
- 1Pandas中explode()函数的应用与实战_pandas explode
- 2java ppt控件_Java版PPT操作控件Spire.Presentation v3.3.5新版来袭!支持转换GroupShape到图片...
- 32024 信息安全毕业设计(论文)选题题目合集 最新版_信息安全专业毕业设计
- 4windows安装cuda 11.8以及tensorflow-gpu 2.6_cuda11.8对应的tensorflow
- 5练习时长 1 年 2 个月的 Java 菜鸡练习生最近面经,期望25K
- 6干货预警,企业级Android车载系统开发手册,开源分享!_android车载开发学习手册 百度网盘
- 7部署Pritunl
- 8机器学习参数寻优:方法、实例与分析
- 9iVX虽然是图形化编程,但“我们不一样”_psivx
- 10关于我用iVX沉浸式体验了一把0代码创建飞机大战这件事_ivx项目实例
毕业设计:新能源汽车数据分析可视化系统+爬虫(源码+文档)_汽车数据可视化系统
赞
踩
毕业设计:2023-2024年计算机专业毕业设计选题汇总(建议收藏)
毕业设计:2023-2024年最新最全计算机专业毕设选题推荐汇总
感兴趣的可以先收藏起来,还有大家在毕设选题,项目以及论文编写等相关问题都可以给我留言咨询,希望帮助更多的人 。
1、项目介绍
技术栈:
Python语言、Django框架 、MySQL数据库、Vue框架、Scrapy爬虫、Echarts可视化、懂车帝网数据
2、项目界面
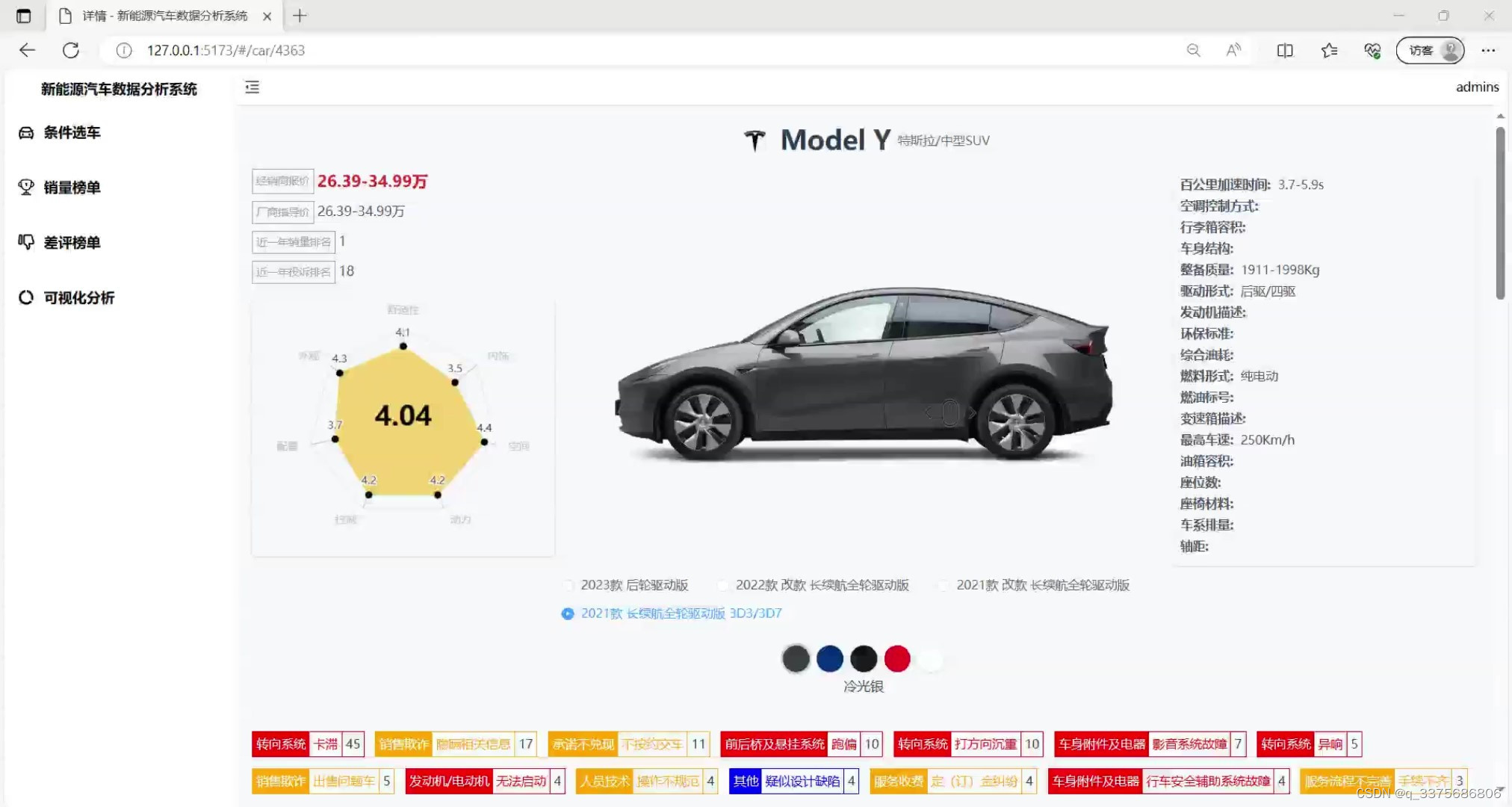
(1)车型详情页
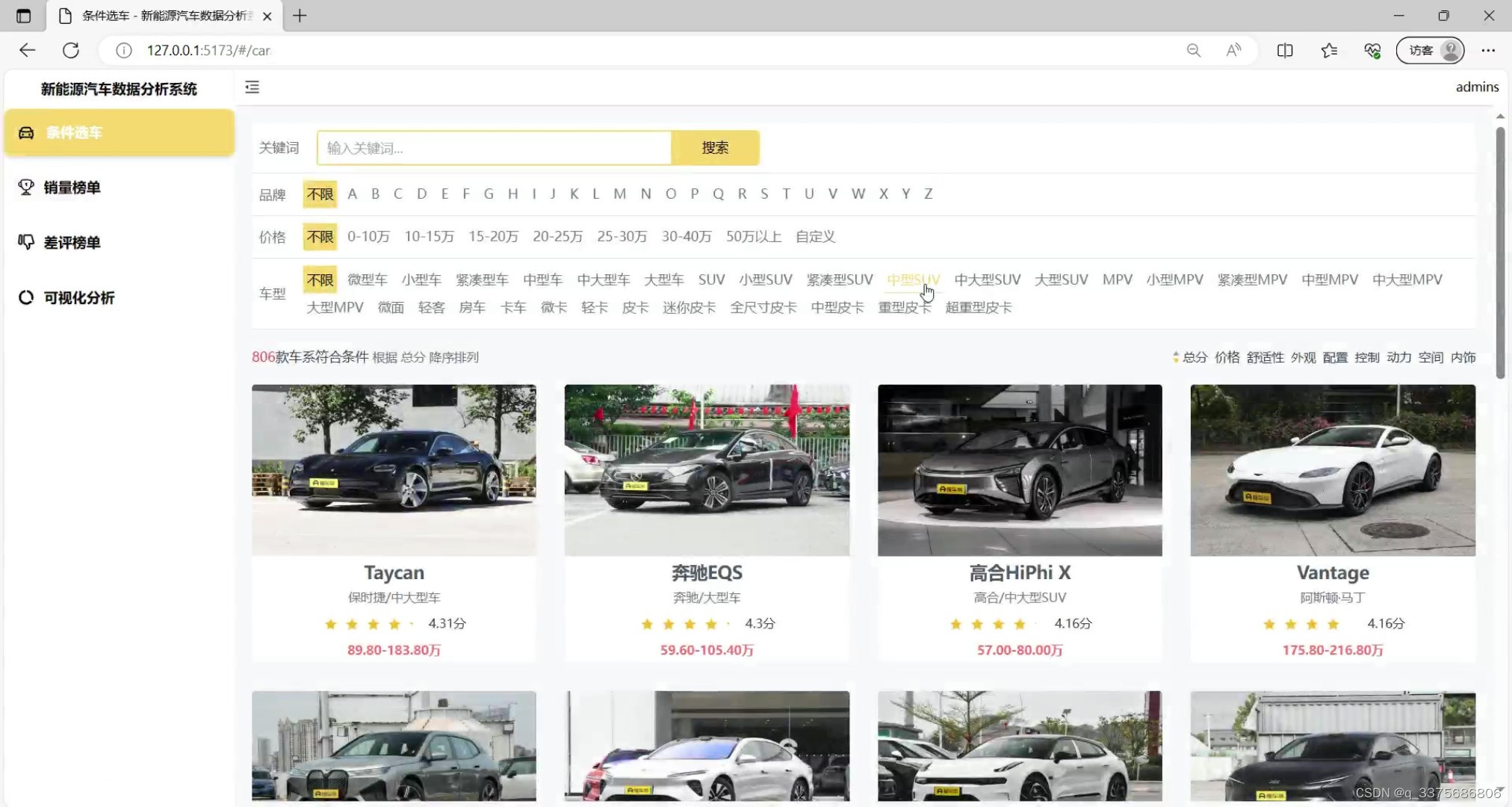
(2)新能源汽车条件筛选
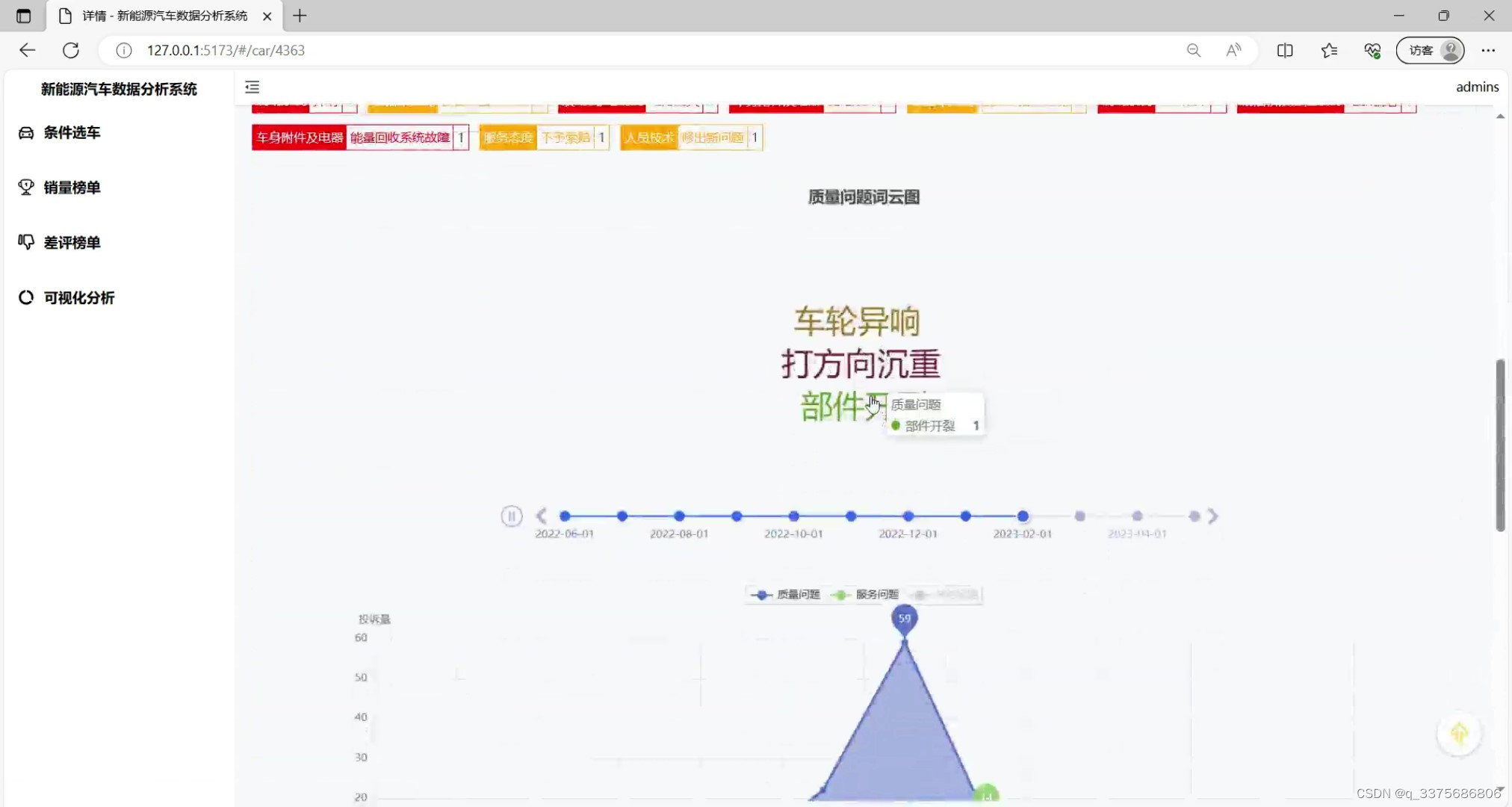
(3)新能源汽车车型分析
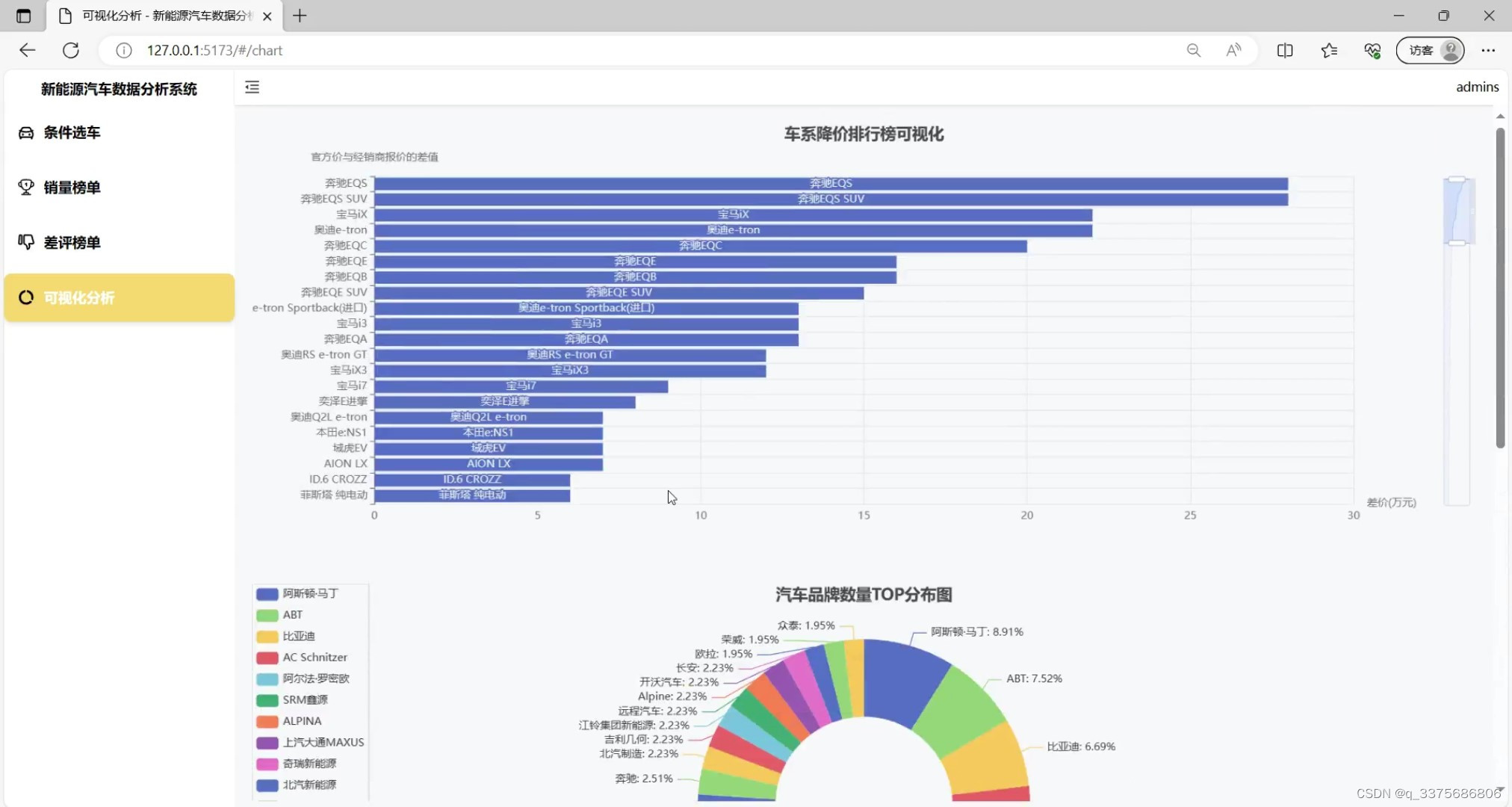
(4)新能源汽车数据可视化分析
(5)新能源汽车数据可视化分析(柱状图)
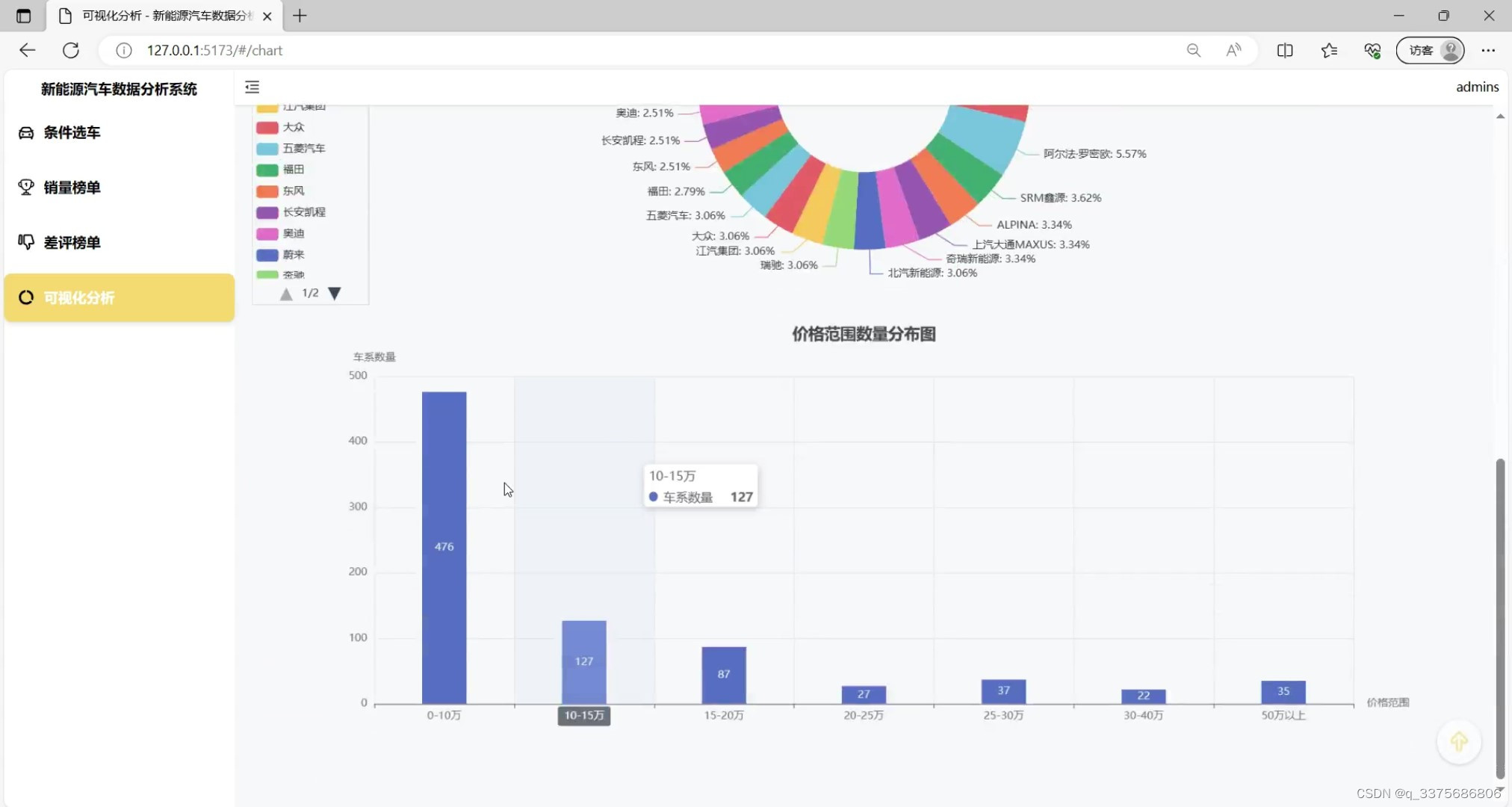
(6)新能源汽车销量榜单
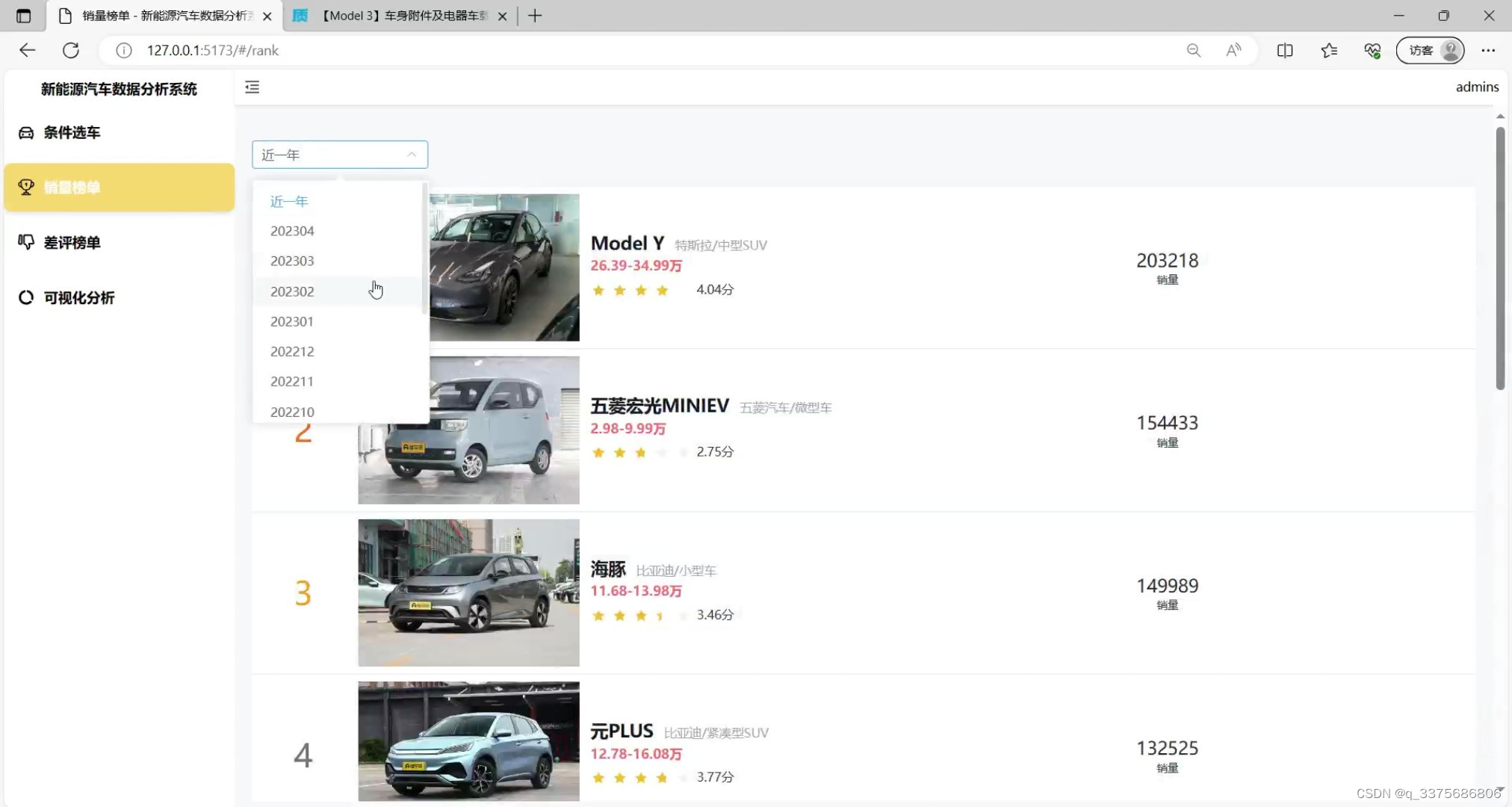
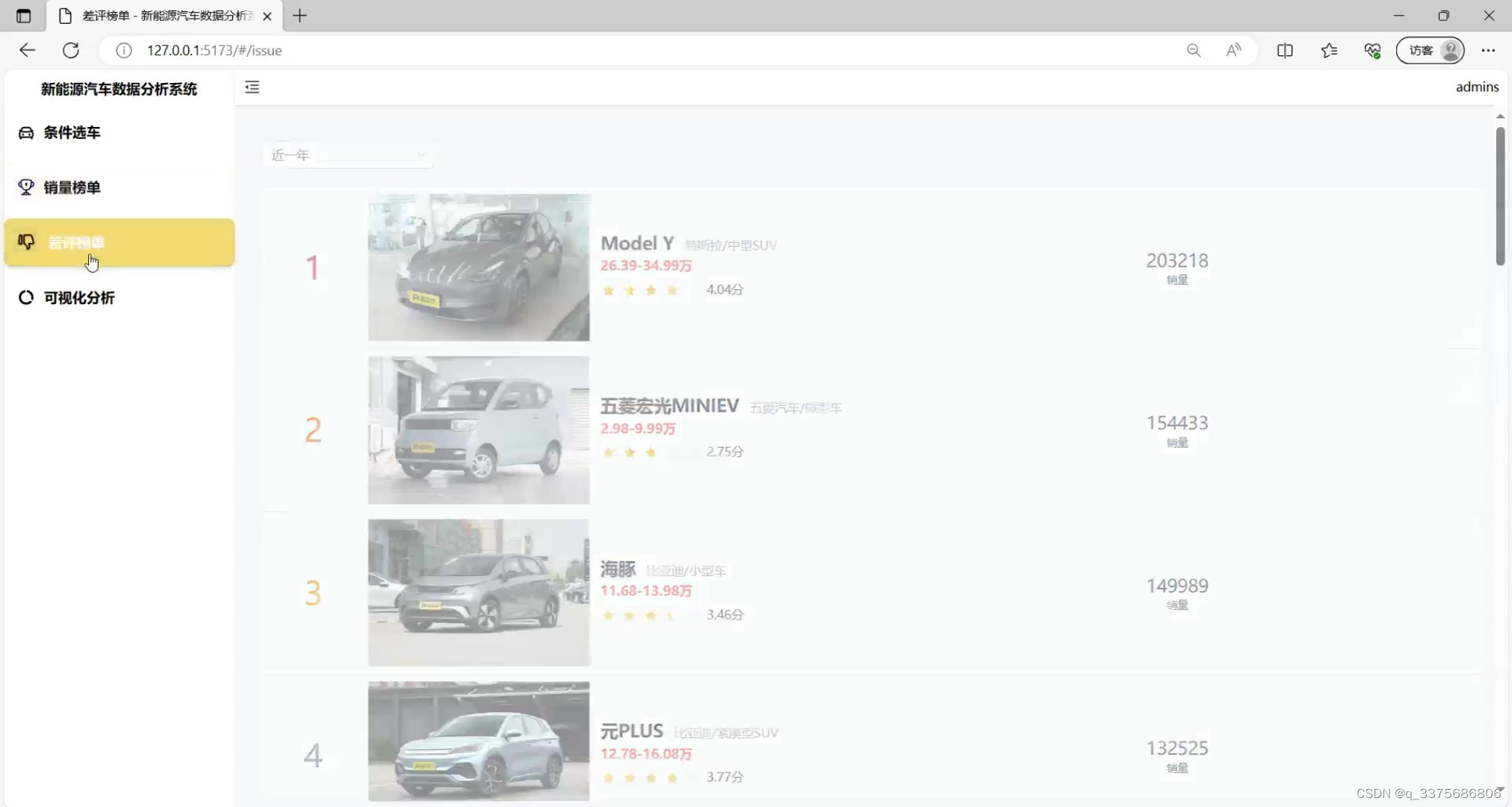
(7)新能源汽车差评榜单
