
- 1yolov5模型部署到web端,识别返回json格式文件_yolov5 输出图片识别结果json
- 2Bean的作用域中prototype原型模式(浅拷贝和深拷贝)_bean prototype
- 3html固定在页面底部,css中页脚如何固定在底部?
- 4监督学习和无监督学习的基本概念及作用-机器学习知识点
- 5java搭建阿里云服务器环境(java环境+mysql+tomcat)和部署 JavaWeb 项目到云服务器(十分详细)_tomcat+mysql的项目迁移到移动云上
- 62021-11-22 (atcoder)_atcoder预测分
- 7ES(elasticsearch)搜索引擎 结合java 使用_es搜索引擎java使用
- 8Kafka简单总结_kafka-console-producer.sh --broker-list
- 9计算机视觉所需要的数学基础
- 10Docker、Docker file、Docker-compose 详解_docker file docker compose
多模态融合2022|TransFusion: Robust LiDAR-Camera Fusion for 3D Object Detection with Transformers_transfusion网络
赞
踩
论文题目:TransFusion: Robust LiDAR-Camera Fusion for 3D Object Detection with Transformers
会议:CVPR2022
单位:香港科技大学,华为
1.摘要+intro
作者认为目前的坑是在point-wise级的融合,之前方法存在两个主要问题,第一,它们简单地通过逐个元素相加或拼接来融合LiDAR特征和图像特征,因此对于低质量的图像特征,例如光照条件较差的图像,这样融合的性能会严重下降。第二,稀疏的LiDAR点与密集的图像像素之间的硬关联(硬关联机制是指利用标定矩阵来建立LiDAR点和image像素的关联)不仅浪费了许多语义信息丰富的图像特征,而且严重依赖于两个传感器之间的高质量标定,但作者认为标定的质量是得不到保证的。
所以作者提出了Transfusion网络(使用两个transformer解码层作为检测头)来解决以上问题。为了使目标查询依赖输入和并具有类别的感知,作者设计了全新的query的初始化模块,并利用第一个transformer解码层来生成初始3D边界框。为了能使query自适应地与空间和上下文关系相关联的有用的图像特征融合,作者设计了第二个transformer解码层。最后,为了检测点云中难以检测到的目标,作者在query初始化阶段引入了image guidance来进行优化。
2.method
模型结构:

2.1 Query 初始化
1)输入依赖
作者认为,初始化的query的位置如果与输入数据无关的话会使得模型后续采取额外的解码层来学习向gd目标框移动的过程。受Efficient DETR启发,发现更好的query初始化能使得后续解码器的层数减少。所以作者提出了一种基于中心热力图的query初始使得query依赖于输入,使得网络仅使用一层解码器层即可获得具有竞争力的性能。具体的思路是:首先给定一个LiDAR BEV的特征图FL,维度是X×Y×d,用这个FL预测了类的热力图S,维度是X×Y×K,X和Y是BEV特征图的size,K是类别的数量,对于每个(x,y)选出所有类别置信度中top N的类别作为候选为(2)类别感知服务。为了避免空间上有太密集的queries,作者仿照CenterNet的思想,选择热力图中的局部极大值元素作为queries(这里的这个热力图上的局部最大值指的是大于或等于它的8连通邻域)
2)类别感知
作者认为BEV平面上的对象不同类别的对象之间的比例差异很大,所以可以利用这些特性进行更好的多类别检测。具体思路就是在每个query中嵌入一个类别embedding,具体地说,使用(1)中选定好的的候选类别Si,j,将Si,j的维度投影到d维后,并将对应位置的query特征和这个类别embedding在element-wise级别上相加。
2.2 Transformer Decoder and FFN
该解码器遵循DETR的设计原则,即包括了利用多层感知器(MLP)将query的位置嵌入到d维位置编码中,并与查询特征进行元素级求和。然后前馈网络将N个query独立解码为boxed和class labels。同时采用了辅助解码机制(即在每个解码层后都添加了FFN和监督来计算每一层的损失),作者在后续的LiDAR-Camera Fusion模块中就利用了这种第一层解码器的预测来限制交叉注意力。
2.3 LiDAR-Camera Fusion
1)图像特征提取
由于当一个物体只包含少量LiDAR点时,它只能提取相同数量的图像特征,浪费了高分辨率图像丰富的语义信息。所以作者没有用硬关联的方法提取LiDAR对应的像素特征,而是保留所有的图像特征作为记忆库,用在transformer解码器中用交叉注意力机制采用自适应的特征融合方式,这样能够自适应得选择图像特征。
2)空间调制的交叉注意力(SMCA)用于图像特征融合
首先拿到第一个解码器的输出目标框位置后,利用预测的结果以及标定矩阵来找到query(上一层解码器的输出作为这一层的query)在图像中的定位。然后在query和对应的特征图之间做交叉注意力。但是作者认为由于LiDAR特征和图像特征来自完全不同的域,query可能会关注到与预测的边界框无关的视觉区域,导致网络要准确识别图像上的适当区域需要较长的训练时间。所以作者设计了一个空间调制的交叉注意力模块来解决这个问题。通过一个2D圆形高斯掩模来加权每个query的2D投影中心周围的交叉注意力(即不是在image的全图的做交叉注意力了),将该权重图与所有注意力头部的交叉注意图进行元素级相乘。作者认为这样每个query就只在投影的2D框周围的相关区域进行交叉注意力,这样网络就可以更好、更快地了解到根据输入的LiDAR特征在哪里选择图像特征。在SMCA之后,作者使用另一个FFN利用包含LiDAR和图像信息的对目标query来产生最终的box预测。
2.4 标签分配和损失
和DETR一样用匈牙利算法实现预测和gd的匹配,其余没什么特别之处
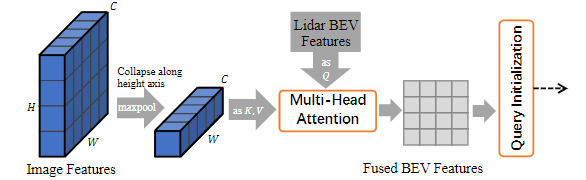
2.5 Image-Guided Query Initialization(这里是对2.1提到的query的初始化进行优化,类别热力图的生成方式从原来的只用LiDAR BEV作为输入变成了LiDAR BEV+camera作为输入)
作者认为query的选择仅使用的是LiDAR特征,这可能会导致检测召回的次优目标。所以为了进一步利用高分辨率图像检测小目标的能力,使算法对稀疏的LiDAR点云具有更强的鲁棒性,选择利用LiDAR和camera信息来作为query的初始化。具体思路就是通过与LiDAR Bev特征FL使用交叉注意力将图像特征FC投影到BEV平面上生成新的LiDAR-Camera Bev 特征图FLC(即下图的Fused BEV Features)。具体操作就是作者使用沿高度轴压缩的多视图图像特征作为注意机制的key-value序列。作者说BEV位置和图像列之间的关系可以通过利用相机变换矩阵来建立。因此,沿高度轴压缩可以在不丢失关键信息的情况下显著减少计算量。虽然在这个压缩过程中可能会丢失一些细粒度的图像特征,但它已经满足了特征信息的需要,因为只需要一个关于潜在对象位置的提示。
3.结果


