
- 1排序合并连接(sort merge join)的原理_sort merge join worst case
- 2axios常用5种请求详解_axios请求
- 39个offer,12家公司,35场面试,从微软到谷歌_35轮面试 9个offer
- 4Android Studio 国内高速下载安装_android studio jellyfish
- 5也谈人工智能——AI科普入门
- 6一文搞懂MQTT,如何在SpringBoot中使用MQTT实现消息的订阅和发布_springboot mqtt
- 7darknet框架下yolov3实战(一)_yolov3 darknet
- 8Odoo|5分钟教你用odoo创建一个网站_odoo数据库管理
- 9数据密集型企业是如何选择替代FTP传输文件的系统的?
- 10蓝军HVV实用工具和网站总结,想给金三银四找工作的程序员几点建议_hvv 绿盟
transformer概述和swin-transformer详解_swintransformer和transformer
赞
踩
目录
1.transformer架构
transformer的整体网络架构如下:
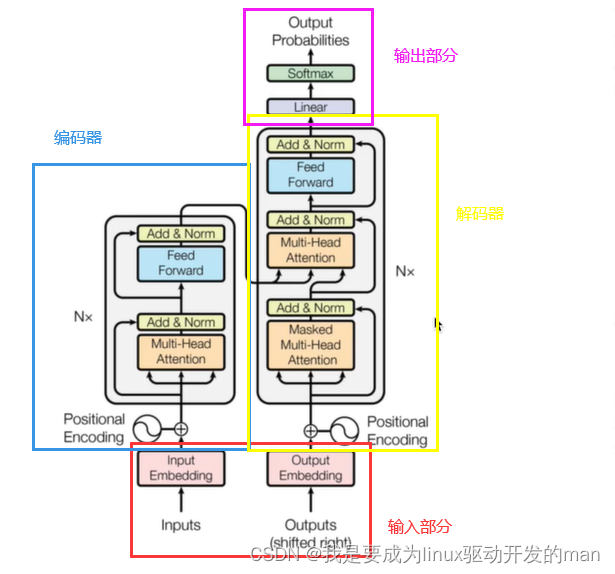
其中具体分为:输入,输出,编码器,解码器
输入:源文本嵌入层+位置编码
目标文本嵌入层+位置编码
输出:线形层+softmax激活函数
编码器:由N个编码器构成
每个编码器由两个子层连接
第一个子层由多头注意力层+规范化层+残差层
第二个子层由前馈全连接子层+规范化层+残差层
解码器:由N个解码器构成
每个编码器由三个子层连接
第一个子层由多头自注意力层+规范化层+残差层
第二个子层由多头注意力层+规范化层+残差层
第三个子层由前馈全连接子层+规范化层+残差层
1.1输入部分实现
作用:
文本嵌入层:是为了将文本中词汇的数字表示为向量表示,以此得到高维空间中词汇间的关系。
位置编码器:由于词汇直接没有位置信息,因此要在Embedding(文本嵌入层)之后加入位置编码,将词汇处于不同位置可能产生的语义信息加入到词嵌入张量(Embedding层产生的张量)中,以弥补位置信息缺少。
嵌入层代码分析:

其中embedding = nn.Embedding(10,3)代表把长度为10的单词嵌入到大小为3的维度中。
位置编码器代码分析:

1.2编码器部分实现
每个编码器根据输入向目标方向(比如中翻英,就是中作为输入,编码器根据这个输入得到特征)进行特征提取
1.2.1掩码张量
是什么?
掩:代表遮挡的意思。码:张量中的数值,尺寸不定内容为0或1。掩码就是有些位置被遮挡
作用?
加入掩码是为了防止未来信息被提前得到
代码分析:

经过该函数生成一个最后两维是1方阵的下三角阵。
1.2.2注意力机制
什么是注意力?
快速关注某一个事物,是因为大脑能集中在关键部分,而不是全部看完再做结论。这种集中在关键部分的能力就叫注意力。
注意力计算方法?
给定Q(query),K(key),V(value)三个参数,Q在K和V的作用下得到注意力结果。例如下面这个公式

Q,K,V分别是什么意思?
举个例子。给你一段话(Q),然后给你一些提示答案(K),你就可以得到你的答案(V),这里存在一些情况,比如你很笨,给你了K之后,你的答案还是K,因为你笨所以你根据提示之后还是只有提示。但是随着你多学一会儿,你可以对Q提取信息了,然后你的V也发生改变。
自注意力机制?
Q和K和V都是一样的,你有了V,现在给你K,你就相当于从文本Q根据文本本身K提取特征V。
注意力网络结构图:

注意力机制代码:

1.2.3多头注意力机制
是什么?
多头指的是把词嵌入向量进行均分之后送到多个注意力机制模块中进行计算。
多头注意力结构图:
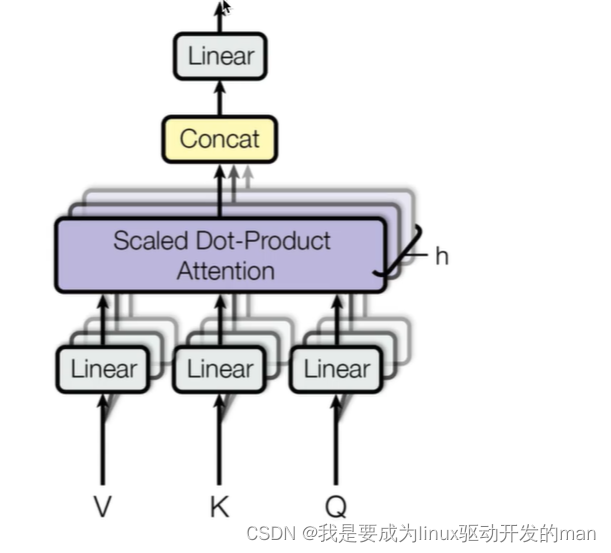
QKV分别经过线性变换(三个方阵),然后把词嵌入向量最后一维(d_modle)进行分割,每个注意力模块获得其中一部分。
作用?
让每个注意力模块优化每个词汇的不同特征部分,减小误差
代码分析:

1.2.4前馈全连接层
是什么?
具有两次线性层的全连接网络,且输入输出的形状大小不变
作用?
考虑注意力对复杂模型拟合不够,增加两层网络提高能力
代码分析:

1.2.5规范化层
作用?
网络层数过深,需要规范化进行优化
代码分析:
根据均值,方差进行优化

1.2.6子层连接层
是什么?
子层就是说一个输入x,经过处理之后得到y,再把x和y进行contact。这一个整体叫子层连接。其中编码器包括两个子层连接。

代码分析:

1.2.7编码器层
作用?
对输入特征进行特征提取,也叫编码过程
代码分析:

1.2.8编码器
作用?
对编码器层复制N份构成编码器
代码分析:

1.3解码器部分实现
1.3.1解码器层
作用?
每个解码器根据输入向目标方向(比如中翻英,就是中已经特征提取的东西作为输入,解码器根据这个输入得到英)进行特征提取
代码分析:

1.3.2解码器
作用?
根据编码器结果以及自身上一次预测结果对进行特征提取,输出形状没变(2x4x512)
代码分析:

1.4输出部分实现
代码分析:

2.swin-transformer
解决了什么问题?
1.图像中像素点过多,需要很长的序列
2.利用分层和窗口替代长序列。
7*7=49个patch
网络结构

Parition

Embedding

swin模块

W-MSA

windo_reverse

SW-MSA
为什么?
原window是算自己内部,和外界没有关联。因此需要窗口滑动