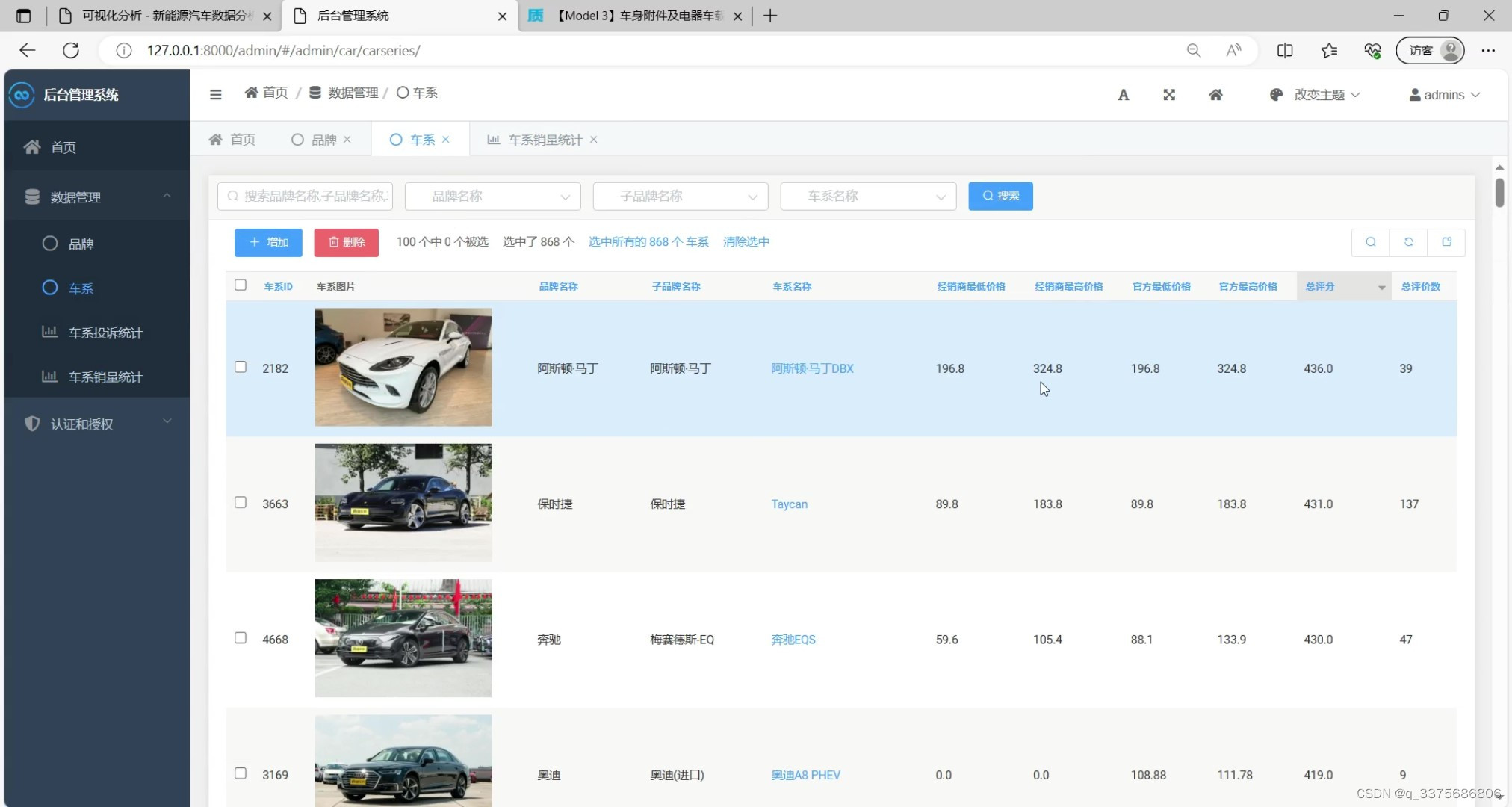
(8)新能源汽车数据后台管理
(9)车型销量统计
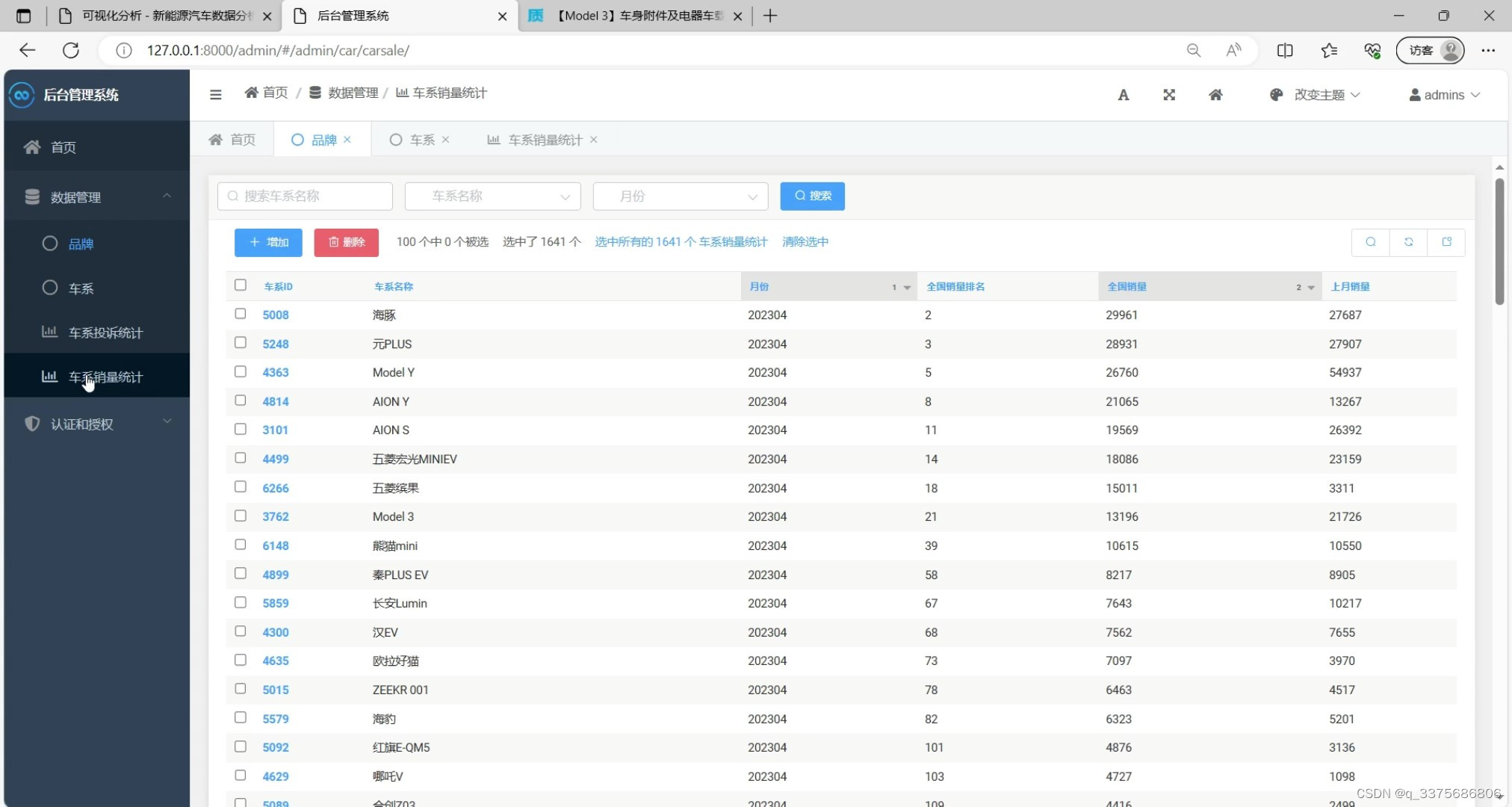
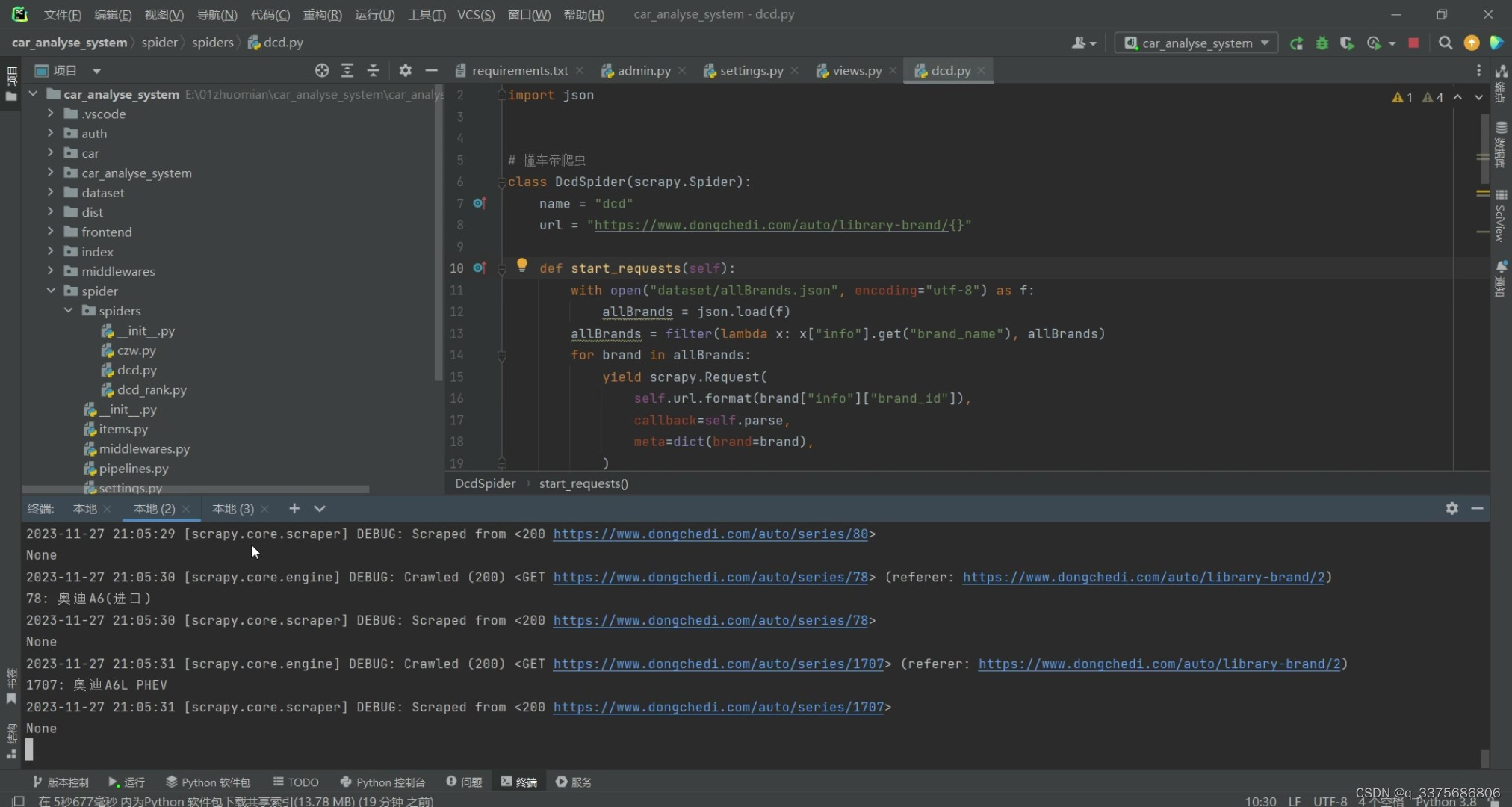
(10)数据采集页面
(11)注册登录界面
3、项目说明
基于Django框架和Vue框架的新能源汽车数据采集分析可视化系统是一个用于收集、分析和展示新能源汽车相关数据的系统。该系统利用Django框架作为后端开发工具,使用Vue框架构建前端界面,旨在为用户提供一个直观、易用的数据分析和可视化平台。
该系统的主要功能包括数据采集、数据处理、数据分析和数据可视化。首先,系统通过与新能源汽车相关的传感器和设备进行连接,实时采集各种数据,例如电池状态、充电效率和车辆行驶数据等。然后,系统将采集到的原始数据进行预处理和清洗,以确保数据的准确性和完整性。
接下来,系统利用分析算法和模型对数据进行分析,提取出有价值的信息和洞察,并生成相应的报告和图表。用户可以根据自己的需求选择不同的分析方法和指标,以深入了解新能源汽车的性能和效率。
最后,系统通过可视化方式将分析结果展示给用户。用户可以通过直观的图表、图形和地图来查看数据的趋势、变化和关联性。此外,系统也提供了交互式的功能,用户可以根据自己的兴趣和需求进行数据的筛选、排序和比较。
总之,基于Django框架和Vue框架的新能源汽车数据采集分析可视化系统是一个功能强大、易用的工具,能够帮助用户深入理解和分析新能源汽车相关数据,为相关领域的决策提供支持。
4、部分代码
def to_dict(l, exclude=tuple(), single=False): # 将数据库模型 变为 字典数据 的工具类函数 def transform(v): if isinstance(v, datetime): return v.strftime("%Y-%m-%d %H:%M:%S") return v def _todict(obj): j = { k: transform(v) for k, v in obj.__dict__.items() if not k.startswith("_") and k not in exclude } return j if single: return _todict(l) return [_todict(i) for i in l] def all_grouped_brands(request): """ 返回按拼音分组的所有品牌的JSON响应。 