
- 1【Python】如何在服务器上优雅的部署Python项目(Linux/Windows/Mac)_服务器部署python
- 2100 家企业软件测试笔试面试题汇总(网友真实面试后征集)_软件面试笔试题
- 3Hive介绍与环境搭建
- 4Linux——进程退出_linux退出当前进程
- 5使用solrj连接solrcloud时出现错误:NoNodeException: KeeperErrorCode = NoNode for /clusterstate.json的解决办法_nonodeexception keepererrorcode = nonode for
- 6SDK接口远程调试【内网穿透】_javasdk里面怎么调用远程服务
- 7常见处理器MCU、MPU、DSP、FPGA等嵌入式处理器概念_mcu、mpu、arm、fpga、dsp概念
- 8Java实现音频转文本(语音识别)_java cv语音识别
- 9文字生成图像内容解决方案,享受创作的乐趣
- 10【hiprint】hiprint的使用方法(附使用案例)hiprint 表格数据传输问题解决办法_hiprint官网
NLP最新趋势,7个主流业务场景!
赞
踩


1
深度之眼NLP项目实战安排
⭐BAT级工程部署
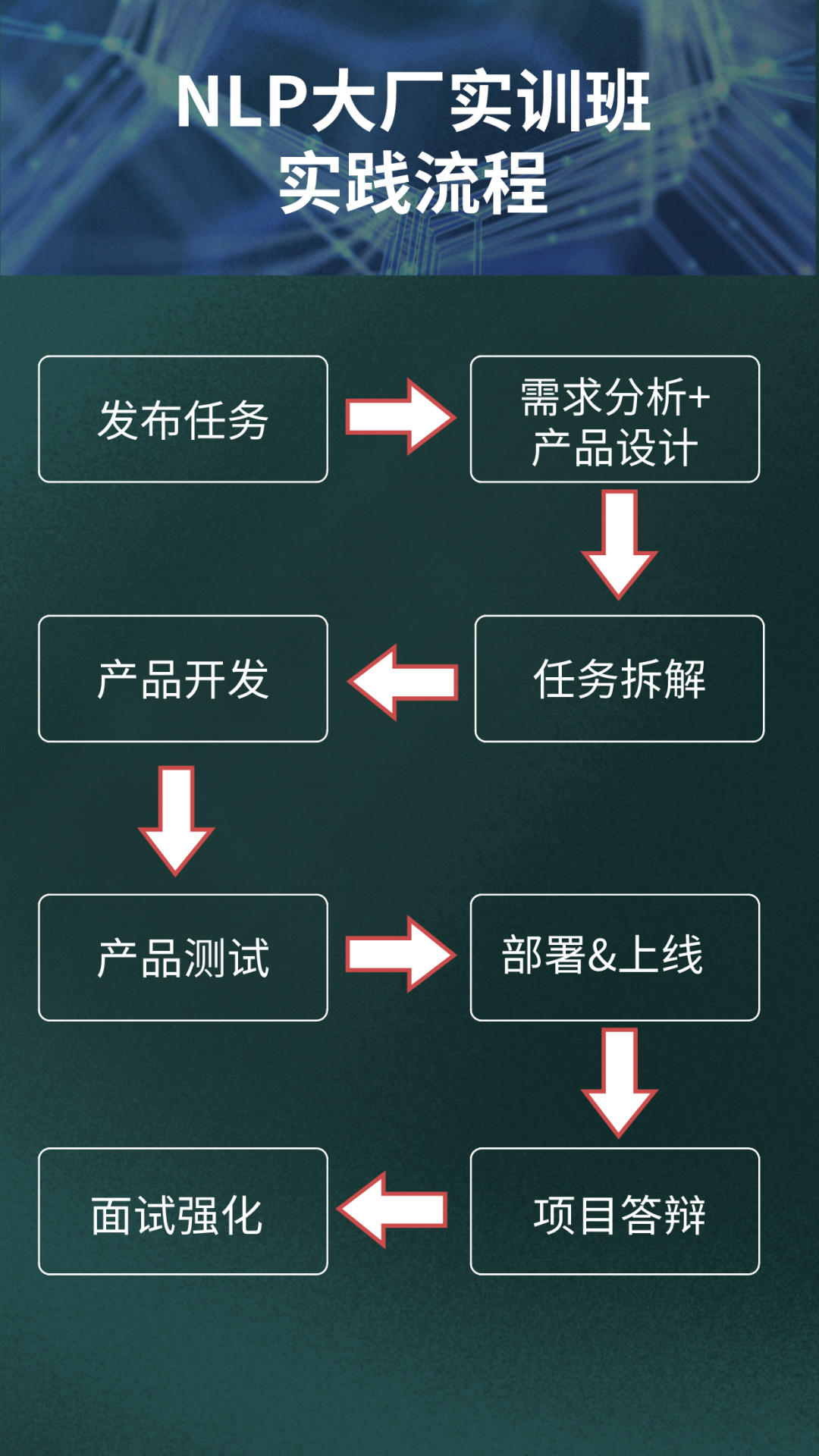
项目意义:工程化部署是程序在开发完成之后,到线上正式运行整个过程中涉及到的多个环节的统称,主要包括:测试、GPU的分配和使用、微服务的封装、Docker镜像的构建、K8S集群实例的开启等,这些在工业生产中极为重要;
应用场景:本项目基本按照上述各个环节的顺序,以分词模型为例,带领大家实践整个流程:测试、GPU的分配和使用、微服务的封装、Docker镜像的构建、K8S集群实例的开启
