
- 1高性能内存对象缓存
- 2ES6——25、Module 的加载实现_esmodule 运行时动态
- 3LLMs之ChatGLM-2:ChatGLM2-6B的简介、安装、使用方法之详细攻略
- 4汽车自动泊车辅助系统APA(上)_apa寻库模块
- 5Can‘t update dev_zgd has no tracked branch_dev has no tracked branch
- 610 个能恢复硬盘丢失文件的数据恢复软件_prosoft data rescue
- 751单片机_电子时钟&电子万年历&电子闹钟_51单片机电子日历时钟
- 856、本地数据库迁移到阿里云
- 9ofbiz中使用事务处理
- 10【python小知识】python同一个函数并行计算_python 并行计算
华为学习记录3 Mindspore的基础使用操作_mindspore使用
赞
踩
常用的AI框架:
TensorFlow、pytorch、Keras、Mindspore、paddlepaddle
其中TensorFlow 0.x,1.x版本采用的是静态图,不容易debug;pytorch是动态图。
Mindspore有个mode选择,选择使用静态图还是动态图进行训练。
这里解释一下动态图和静态图的概念:

MindSpore静态图: Graph模式,可以通过set_context(mode=GRAPH_MODE),默认模式。
在Graph模式下,Mindspore通过源码转换的方式,将python的源码转换成IR(MindIR)再在此基础上进行相关的图优化,最终再硬件设备上执行优化后的图。
使用Graph模式时,需要使用nn.cell类并且在construcrt函数中编写执行代码,或者调用@ms_function装饰器。
Graph模式是基于MindIR进行编译优化的。
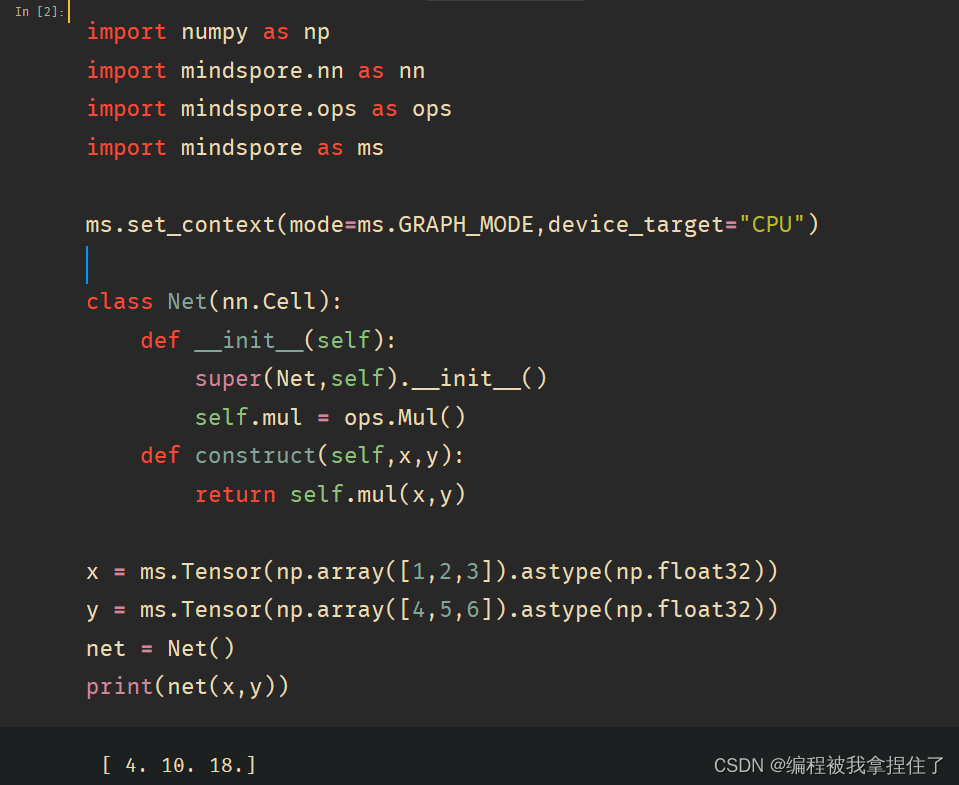
代码实现:
- import numpy as np
- import mindspore.nn as nn
- import mindspore.ops as ops
- import mindspore as ms
-
- ms.set_context(mode=ms.GRAPH_MODE,device_target="CPU")
-
- class Net(nn.Cell):
- def __init__(self):
- super(Net,self).__init__()
- self.mul = ops.Mul()
- def construct(self,x,y):
- return self.mul(x,y)
-
- x = ms.Tensor(np.array([1,2,3]).astype(np.float32))
- y = ms.Tensor(np.array([4,5,6]).astype(np.float32))