Args: request (HttpRequest): HTTP请求对象。 Returns: JsonResponse: 按拼音分组的所有品牌的JSON响应。 """ # 获取请求数据 data = request.json # 获取所有品牌并转换为字典 brands = to_dict(Brand.objects.all().order_by("pinyin", "-on_sale_series_count")) # 按拼音分组品牌 result = [(i[0], list(i[1])) for i in groupby(brands, key=lambda x: x["pinyin"])] # 返回JSON响应 return JsonResponse(result, safe=False) def query_car_series(request): """根据请求参数查询车系。 Args: request (HttpRequest): HTTP请求。 Returns: JsonResponse: 包含车系的JSON响应。 """ # 获取请求参数 body = request.json pagesize = body.get("pagesize", 10) page = body.get("page", 1) exclude_fields = ["pagesize", "page", "total", "orderby"] orderby = body.get("orderby") # 从请求参数构建查询 query = {k: v for k, v in body.items() if k not in exclude_fields and v} q = Q(**query) # 获取车系对象并对结果进行分页 objs = CarSeries.objects.filter(q).order_by(orderby) paginator = Paginator(objs, pagesize) # 获取指定页面并将结果转换为字典列表 try: pg = paginator.page(page) result = list(pg.object_list) except Exception as e: result = [] result = to_dict(result) # 