项目输出:我们将带领大家走完企业里一个线上模型服务的如下过程:
接口封装、接口测试、镜像构建、CI/CD、GPU部署、K8S集群部署等
⭐项目一、中文分词-类搜狐新闻场景下的中文分词器
功能展示▼
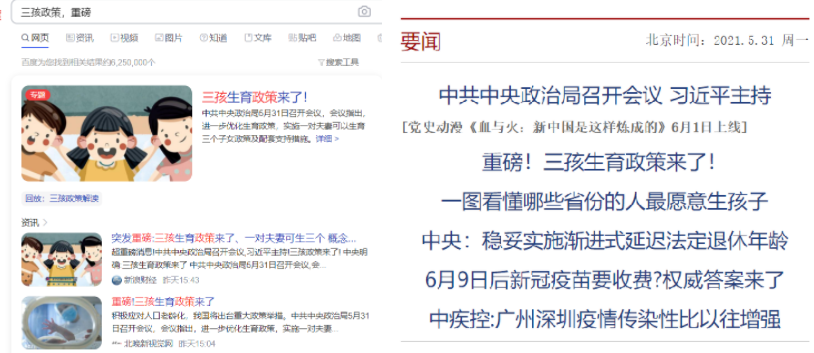
门户网站分类系统,会使用分词后的词作为特征
原理构成▼
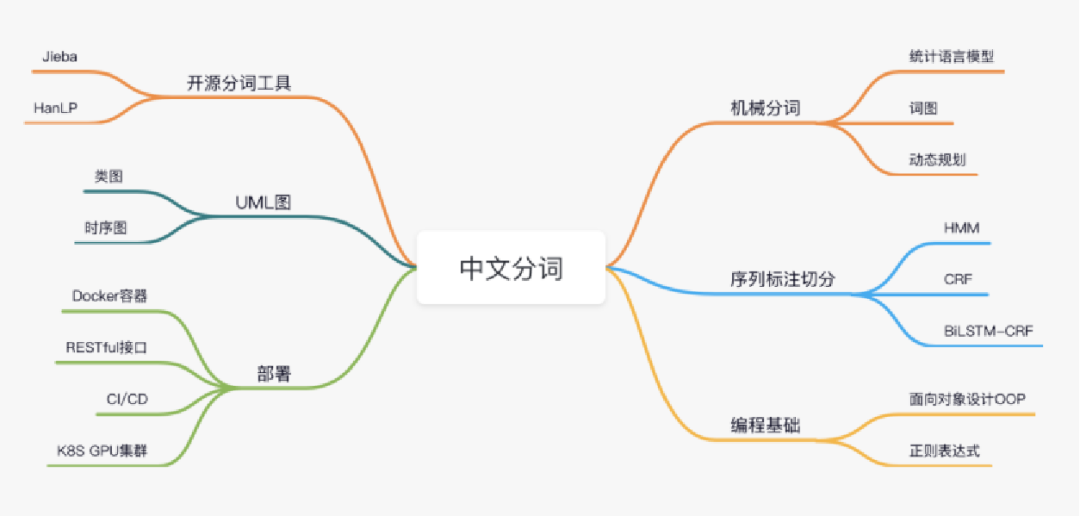
应用场景:本项目结合工业场景里常见的分词需求,从基本的基于语言模型的机械分词讲起,使用CRF模型、BiLSTM-CRF模型提升精度,再到满足上述需求的系统,最终实现一个工业级的中文分词工具。
项目输出:我们将实现一个新闻语料下的分词器,满足如下条件:
在不使用GPU、单个进程的条件下,满足至少0.85的精度,至少100的QPS;
同时满足毫秒级快速规则解决badcase,并可以根据反馈的badcase系统模型迭代升级;
涉及知识点:业务对于分词的需求情况、分词器构建的基本流程、
统计语言模型、机械切分、条件随机场CRF、BiLSTM-CRF模型、
模型融合策略、badcase快速解决
⭐项目二、关键词提取-类新浪门户场景下的关键词提取
功能展示▼

新闻网站都有关键词,这些都是自动生成的
原理构成▼

应用场景:本项目以无监督的关键词提取算法为主,带领大家实践基于TFIDF、TextRank、LDA、新词发现的不同提取方法,也会提到一些有监督的关键词提取方法。
项目输出:我们将实现一个新闻语料下的关键词提取器,满足如下条件:
在单个进程的条件下,满足至少0.80的精度,至少100的QPS;同时满足识别出新词的能力;
