv2.destroyAllWindows()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8

2.膨胀腐蚀处理
#encoding:utf-8 import cv2 #将图片转为灰度图像 img = cv2.imread('car.jpg', cv2.COLOR_RGB2GRAY) #将原图做个备份 sourceImage = img.copy() #高斯模糊滤波器对图像进行模糊处理 img = cv2.GaussianBlur(img, (3, 3), 0) #canny边缘检测 img = cv2.Canny(img, 500, 200, 3) cv2.imshow('Canny', img) #指定核大小,如果效果不佳,可以试着将核调大 kernelX = cv2.getStructuringElement(cv2.MORPH_RECT, (29, 1)) kernelY = cv2.getStructuringElement(cv2.MORPH_RECT, (1, 19)) #对图像进行膨胀腐蚀处理 img = cv2.dilate(img, kernelX, anchor=(-1, -1), iterations=2) img = cv2.erode(img, kernelX, anchor=(-1, -1), iterations=4) img = cv2.dilate(img, kernelX, anchor=(-1, -1), iterations=2) img = cv2.erode(img, kernelY, anchor=(-1, -1), iterations=1) img = cv2.dilate(img, kernelY, anchor=(-1, -1), iterations=2) #再对图像进行模糊处理 img = cv2.medianBlur(img, 15) img = cv2.medianBlur(img, 15) cv2.imshow('dilate&erode', img) cv2.waitKey(0) cv2.destroyAllWindows()

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26

3.按特定形状特征排除干扰
#encoding:utf-8 import cv2 #将图片转为灰度图像 img = cv2.imread('car.jpg', cv2.COLOR_RGB2GRAY) #将原图做个备份 sourceImage = img.copy() #高斯模糊滤波器对图像进行模糊处理 img = cv2.GaussianBlur(img, (3, 3), 0) #canny边缘检测 img = cv2.Canny(img, 500, 200, 3) cv2.imshow('Canny', img) #指定核大小,如果效果不佳,可以试着将核调大 kernelX = cv2.getStructuringElement(cv2.MORPH_RECT, (29, 1)) kernelY = cv2.getStructuringElement(cv2.MORPH_RECT, (1, 19)) #对图像进行膨胀腐蚀处理 img = cv2.dilate(img, kernelX, anchor=(-1, -1), iterations=2) img = cv2.erode(img, kernelX, anchor=(-1, -1), iterations=4) img = cv2.dilate(img, kernelX, anchor=(-1, -1), iterations=2) img = cv2.erode(img, kernelY, anchor=(-1, -1), iterations=1) img = cv2.dilate(img, kernelY, anchor=(-1, -1), iterations=2) #再对图像进行模糊处理 img = cv2.medianBlur(img, 15) img = cv2.medianBlur(img, 15) cv2.imshow('dilate&erode', img) #检测轮廓, #输入的三个参数分别为:输入图像、层次类型、轮廓逼近方法 #因为这个函数会修改输入图像,所以上面的步骤使用copy函数将原图像做一份拷贝,再处理 #返回的三个返回值分别为:修改后的图像、图轮廓、层次 image, contours, hier = cv2.findContours(img.copy(), cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE) for c in contours: # 边界框 x, y, w, h = cv2.boundingRect(c) cv2.rectangle(img, (x, y), (x + w, y + h), (255, 0, 0), 2) print('w' + str(w)) print('h' + str(h)) print(float(w)/h) print('------') #由于国内普通小车车牌的宽高比为3.14,所以,近似的认为,只要宽高比大于2.2且小于4的则认为是车牌 if float(w)/h >= 2.2 and float(w)/h <= 4.0: #将车牌从原图中切割出来 lpImage = sourceImage[y:y+h, x:x+w] if 'lpImage' not in dir(): print('未检测到车牌!') cv2.waitKey(0) cv2.destroyAllWindows() exit() cv2.imshow('img', lpImage) cv2.waitKey(0) cv2.destroyAllWindows()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
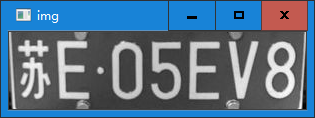
4、字符分割
字符分割方法很多,其中之一是:轮廓检测分割如下:
#边缘检测
lpImage = cv2.Canny(lpImage, 500, 200, 3)
#对图像进行二值化操作
ret, thresh = cv2.threshold(lpImage.copy(), 127, 255, cv2.THRESH_BINARY)
cv2.imshow('img', thresh)
cv2.waitKey(0)
cv2.destroyAllWindows()
- 1
- 2
- 3
- 4
- 5
- 6
- 7

4、模板匹配识别
识别结果

识别数据输出到图片

后续更新...
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/我家自动化/article/detail/670384
推荐阅读
相关标签

