
热门标签
热门文章
- 1内网渗透-隧道搭建&ssp隧道代理工具&frp内网穿透_spp代理工具
- 2java+GPT:通义千问_java通义千问接入 api的jar包
- 3MeterSphere本地化部署实践_metersphere本地部署
- 4物联网的崭新时代:AI驱动的智能世界
- 5OpenCvSharp从入门到实践-(04)色彩空间_opencvsharp cv2.cvtcolor
- 6SQL Server2019安装步骤+使用+解决部分报错+卸载(超详细 附下载链接)_sql2019安装教程图解
- 7Python AI 在几秒钟内为我生成了这些 Python 应用程序——它们有用吗?_ai写python代码
- 8ip地址是随时变动的吗?_ip地址会变吗
- 9RSA生成公私钥对springsecurity认证前的前台加密数据加解密_springsecurity rsa 解密
- 10关于十大黑客常用工具介绍
当前位置: article > 正文
探索和构建 LLaMA 3 架构:深入探讨组件、编码和推理技术(一)_llama3多模态调用的是什么组件
作者:我家自动化 | 2024-08-11 03:04:54
赞
踩
llama3多模态调用的是什么组件
探索和构建 LLaMA 3 架构:深入探讨组件、编码和推理技术(一)
Meta 通过推出新的开源 AI 模型 Llama 3 以及新版本的 Meta AI,正在加强其在人工智能 (AI) 竞赛中的竞争力。该虚拟助手由 Llama 3 提供支持,现已可在所有 Meta 平台上使用。
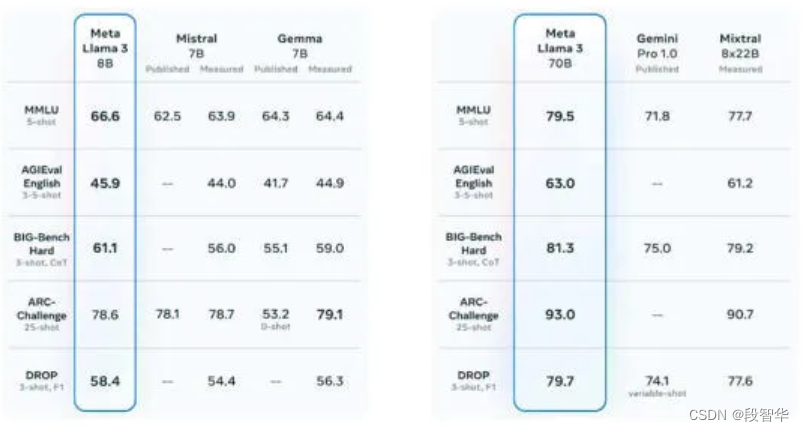
- Llama 3 是什么?:Meta 推出了 Llama 3,这是其 Llama 系列开源 AI 模型中的最新版本。 Llama 3 有两种变体:一种具有 80 亿个参数,另一种具有 700 亿个参数。Meta 声称 Llama 3 在这些参数尺度上为大型语言模型设立了新标准。他们改进了训练前和训练后流程,从而降低了错误拒绝率、更好的对齐以及模型的更多样化的响应。值得注意的是,Llama 3 拥有增强的推理、代码生成和指令跟踪能力。
LLaMA 架构:
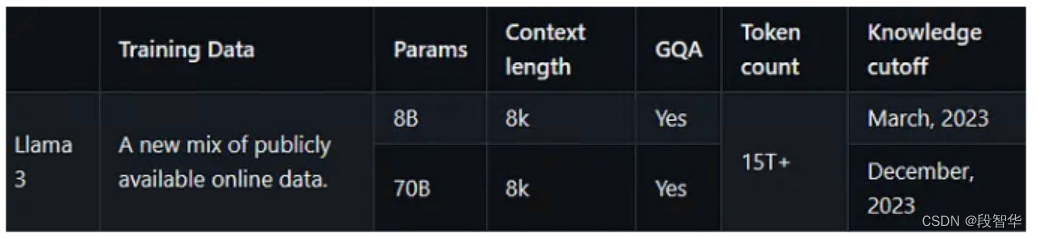
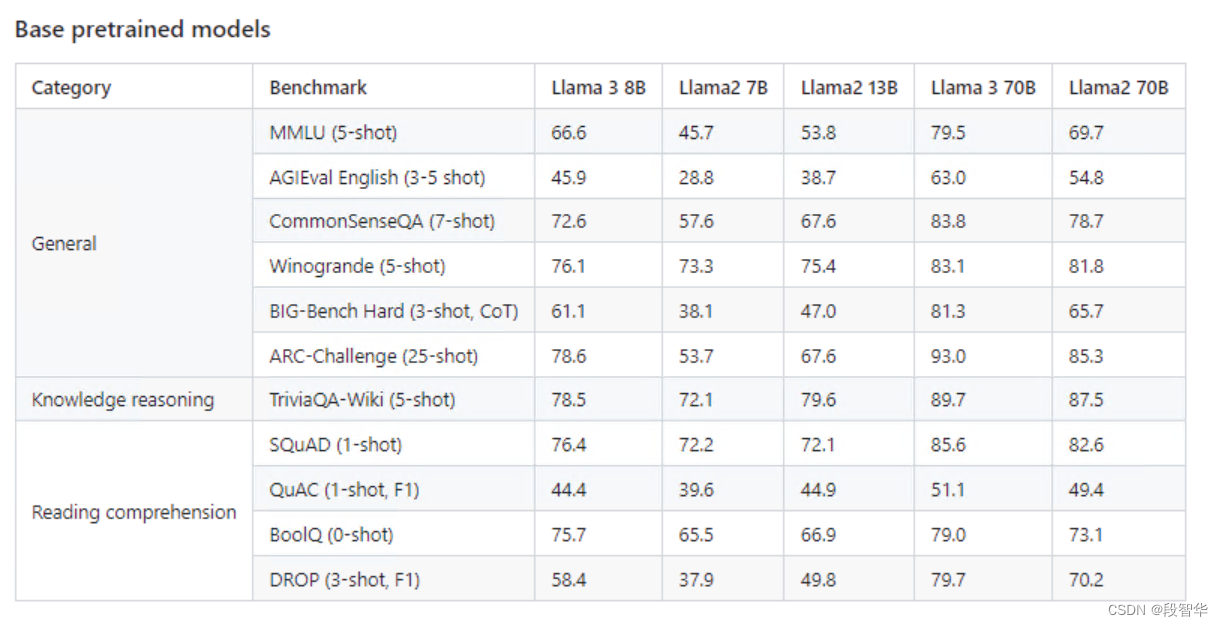
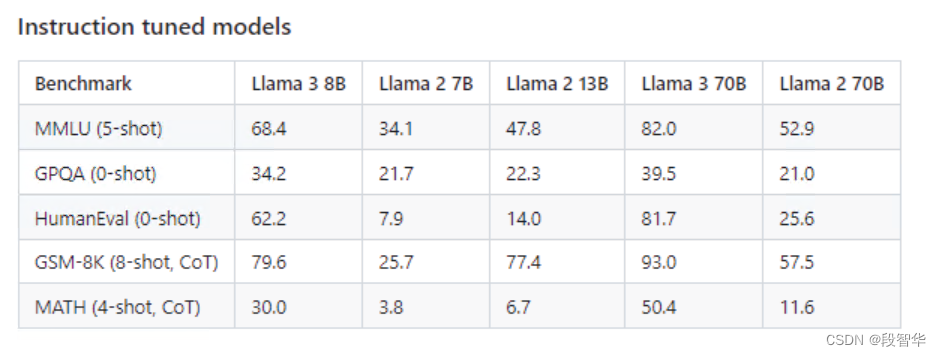
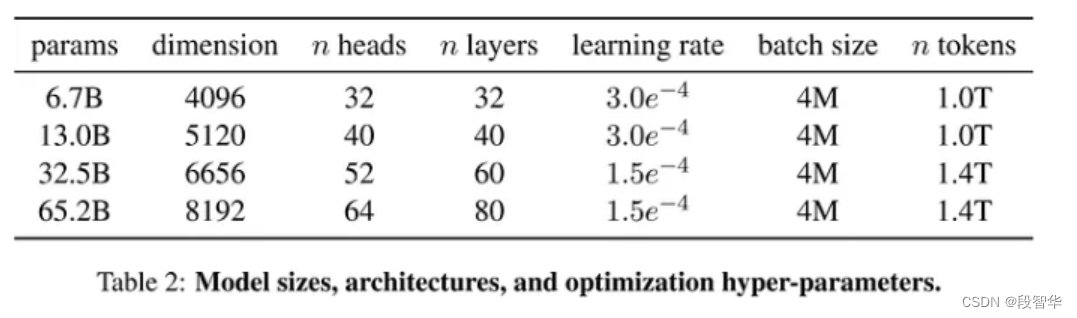