涉及知识点:关键词提取的场景、构建系统的常用算法、TFIDF、TextRank、主题模型LDA、新词发现技术、有监督的关键词提取技术、关键词系统的评估。
⭐项目三、实体识别-类新浪微博场景下的实体识别
功能展示▼
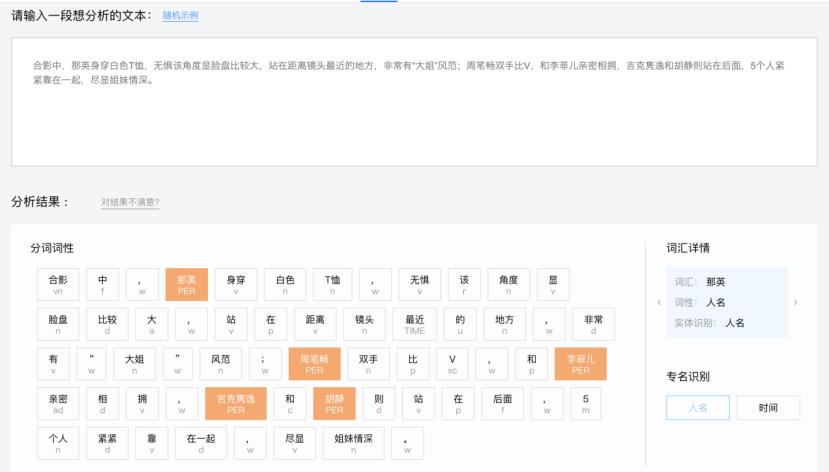
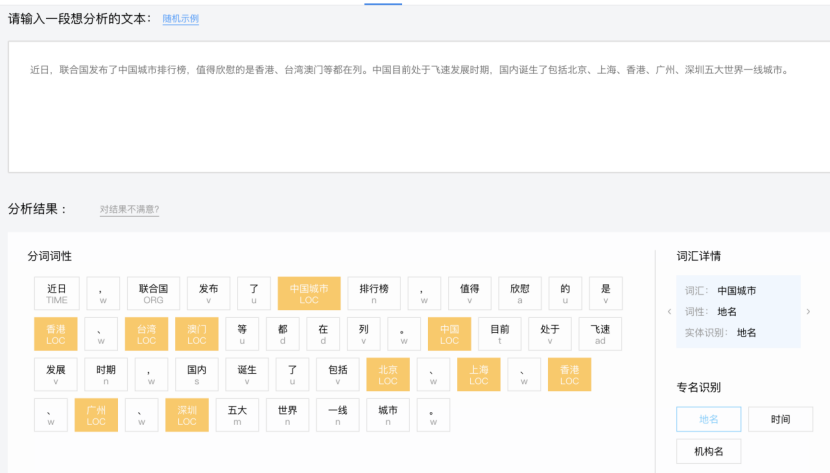
原理构成▼
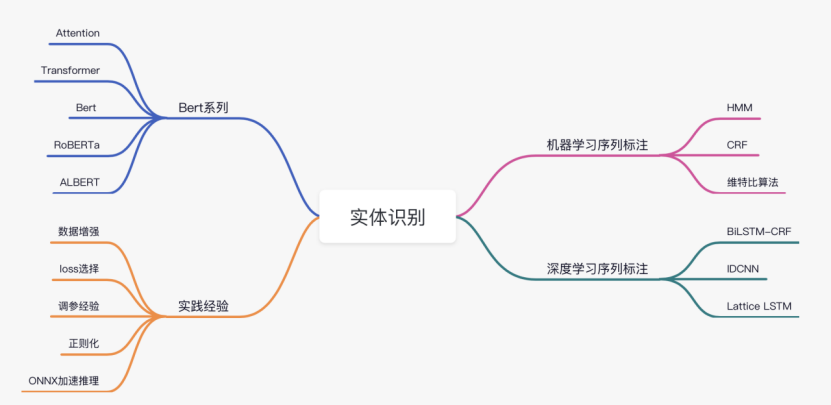
应用场景:本项目教大家从基本的HMM、CRF做实体识别开始,升级到IDCNN模型,再升级到Bert、及其变体RoBERTa等,在升级模型的同时,我们还着重强调一些实体识别方面的实践经验,比如处理标签分布不均匀、Bert的使用经验、ONNX加速推理等。
项目输出:本项目带领大家实现一个基于多种模型的实体识别系统,要满足如下特性:传统机器学习下,至少80%的精度,至少10的qps;深度学习下,至少90%的精度,不小于1的qps(不使用GPU),不小于10的qps(使用GPU);
涉及知识点:识别识别业务场景理解、条件随机场模型CRF、IDCNN、BERT及其变体(RoBERTa、ALBERT等)、ONNX加速推理、多卡并行、评估实体识别
⭐项目四、文本分类-头条新闻标题分类场景下的BERT分类器训练、优化及蒸馏
功能展示▼

原理构成▼
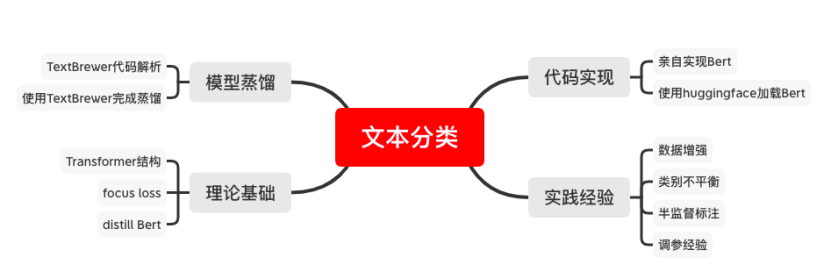
应用场景:在实际模型开发过程中,常常会遇到两类问题:(1)文本数据不规范,数据中包含大量的噪声、类别不平衡等问题;(2)文本数据缺乏标注。这两类问题大幅提升了效果稳定的文本分类模型的开发难度。500ms/edge;