将结果作为JSON响应返回 return JsonResponse({"total": paginator.count, "records": result}) def lasted_sales_rank_months(request): months = list( CarSale.objects.values_list("month", flat=True) .order_by("-month") .distinct()[:24] ) return JsonResponse(months, safe=False) def lasted_sales_issue_months(request): months = list( CarIssue.objects.values_list("stime", flat=True) .order_by("-stime") .distinct()[:24] ) return JsonResponse(months, safe=False) def car_rank(request): body = request.json id = body.get("id") return _car_rank(id) @lru_cache() def _car_rank(id): # 获取当前日期及1年前的日期 today = datetime.now().date() one_year_ago = today - timedelta(days=365) # 设置查询条件 q = Q(month__gte=one_year_ago.strftime("%Y%m"), month__lte=today.strftime("%Y%m")) result = ( CarSale.objects.filter(q) .values("series_id", "series_name") .annotate(total_sales=Sum("rank_value")) .filter(total_sales__gt=0) .order_by("-total_sales") ) sales_rank = next( ( i for i, e in enumerate( result, start=1, ) if e["series_id"] == int(id) ), -1, ) # --------- # 获取当前日期及1年前的日期 q = Q( stime__gte=one_year_ago.strftime("%Y-%m-%d"), stime__lte=today.strftime("%Y-%m-%d"), ) result = ( CarIssue.objects.filter(q) .values("series_id", "series_name") .annotate(total_issues=Sum("count")) .filter(total_issues__gt=0) .order_by("-total_issues") ) issue_rank = next( ( i for i, e in enumerate( result, start=1, ) if e["series_id"] == int(id) ), -1, ) return JsonResponse(dict(sales_rank=sales_rank, issue_rank=issue_rank)) def car_sales_rank(request): # 获取请求体中的数据 body = request.json # 获取请求体中的月份 month = body.get("month") # 定义查询条件 q = Q() # 根据月份设置查询条件 if month == "1y": # 获取当前日期及1年前的日期 today = datetime.now().date() one_year_ago = today - timedelta(days=365) # 设置查询条件 q &= Q( month__gte=one_year_ago.strftime("%Y%m"), month__lte=today.strftime("%Y%m") ) elif month == "6m": # 近半年,即6个月 today = datetime.now().date() half_year_ago = today - timedelta(days=365 // 2) # 设置查询条件 q &= Q( month__gte=half_year_ago.strftime("%Y%m"), month__lte=today.strftime("%Y%m") ) else: q &= Q(month=month) # 统计各个车系一年内的总销量,并按照销量进行排序和排名 result = ( CarSale.objects.filter(q) .values("series_id", "series_name") .annotate(total_sales=Sum("rank_value")) .order_by("-total_sales") ) # 对结果进行排名 result_list = list(result) for i, item in enumerate(result_list): item["sales_rank"] = i + 1 # 分页处理数据 pagesize = body.get("pagesize", 20) page_num = body.get("page", 1) paginator = Paginator(result_list, pagesize) # 创建Paginator对象 page = paginator.get_page(page_num) # 获取指定页码的数据 result = list(page.object_list) # 获取每个车系的详细信息,并将其添加到结果中 for i in result: car_series = to_dict([CarSeries.objects.get(series_id=i["series_id"])])[0] i.update(**car_series) # 返回分页后的结果 return JsonResponse({"total": paginator.count, "records": result}) def car_issue_rank(request): body = request.json stime = body.get("stime") type = body.get("type") q = Q() if stime == "1y": # 获取当前日期及1年前的日期 today = datetime.now().date() one_year_ago = today - timedelta(days=365) q &= Q( stime__gte=one_year_ago.strftime("%Y-%m-%d"), stime__lte=today.strftime("%Y-%m-%d"), ) elif stime == "6m": # 近半年,即6个月 today = datetime.now().date() half_year_ago = today - timedelta(days=365 // 