- net = Net()
- print(net(x,y))
我们加一下记录时间看看。
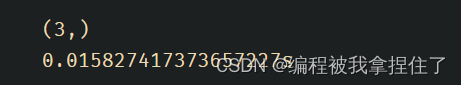
- t1 = time.time()
- ms.set_context(mode=ms.PYNATIVE_MODE,device_target="CPU") # 动态图
-
- x = ms.Tensor(np.ones([1,3,3,4]))
- y = ms.Tensor(np.ones([1,3,3,4]))
- z = ops.add(x,y)
- print(z.shape)
- print(f'{time.time()-t1}s')
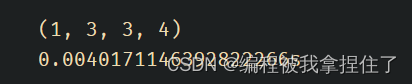
动态图是直接计算出结果的,在底层是没有做优化的,所以效率是不如静态图的.



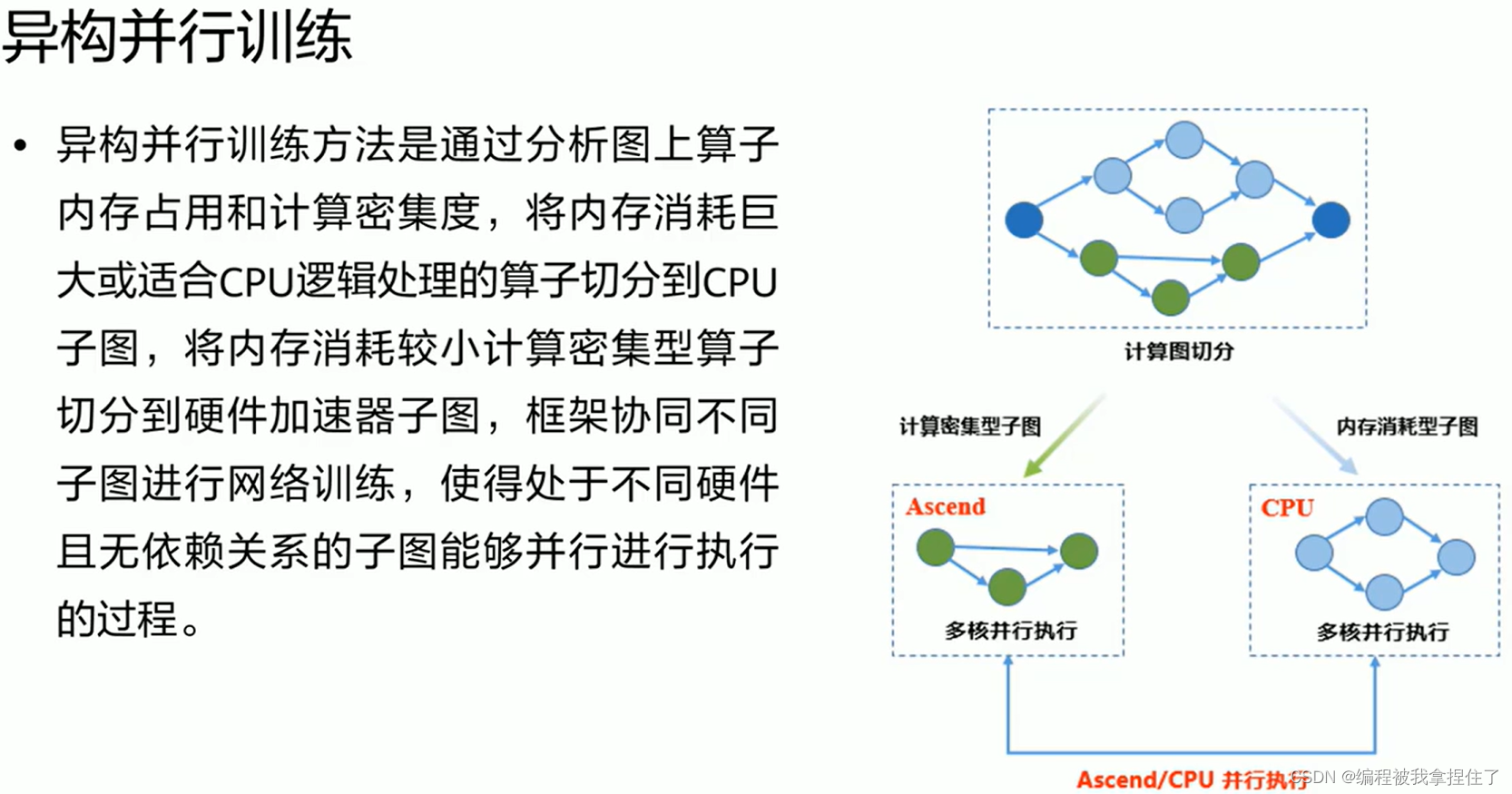
神经网络中的运算大部分是矩阵运算,还有一些其他运算, 所以会将不同的算子进行切分,将内存消耗大的切分到CPU,内存消耗小的密集型算子切分到硬件加速子图,框架协同不同子图进行网络训练,使得处于不同硬件且无依赖关系的子图能够并行进行执行的过程.
Mindspore中的开发组件:
1.推理部署流程
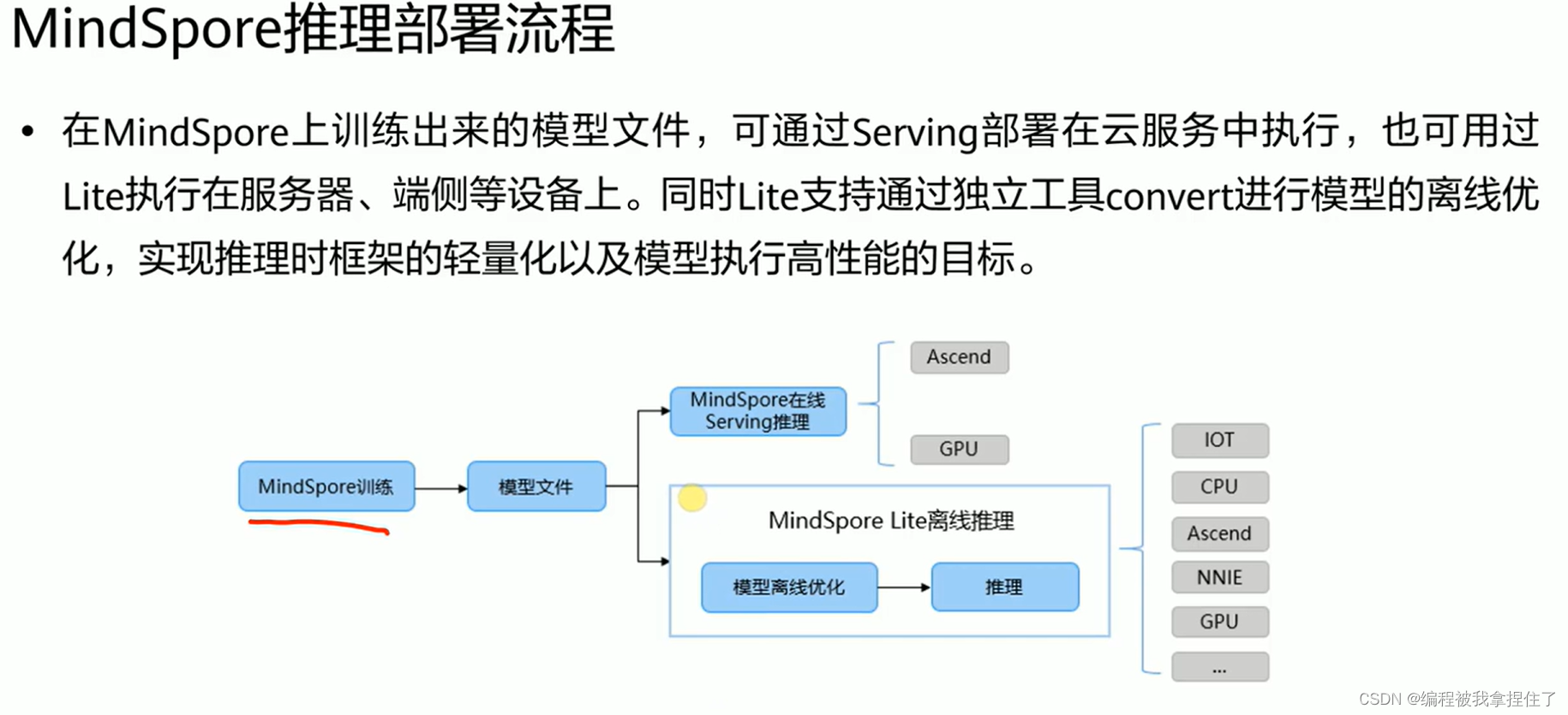
在线推理和离线推理.
