
- 1【项目】Java API站内搜索引擎_搜索引擎api
- 2书生·浦语2.5开源,推理能力再创新标杆
- 3Leetcode.203.移除链表元素
- 4mysql 启动/停止命令_启动mysql的命令是什么
- 5【论文阅读笔记】生成对抗网络及其在图像生成中的应用研究综述_基于对抗神经网络的图像生成技术研究
- 6常见30种数学建模模型_30+模型及编程资料,带你轻松入门建模竞赛与论文建模...
- 7在Windows Server 2012启用或关闭Internet Explorer增强的安全配置
- 8振动信号的采集与预处理
- 9MySQL数据库课程设计——订餐系统(MySQL数据库+Qt5用户界面+python)_数据库外卖订餐管理系统
- 10【入门教程一】基于DE2-115的My First FPGA 工程
1024 分辨率下最快模型,字节跳动文生图开放模型 SDXL-Lightning 发布_sdxllightning下载
赞
踩

作者:字节跳动智能创作团队
很高兴跟大家分享我们最新的文生图模型 —— SDXL-Lightning,它实现了前所未有的速度和质量,并且已经向社区开放。
模型:https://huggingface.co/ByteDance/SDXL-Lightning
论文:https://arxiv.org/abs/2402.13929

闪电般的图像生成
生成式 AI 正凭借其根据文本提示(text prompts)创造出惊艳图像乃至视频的能力,赢得全球的瞩目。然而,当前最先进的生成模型依赖于扩散过程(diffusion),这是一个将噪声逐步转化为图像样本的迭代过程。这个过程需要耗费巨大的计算资源并且速度较慢,在生成高质量图像样本的过程中,单张图像的处理时间约为5秒,其中通常需要多次(20 到 40 次)调用庞大的神经网络。这样的速度限制了有快速、实时生成需求的应用场景。如何在提升生成质量的同时加快速度,是当前研究的热点领域,也是我们工作的核心目标。
SDXL-Lightning 通过一种创新技术——渐进式对抗蒸馏(Progressive Adversarial Distillation)——突破了这一障碍,实现了前所未有的生成速度。该模型能够在短短 2 步或 4 步内生成极高质量和分辨率的图像,将计算成本和时间降低十倍。我们的方法甚至可以在 1 步内为超时敏感的应用生成图像,虽然可能会稍微牺牲一些质量。
除了速度优势,SDXL-Lightning 在图像质量上也有显著表现,并在评估中超越了以往的加速技术。在实现更高分辨率和更佳细节的同时保持良好的多样性和图文匹配度。