本项目以今日头条新闻标题分类数据集为基础,介绍torch框架下BERT-based模型的快速搭建方法,手把手讲解如何处理常见的两大类问题,同时介绍如何对分类模型进行蒸馏,满足在线服务的实时性需求。
项目输出:1、基于BERT的分类器,在中等难度任务和噪声数据条件下,预测F1不低于0.9
2、基于BERT的蒸馏分类器,和上述模型相比,效果退化不超过0.05,响应速度不低于10qps
涉及知识点:Roberta、KN平滑、focus loss
Model distillation、intermediate loss
⭐项目五、知识图谱-招聘场景下的知识图谱搭建和查询
功能展示▼

原理构成▼
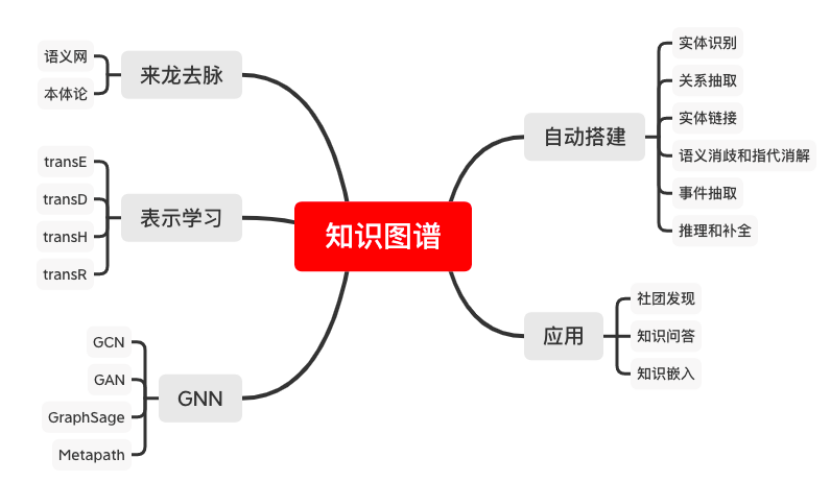
场景应用:知识图谱的技术主要有两部分:从非结构化数据中自动搭建知识图谱、在知识图谱上进行补全和推理。本项目从这两方面入手,系统性地介绍知识图谱的相关理论和技术发展,让学员对知识图谱的来龙去脉有深刻的了解。
项目输出:我们将搭建一个简单的知识图谱,满足如下条件:
1、使用neo4j提供查询服务,响应时间不高于500ms;
2、批量向图中增加新的数据,响应时间不高于500ms/edge;
涉及知识点:语义网、本体论、NER、关系抽取、实体链接、事件抽取
GNN、GraphSage、metapath、transE、transD、transH
⭐项目六、摘要生成-哈工大新闻摘要生成场景下的摘要模型训练及优化
功能展示▼
原理构成▼
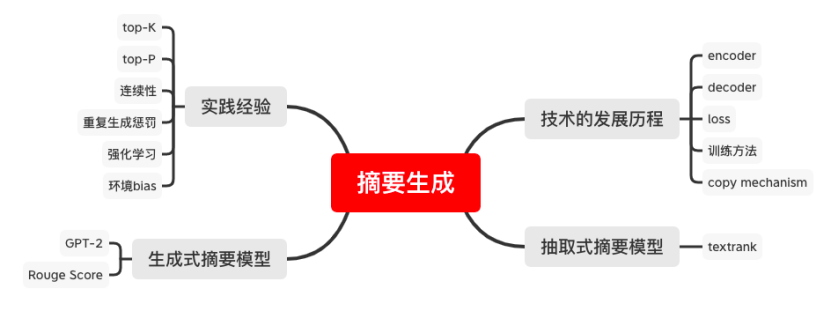
应用场景:如何开发一个稳定性高、压缩效果好的摘要模型是很多非技术企业不具备的技术能力,本项目从理论和实战入手,手把手介绍如何高效地开发摘要模型,并掌握多种摘要模型的优化策略,满足复杂的业务需求。