2) q &= Q( stime__gte=half_year_ago.strftime("%Y-%m-%d"), stime__lte=today.strftime("%Y-%m-%d"), ) else: q &= Q(stime=stime) if type: q &= Q(type=type) # 统计各个车系一年内的总问题数,并按照问题数进行排序和排名 result = ( CarIssue.objects.filter(q) .values("series_id", "series_name") .annotate(total_issues=Sum("count")) .order_by("-total_issues") ) # 对结果进行排名 result_list = list(result) for i, item in enumerate(result_list): item["issues_rank"] = i + 1 # 分页处理数据 pagesize = body.get("pagesize", 20) page_num = body.get("page", 1) paginator = Paginator(result_list, pagesize) # 创建Paginator对象 page = paginator.get_page(page_num) # 获取指定页码的数据 result = list(page.object_list) for i in result: car_series = to_dict([CarSeries.objects.get(series_id=i["series_id"])])[0] counter = Counter() for x in CarIssue.objects.filter(q, series_id=i["series_id"]).values_list( "dxwt", flat=True ): counter.update(dict([(j["ctiTitle"], j["count"]) for j in x])) i["issues"] = counter.most_common(10) i.update(**car_series) return JsonResponse({"total": paginator.count, "records": result})

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
- 122
- 123
- 124
- 125
- 126
- 127
- 128
- 129
- 130
- 131
- 132
- 133
- 134
- 135
- 136
- 137
- 138
- 139
- 140
- 141
- 142
- 143
- 144
- 145
- 146
- 147
- 148
- 149
- 150
- 151
- 152
- 153
- 154
- 155
- 156
- 157
- 158
- 159
- 160
- 161
- 162
- 163
- 164
- 165
- 166
- 167
- 168
- 169
- 170
- 171
- 172
- 173
- 174
- 175
- 176
- 177
- 178
- 179
- 180
- 181
- 182
- 183
- 184
- 185
- 186
- 187
- 188
- 189
- 190
- 191
- 192
- 193
- 194
- 195
- 196
- 197
- 198
- 199
- 200
- 201
- 202
- 203
- 204
- 205
- 206
- 207
- 208
- 209
- 210
- 211
- 212
- 213
- 214
- 215
- 216
- 217
- 218
- 219
- 220
- 221
- 222
- 223
- 224
- 225
- 226
- 227
- 228
- 229
- 230
- 231
- 232
- 233
- 234
- 235
- 236
- 237
- 238
- 239
- 240
- 241
- 242
- 243
- 244
- 245
- 246
- 247
- 248
- 249
- 250
- 251
- 252
- 253
- 254
- 255
- 256
- 257
- 258
- 259
- 260
- 261
- 262
- 263
- 264
- 265
- 266
- 267
- 268
源码获取:
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/木道寻08/article/detail/746694
Copyright © 2003-2013 www.wpsshop.cn 版权所有,并保留所有权利。