速度对比示意
原始模型(20 步),我们的模型(2 步)
模型效果
我们的模型可以通过 1 步、2 步、4 步和 8 步来生成图像。推理步骤越多,图像质量越好。
以下是我们的 4 步生成结果:
 A girl smiling(一个微笑的女孩) A girl smiling(一个微笑的女孩) |  A pickup truck going up a mountain switchback(一辆小卡车正在上之字形山路) A pickup truck going up a mountain switchback(一辆小卡车正在上之字形山路) |  A fish on a bicycle, colorful art(鱼骑自行车,多彩艺术) A fish on a bicycle, colorful art(鱼骑自行车,多彩艺术) |  A man standing on the street, full body(站在街上的人,全身像) A man standing on the street, full body(站在街上的人,全身像) |
|---|---|---|---|
 A close-up of an Asian lady with sunglasses(戴墨镜的亚洲女士特写) A close-up of an Asian lady with sunglasses(戴墨镜的亚洲女士特写) |  A beautiful cup(一个漂亮的杯子) A beautiful cup(一个漂亮的杯子) |  A lion in the galaxy, octane render(银河系中的狮子,渲染) A lion in the galaxy, octane render(银河系中的狮子,渲染) |  An owl perches quietly on a twisted branch deep within an ancient forest(一只猫头鹰安静地栖息在古老森林深处一根扭曲的树枝上) An owl perches quietly on a twisted branch deep within an ancient forest(一只猫头鹰安静地栖息在古老森林深处一根扭曲的树枝上) |
 An astronaut riding a horse(宇航员骑马) An astronaut riding a horse(宇航员骑马) |  house in the desert, surreal landscapes(沙漠中的房子,超现实的风景) house in the desert, surreal landscapes(沙漠中的房子,超现实的风景) |  A dolphin leaps through the waves, set against a backdrop of bright blues and teal hues(一只海豚在海浪中跳跃,背景是明亮的蓝色和青色) A dolphin leaps through the waves, set against a backdrop of bright blues and teal hues(一只海豚在海浪中跳跃,背景是明亮的蓝色和青色) |  A panda swimming(一只正在游泳的熊猫) A panda swimming(一只正在游泳的熊猫) |
 A man wearing a fedora hat, street photography(一个戴着软呢帽的男人,街头摄影) A man wearing a fedora hat, street photography(一个戴着软呢帽的男人,街头摄影) |  Futuristic architecture(未来派建筑) Futuristic architecture(未来派建筑) |  Rabbit portrait in a forest, fantasy(森林里的兔子肖像,幻想) Rabbit portrait in a forest, fantasy(森林里的兔子肖像,幻想) |  Man portrait, ethereal(男子肖像,空灵) Man portrait, ethereal(男子肖像,空灵) |
 A tranquil park furnished with rows of benches made of marble(宁静的公园,配有一排排大理石长凳) A tranquil park furnished with rows of benches made of marble(宁静的公园,配有一排排大理石长凳) |  A photographer holding a camera, squatting by a lake, capturing the reflection of the mountains(摄影师拿着相机,蹲在湖边,捕捉山峦的倒影) A photographer holding a camera, squatting by a lake, capturing the reflection of the mountains(摄影师拿着相机,蹲在湖边,捕捉山峦的倒影) |  Mona Lisa, sketch(蒙娜丽莎,素描) Mona Lisa, sketch(蒙娜丽莎,素描) |  A ballerina with a smile, dressed in a strap dress, executing a pirouette in front of audiences(一位面带微笑、身着吊带裙的芭蕾舞演员在观众面前表演脚尖旋转) A ballerina with a smile, dressed in a strap dress, executing a pirouette in front of audiences(一位面带微笑、身着吊带裙的芭蕾舞演员在观众面前表演脚尖旋转) |
以下是我们的 2 步生成结果:
 Furniture design for a living room(客厅的家具设计) Furniture design for a living room(客厅的家具设计) |  A cinematic shot of a baby raccoon wearing an intricate Italian priest robe(电影镜头中一只小浣熊穿着精致的意大利牧师长袍) A cinematic shot of a baby raccoon wearing an intricate Italian priest robe(电影镜头中一只小浣熊穿着精致的意大利牧师长袍) |  A dog with soft fur and bright eyes jumping after a toy, in a cozy living room(一只毛发柔软、眼睛明亮的狗在舒适的客厅里追着玩具跳跃) A dog with soft fur and bright eyes jumping after a toy, in a cozy living room(一只毛发柔软、眼睛明亮的狗在舒适的客厅里追着玩具跳跃) |  A tea cup containing clouds(装云朵的茶杯) A tea cup containing clouds(装云朵的茶杯) |
|---|---|---|---|
 A handsome young man(一个英俊的年轻人) A handsome young man(一个英俊的年轻人) |  A family, medium shot(一家人,中景) A family, medium shot(一家人,中景) |  Baby playing with toys in the snow(婴儿在雪地里玩玩具) Baby playing with toys in the snow(婴儿在雪地里玩玩具) |  An old man and a dog are walking in the park(老人与狗在公园散步) An old man and a dog are walking in the park(老人与狗在公园散步) |
 Superman, close-up, modeling in Venice, Italy, with a confident smile(超人,特写,在意大利威尼斯当模特,带着自信的微笑) Superman, close-up, modeling in Venice, Italy, with a confident smile(超人,特写,在意大利威尼斯当模特,带着自信的微笑) |  A motorcycle outside the garage(在车库外的摩托车) A motorcycle outside the garage(在车库外的摩托车) |  Dragon driving a car(龙开车) Dragon driving a car(龙开车) |  A monkey making latte art.(一只猴子做咖啡拉花) A monkey making latte art.(一只猴子做咖啡拉花) |
与以前的方法(Turbo 和 LCM)相比,我们的方法生成的图像在细节上有显著改进,并且更忠实于原始生成模型的风格和布局。

