
热门标签
热门文章
- 1【机器学习】KNN实现鸢尾花分类_# 对ndarray数组进行遍历,每次取数组中的一行。 # 对于测试集中的每一个样本,依次
- 2区块链入门的几个基本问题_比特币一个区块交易全部完成后才能计算下一个区块
- 3windows10下操作HDFS报错:Failed to locate the winutils binary in the hadoop binary path(防坑篇)
- 4Python学习_案例:提取列表中的大值和最小值(三种方式)_python中列表怎么求最大值最小值
- 5鸿蒙星河版笔记来袭!布局元素、边框、圆角等附案例_鸿蒙boder
- 6Docker网络详解_docker 网络
- 7Docker安装MinIO_docker 安装minio
- 8C#数据结构与算法揭秘二
- 9微信小程序 - 云开发_微信小程序云开发
- 10chatgpt赋能python:Python列表排序方法_python123二维列表排序
当前位置: article > 正文
基于YOLOV8-pose的自动标注_yolov8 自动标注
作者:木道寻08 | 2024-06-26 08:12:23
赞
踩
yolov8 自动标注
解析JSON文件
- {
- "version": "5.1.1", # 字典
- "flags": {}, # 字典
- "shapes": [ # 列表嵌套字典
- {
- "label": "person", # 字典
- "points": [ # 字典
- [
- 1184.0,
- 145.0
- ],
- [
- 1563.0,
- 743.0
- ]
- ],
- "group_id": 1, # 字典
- "shape_type": "rectangle", # 字典
- "flags": {} # 字典
- },
- {
- "label": "0",
- "points": [
- [
- 1519.164794921875,
- 211.12527465820312
- ]
- ],
- "group_id": 1,
- "shape_type": "point", #区别 框的话是rectangle 点的话就是point
- "flags": {}
- },
- ......
- {
- "label": "16",
- "points": [
- [
- 1305.552734375,
- 662.0692138671875
- ]
- ],
- "group_id": 1,
- "shape_type": "point",
- "flags": {}
- }
- ],
- "imagePath": "22112622_003270.jpg", # 字典 文件名
- "imageData": "......." # base64编码 最重要的一项
- "imageHeight": 1080, # 照片高 字典
- "imageWidth": 1920 # 照片宽 字典
- }
现在解析了JSON,之后就要分析怎么在yolov8-pose中取出我想要的值
从YOLOV8-pose取出对应的信息
- def postprocess(self, preds, img, orig_imgs):
- """Return detection results for a given input image or list of images."""
-
- preds = ops.non_max_suppression(preds,
- self.args.conf,
- self.args.iou,
- agnostic=self.args.agnostic_nms,
- max_det=self.args.max_det,
- classes=self.args.classes,
- nc=len(self.model.names))
-
- if not isinstance(orig_imgs, list): # input images are a torch.Tensor, not a list
- orig_imgs = ops.convert_torch2numpy_batch(orig_imgs)
- torch.set_printoptions(sci_mode=False)
-
- results = []
- for i, pred in enumerate(preds):
- orig_img = orig_imgs[i]
- # 对应的全部信息
- pred[:, :4] = ops.scale_boxes(img.shape[2:], pred[:, :4], orig_img.shape).round()
- # 对应的点坐标
- pred_kpts = pred[:, 6:].view(len(pred), *self.model.kpt_shape) if len(pred) else pred[:, 6:]
- pred_kpts = ops.scale_coords(img.shape[2:], pred_kpts, orig_img.shape)
- img_path = self.batch[0][i]
- results.append(
- Results(orig_img, path=img_path, names=self.model.names, boxes=pred[:, :6], keypoints=pred_kpts))
-
- return results
上述代码在 ultralytics/ultralytics/models/yolo/pose/predict.py中
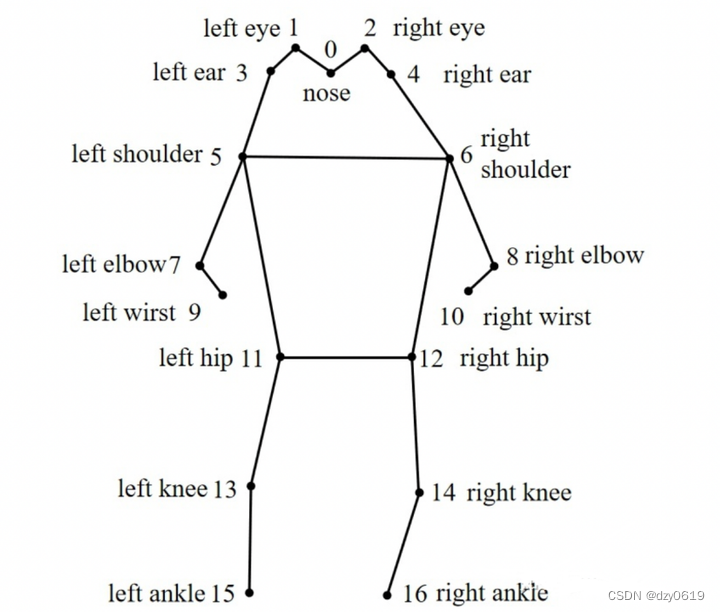
yolov8-pose骨架信息图
可以根据此骨架关键点去做修改,改成自己需要的骨架信息
实现标注自动化
一张图片对应一个JSON文件,后面会有所改变,但是前面都一样,所以可以先把大概的轮廓搭建起来
- # 创建一个字典
- # 把原始字节码编码成base64字节码
- base64_bytes = base64.b64encode(byte_content)
-
- # 把base64字节码解码成utf-8格式的字符串