项目输出:我们将实现一个基于GPT的生成式摘要模型,满足如下条件:
1、高回答有效性,top10摘要的有效性不低于90%;
2、单GPU下预测速度不低于1qps;
涉及知识点:抽取式摘要模型、生成式摘要模型、GPT-2
Beam search、语言模型
Rouge Score、reinforcement learning、environment bias
⭐项目七、智能对话-清华QA匹配场景下的QA对话系统核心模块训练及优化
功能展示▼
原理构成▼
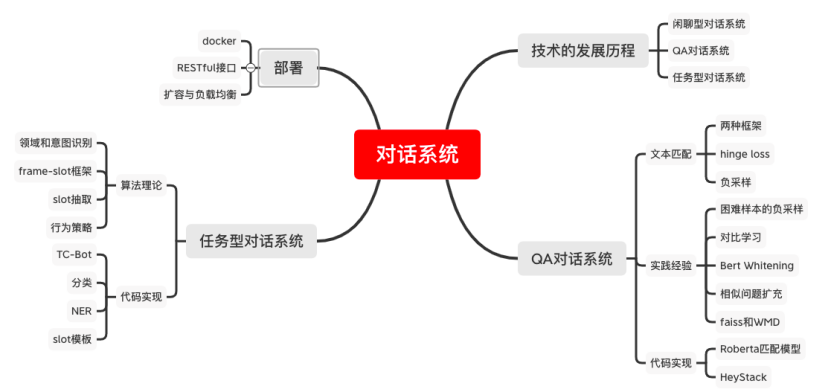
应用场景:智能对话系统往往用于智能客服、智能投顾、智能回复等业务场景中,由于直接面向客户,因此,往往需要具有足够经验的算法工程师负责智能对话系统的开发和迭代优化工作。
本项目主要介绍QA型对话系统和任务型对话系统的开发和优化,系统性地介绍对话系统的技术发展历程,掌握对话系统核心模块的开发和优化方案。
项目输出:实现两种对话系统
1、QA对话系统匹配模块,预测top3有效性不低于90%,响应速度不低于10qps;
2、任务型对话系统,可以完成简单的任务输出;
涉及知识点:QA对话系统结构、任务型对话系统结构\Ranking loss、对比学习、dropout、faiss、量化聚类、frame-slot、意图分类、情感分类、实体识别
2
算法架构师牵头实训
NLP大厂实训班实行小班制点对点教学,每个班级学员人数严格控制,充分照顾每个学员的知识掌握程度,根据学习进度,定制学习计划。


3
入职式业务实践
配套BAT级大规模集群部署
课程从算法理论、代码实操和项目落地三个角度入手,以解决企业项目为导向,采用企业里老带新、师带徒的的项目推进模式,推动项目进展,带给学员身临其境的学习体验。