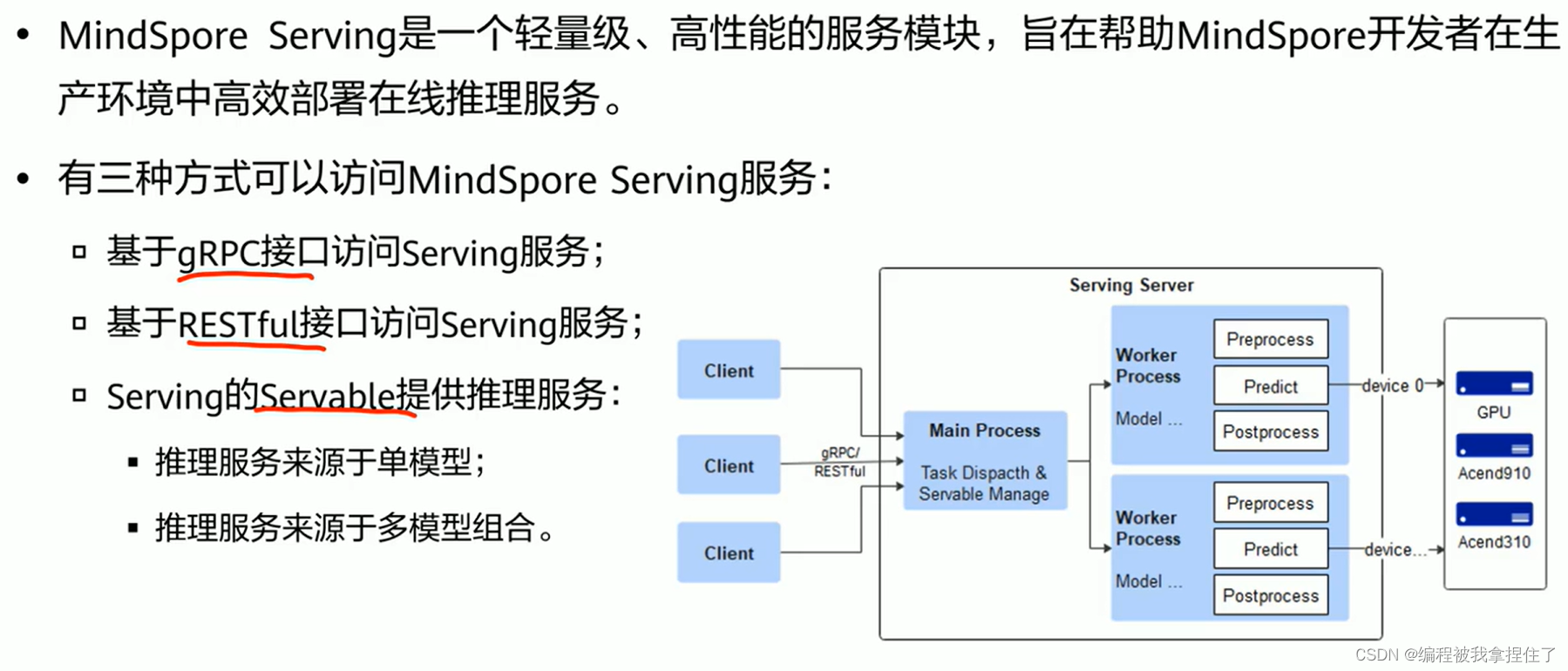
Serving:
使用方式:gRPC接口\RESTful接口\Servable
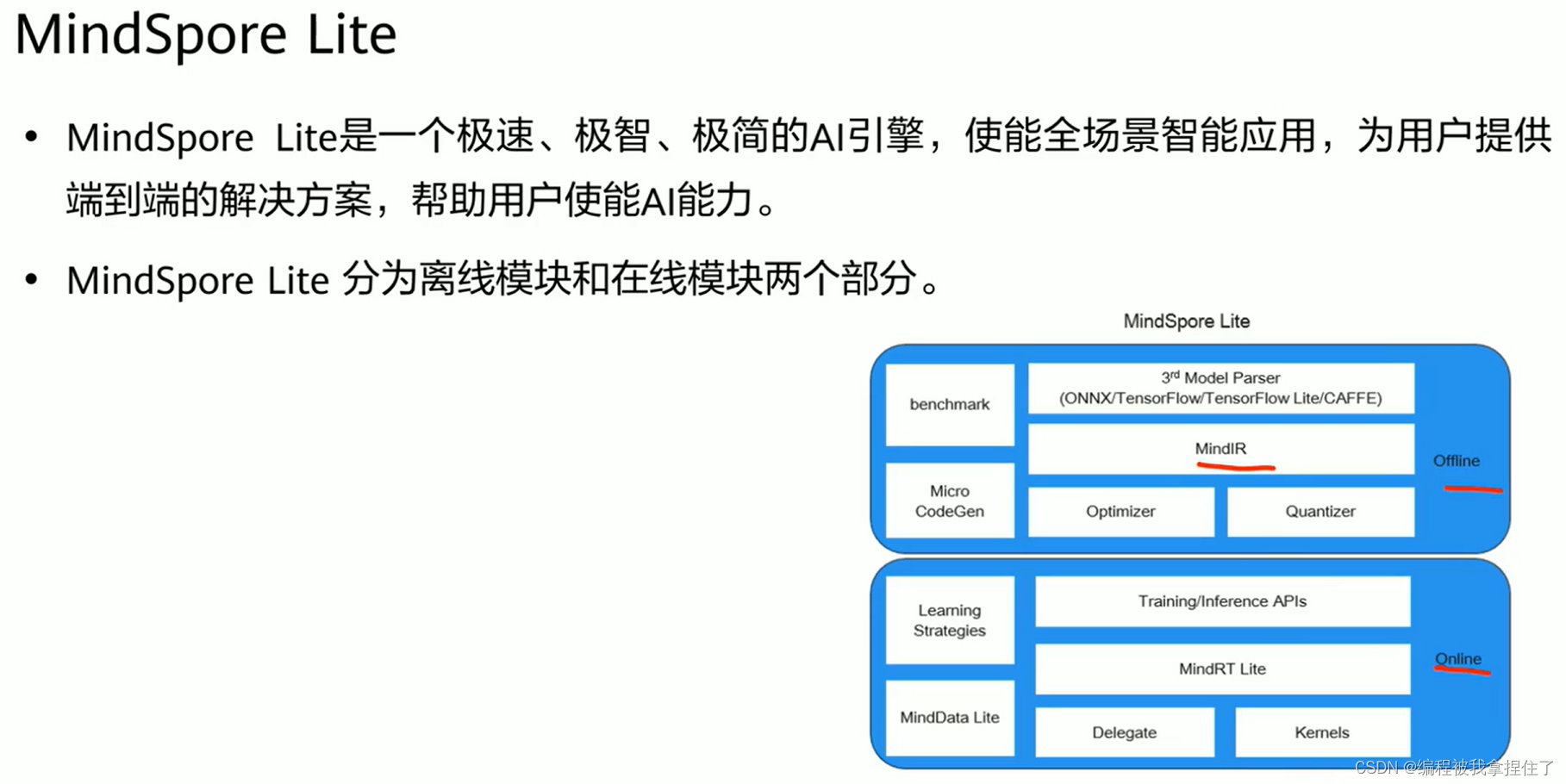
