
热门标签
热门文章
- 1jmeter常用函数
- 2NLP学习总结|ChatGLM模型架构_chatglm 架构
- 3运维之docker启动失败Failed to start Docker Application Container Engine(1)
- 4C++/Qt 信号槽机制详解_qt 定义信号 和 连接信号
- 5springboot中使用redis及redis常用方法_redis maven
- 6「网络安全」SQL注入攻击_sql注入漏洞代码
- 7M3芯片macbook pro安装Maven时出现错误提示zsh: command not found: brew的解决办法#homebrew
- 8信创应用软件之邮箱_信创邮箱
- 9花卉培育信息管理系统设计与实现_园林花卉管理系统设计与开发
- 10HashMap(一)——HashMap put方法原理_hashmap lut
当前位置: article > 正文
BOSS直聘定时投递岗位脚本~~_boss投简历脚本
作者:我家自动化 | 2024-07-10 05:16:48
赞
踩
boss投简历脚本
BOSS直聘自动投递岗位脚本~~

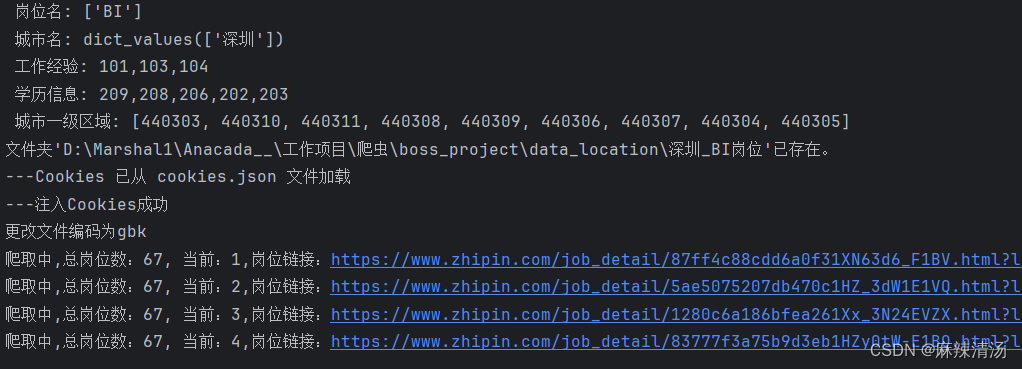
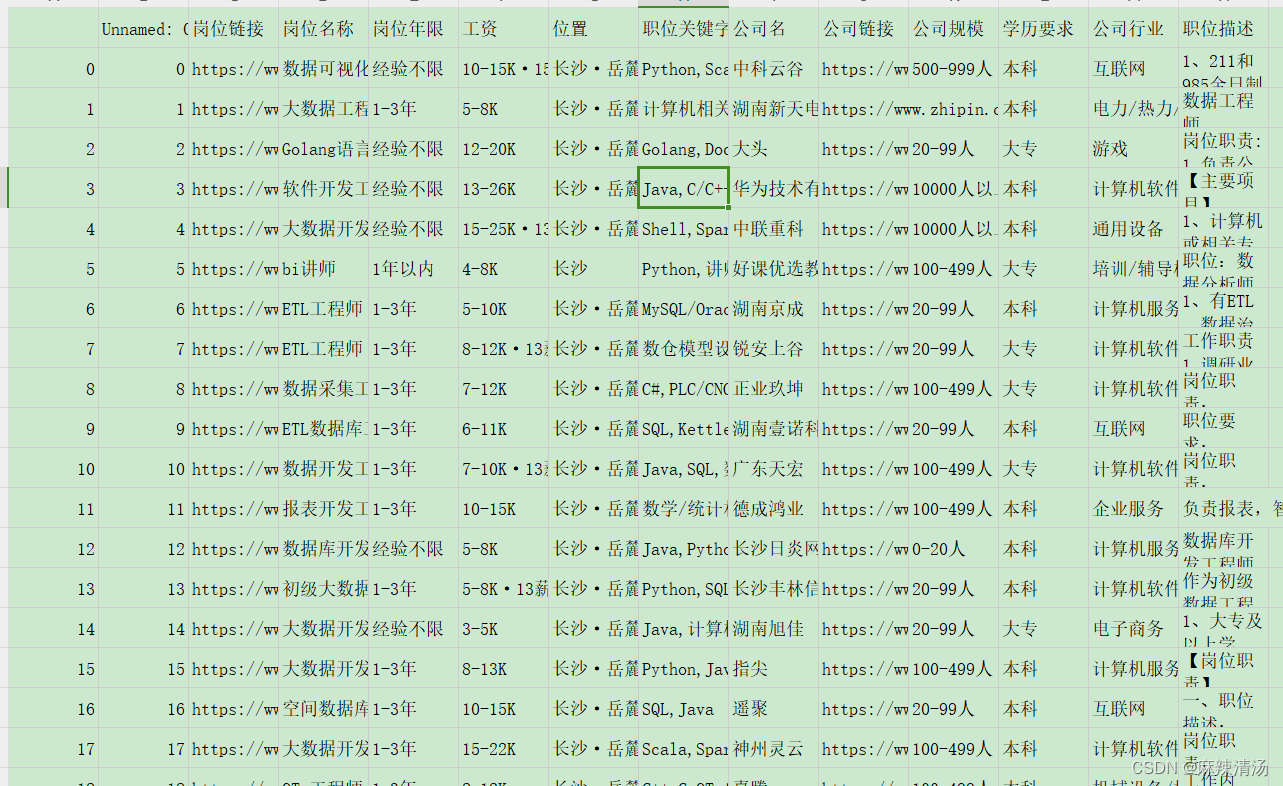
建立在已经爬取所需要的岗位信息之后,筛选出来我们需要投递的岗位的信息放到指定的目录之后
还未爬取到每个岗位的链接的进入:https://blog.csdn.net/weixin_52001949/article/details/135452969
以下是关键代码,想要获取完整代码,关注公众号:“麻不辣青汤" 点击获取源码
- 首先,因为投递岗位需要登录,我们可以先登录之后,获取cookie,这样就不用每次进去再登录一次
- 注入cookies登录之后,遍历每个需要投递的岗位链接,通过selenium获取元素进行点击投递
- 获取cookie关键代码:
- 获取cookie的另一种快速方式:https://blog.csdn.net/weixin_52001949/article/details/134920749
#1. 获取cookies
cookies = boss.get_cookies()
cookies_json = json.dumps(cookies, indent=4)
#2. 登录完成后,将cookies保存到本地文件
with open(cookie文件名, "w") as file:
file.write(cookies_json)
print("Cookies 已保存到 cookies.json 文件")
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 将cookies保存到本地之后,注入cookies
# 1.打开网页,注入cookies
boss.get(url)
for cookie in cookies_loaded:
boss.add_cookie(cookie)
print("---注入Cookies成功")
boss.refresh()
# 2. 等待页面加载完成
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 进入岗位详情链接,点击投递
for url in df['岗位链接']:
count=count+1
boss.get(url)
等待元素出现('btns',url,5)
已沟通 = boss.find_elements(By.XPATH, "//*[contains(text(), '您与该Boss已沟通过')]")
沟通 = boss.find_elements(By.XPATH, "//*[contains(text(), '沟通')]")
if 已沟通:
之前是否沟通.append('已沟通')
else:
if len(沟通) > 0: boss.find_element(By.XPATH, "//*[contains(text(), '沟通')]").click()
之前是否沟通.append('未沟通')
print(f'爬取中,总岗位数:{需投岗位数}, 当前:{count},岗位链接:{url}')
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/我家自动化/article/detail/804941
推荐阅读
相关标签