回馈社区,开放模型
开源开放的浪潮已经成为推动人工智能迅猛发展的关键力量,字节跳动也自豪地成为这股浪潮的一部分。我们的模型基于目前最流行的文字生成图像开放模型 SDXL,该模型已经拥有一个繁荣的生态系统。现在,我们决定将 SDXL-Lightning 开放给全球的开发者、研究人员和创意从业者,以便他们能访问并运用这一模型,进一步推动整个行业的创新和协作。
在设计 SDXL-Lightning 时,我们就考虑到与开放模型社区的兼容。社区中已有众多艺术家和开发者创建了各种各样的风格化图像生成模型,例如卡通和动漫风格等。为了支持这些模型,我们提供 SDXL-Lightning 作为一个增速插件,它可以无缝地整合到这些多样风格的 SDXL 模型中,为各种不同模型加快图像生成的速度。

我们的模型也可以和目前非常流行的控制插件 ControlNet 相结合,实现极速可控的图片生成。

我们的模型也支持开源社区里目前最流行的生成软件 ComfyUI,模型可以被直接加载来使用:
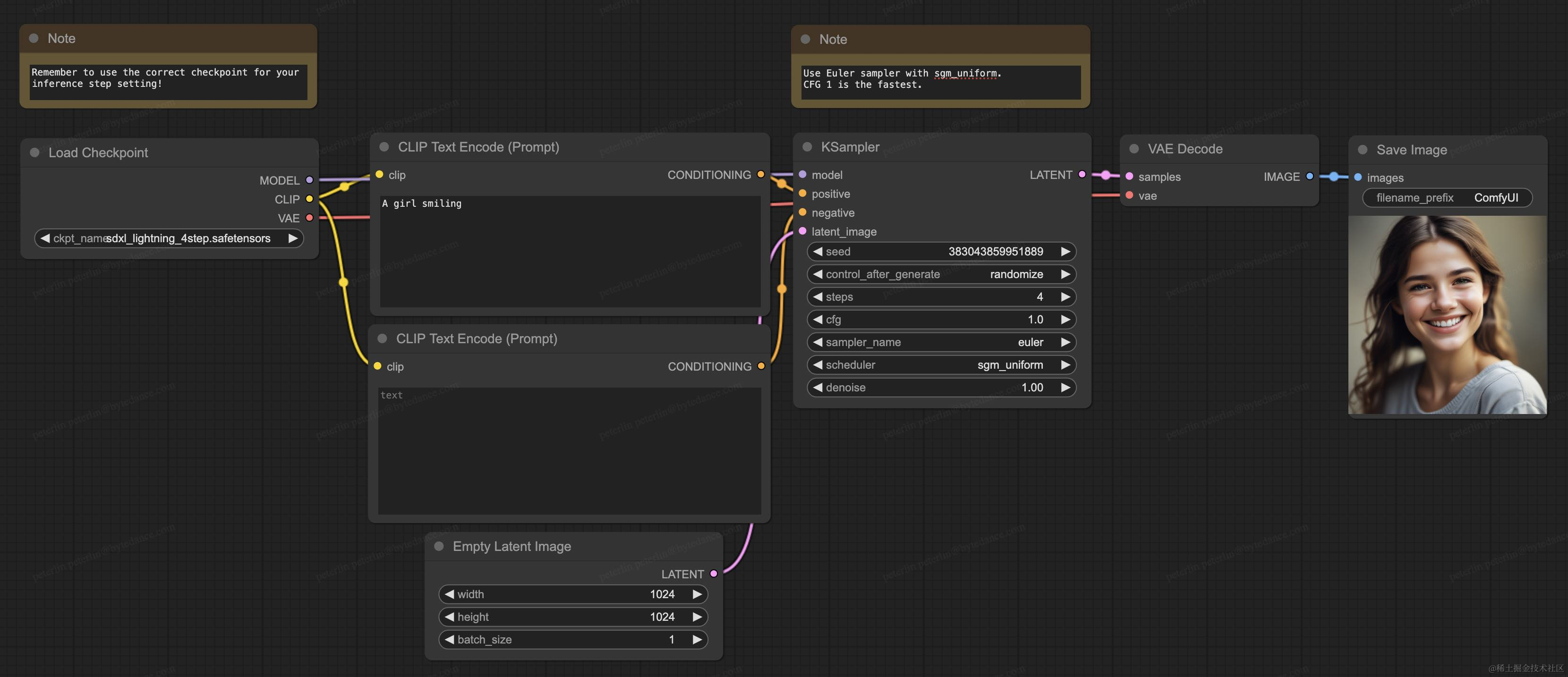
关于技术细节
从理论上来说,图像生成是一个由噪声到清晰图像的逐步转化过程。在这一过程中,神经网络学习在这个转化流(flow)中各个位置上的梯度。
生成图像的具体步骤是这样的:首先,我们在流的起点,随机采样一个噪声样本,接着用神经网络计算出梯度。根据当前位置上的梯度,我们对样本进行微小的调整,然后不断重复这一过程。每一次迭代,样本都会更接近最终的图像分布,直至获得一张清晰的图像。
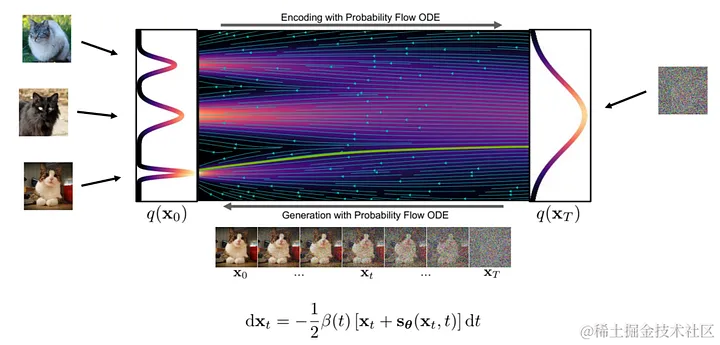
图:生成流程 ( 图片来自 : https://arxiv.org/abs/2011.13456 )
由于生成流复杂且非直线,生成过程必须一次只走一小步以减少梯度误差累积,所以需要神经网络的频繁计算,这就是计算量大的原因。