- 与前代模型之间的主要区别在于,预训练语料库的大小增加了 650% ,LLaMA 2 在 2T标记上进行训练,而 LLaMA 3 在 15T 标记上进行训练,模型的上下文长度从 4K 增加了一倍到 8K ,8B 和 70B 模型,并对 8B 和 70B 变体采用分组查询注意力,与上一代(GQA)相比,仅在更大的模型 34B 和 70B 中使用。最有影响力的部分是新的安全方法,包括安全和有用两种奖励模式。
Llama3 模型大小、架构、优化超参数
llama2 模型大小、架构、优化超参数
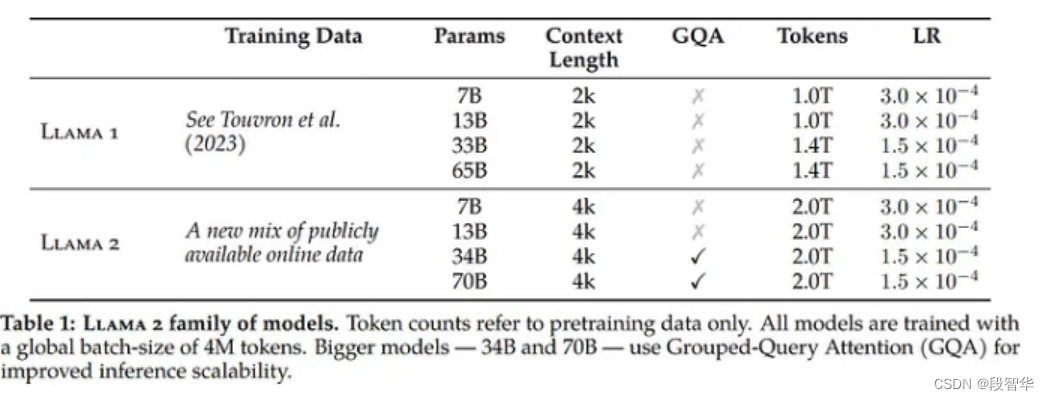
Llama1 参数
Llama架构
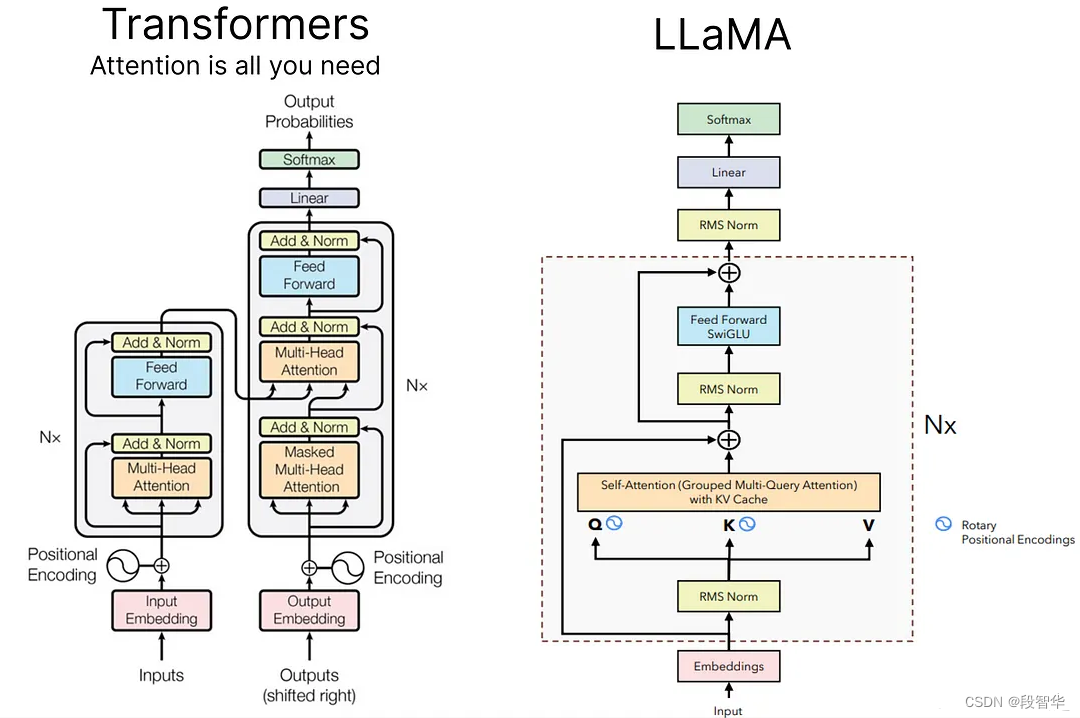
LLaMA 3 架构主要采用与 LLaMA 2 相同的架构,其中 GQA(分组查询注意)用于 8B 和 70B 模型,RoPE(旋转位置嵌入)用于 Q、K,因为 V 仅在应用 SoftMax 之前相乘函数,RMS(均方根误差)用于在 Self Attention 之前应用的归一化,前馈块,KV 缓存也与 LLMA 中使用的保持相同。注意:此模型架构仅专注于模型推理,而不是用于训练,因此具有交叉注意力的解码器块不会被覆盖,KV 缓存也不会用于模型的训练阶段。
大模型技术分享


声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/我家自动化/article/detail/961879
推荐阅读
相关标签