可视化:

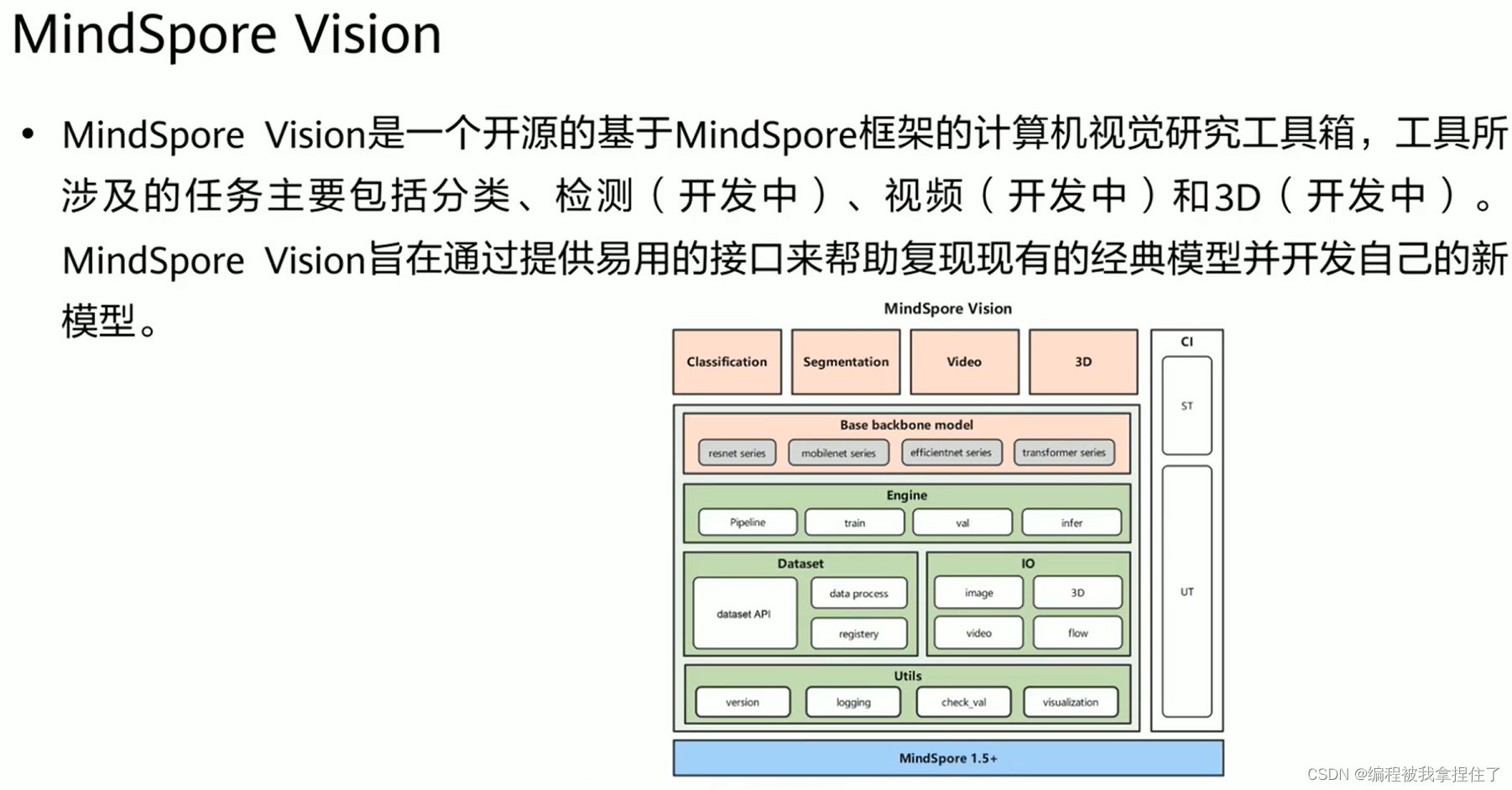
MindSpore Reinforcement: 开源的强化学习框架,支持使用强化学习算法对agent 进行分布式训练.
MindSpore Federated:联邦学习是一种加密的分布式机器学习技术,它可以支持机器学习的各参与方在不直接共享本地数据的前提下,共建AI模型.支持千万级五张太终端设备的商用化部署.