课程中还包括项目部署方法的介绍,使学员在学习本课程之后,具备独立开发模型并进行服务化部署的能力,提高在算法人员面试和工作中的竞争力。
4
精英助教24h答疑
助教实时答疑:小班制教学、老师+助教双重保障答疑,全面满足你的求知欲
作业点评辅导:进度汇报+实战技巧+作业讲解+作业发布,想不跟着学都难!
项目汇报:每个项目结束后进行一次项目汇报,输出倒逼输入,更快获得成长
5
直击大厂面试现场
大厂NLP算法负责人模拟面试场景
求职行业分析
↓
简历1对1修改
↓
面试题互动解答
↓
招聘岗位推荐
6
课程基础要求
1. 熟悉Python语言、了解一个深度学习框架(Pytorch、Tensorflow或MXNet);
2. 至少熟悉简单的机器学习模型,如LR SVM HMM 正则化等;
3. 至少熟悉简单的深度学习模型,如word2vec CNN RNN
7
课程收获
1、了解项目的实际开发流程,融会贯通地掌握多种工业界常用算法和模型的理论基础和优化策略,了解不同算法的优劣势。
2、掌握7个企业典型业务需求的处理方案,掌握模型开发调优的思路和经验,获得7套可复现的项目工程代码,建立企业项目操作的思路框架。
3、掌握项目工程开发和部署的流程和方法,具备在工作中独自承担项目工程的能力,提高你在工作中的竞争力
4、积累项目经验,掌握面试要点及技巧,系统性地为学员梳理面试中常遇到的问题体系,提高学员在面试一线大厂时的通过率。
8
学员毕业去向
深度之眼内推企业均为国内外一线大厂▼

8
首发福利
1、GPU——智星云(200)
2、答疑时间延长至一年
3、学习优秀者内推岗位
《深度之眼NLP大厂实训班》
实操真实业务场景,7个项目学完即用
对课程有意向的同学
扫描二维码
咨询课程、领取「NLP大厂进阶秘籍」
????????????