图:曲线流程 ( 图片来自 : https://arxiv.org/abs/2210.05475 )
为了减少生成图像所需的步骤数量,许多研究致力于寻找解决方案。一些研究提出了能减少误差的采样方法,而其他研究则试图使生成流更加直线化。尽管这些方法有所进展,但它们仍然需要超过 10 个推理步骤来生成图像。
另一种方法是模型蒸馏,它能够在少于 10 个推理步骤的情况下生成高质量图像。不同于计算当前流位置下的梯度,模型蒸馏改变模型预测的目标,直接让其预测下一个更远的流位置。具体来说,我们训练一个学生网络直接预测老师网络完成了多步推理的后的结果。这样的策略可以大幅减少所需的推理步骤数量。通过反复应用这个过程,我们可以进一步降低推理步骤的数量。这种方法被先前的研究称之为渐进式蒸馏。
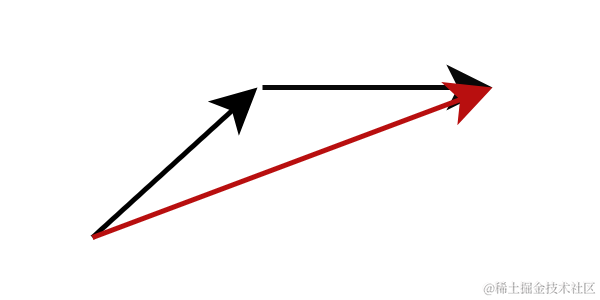
图:渐进式蒸馏 ,学生网络预测老师网络多步后的结果
在实际操作中,学生网络往往难以精确预测未来的流位置。误差随着每一步的累积而放大,导致在少于 8 步推理的情况下,模型产生的图像开始变得模糊不清。
为了解决这个问题,我们的策略是不强求学生网络精确匹配教师网络的预测,而是让学生网络在概率分布上与教师网络保持一致。换言之,学生网络被训练来预测一个概率上可能的位置,即使这个位置并不完全准确,我们也不会对它进行惩罚。这个目标是通过对抗训练来实现的,引入了一个额外的判别网络来帮助实现学生网络和教师网络输出的分布匹配。
这是我们研究方法的简要概述。在我们的技术论文(https://arxiv.org/abs/2402.13929)中,我们提供了更深入的理论分析、训练策略以及模型的具体公式化细节。
SDXL-Lightning 之外
尽管本研究主要探讨了如何利用 SDXL-Lightning 技术进行图像生成,但我们所提出的渐进式对抗蒸馏方法的应用潜力不局限于静态图像的范畴。这一创新技术也可以被运用于快速且高质量生成视频、音频以及其他多模态内容。我们诚挚邀请您在 HuggingFace 平台上体验 SDXL-Lightning,并期待您宝贵的意见和反馈。