- base64_string = base64_bytes.decode('utf-8')
- data = {
-
- "version": "5.1.1",
- "flags": {},
- "shapes": [
-
- ]
- }
- json_data = json.dumps(data, indent=4)
- # img_path在源代码有 是图片的绝对路径
- #这里是为了imagePath做准备以及保证保存的JSON文件与原文件同名
- imgName = img_path.split("/")[-1]
- savePath = "/home/test/fall/" + imgName.split(".")[0] + ".json"
- #将上述的字典写入我们创建的json文件中
- with open(savePath, 'w') as file:
- file.write(json_data)
那么接下来就是将点的信息、框的信息写入到json文件中
- for j in range(pred.shape[0]):
- # 将字典转换为JSON格式
- # 打开文件,并将JSON数据写入文件
- with open(savePath, 'r') as f:
- data = json.load(f)
- # 在字典列表中插入新的字典
- # 更新组信息
- bbox = {"label": "person", 'points': [[float(pred[j][0].item()), float(pred[j][1].item())],
- [float(pred[j][2].item()), float(pred[j][3].item())]], "group_id": (j + 1),
- "shape_type": "rectangle", "flags": {}}
- data['shapes'].append(bbox)
- data.update({"imagePath": imgName})
- data.update({"imageData": base64_string})
- # data.update({"imageData": str(base64.b64encode(open(img_path, "rb").read()))})
- data.update({"imageHeight": orig_img.shape[0]})
- data.update({"imageWidth": orig_img.shape[1]})
- for i in range(17):
- if float(pred_kpts[j][i][2].item()) > 0.5:
- # print(float(pred_kpts[:, i, 0]), float(pred_kpts[:, i, 1]))
- keypoints = {'label': str(i),
- 'points': [[float(pred_kpts[j][i][0].item()), float(pred_kpts[j][i][1].item())]],
- 'group_id': (j + 1), 'shape_type': 'point', 'flags': {}}
-
-
- data['shapes'].append(keypoints)
- # 将更新后的数据写回到JSON文件
- with open(savePath, 'w') as f:
- json.dump(data, f, indent=4)
完整代码
- def postprocess(self, preds, img, orig_imgs):
- """Return detection results for a given input image or list of images."""
-
- preds = ops.non_max_suppression(preds,
- self.args.conf,
- self.args.iou,
- agnostic=self.args.agnostic_nms,
- max_det=self.args.max_det,
- classes=self.args.classes,
- nc=len(self.model.names))
-
- if not isinstance(orig_imgs, list): # input images are a torch.Tensor, not a list
- orig_imgs = ops.convert_torch2numpy_batch(orig_imgs)
- torch.set_printoptions(sci_mode=False)
-
- results = []
- for i, pred in enumerate(preds):
- orig_img = orig_imgs[i]
- pred[:, :4] = ops.scale_boxes(img.shape[2:], pred[:, :4], orig_img.shape).round()
-
- pred_kpts = pred[:, 6:].view(len(pred), *self.model.kpt_shape) if len(pred) else pred[:, 6:]
- pred_kpts = ops.scale_coords(img.shape[2:], pred_kpts, orig_img.shape)
- img_path = self.batch[0][i]
- with open(img_path, 'rb') as jpg_file:
- byte_content = jpg_file.read()
- # 把原始字节码编码成base64字节码
- base64_bytes = base64.b64encode(byte_content)
-
- # 把base64字节码解码成utf-8格式的字符串
- base64_string = base64_bytes.decode('utf-8')
- import json
-
- # 创建一个字典
- data = {
-
- "version": "5.1.1",
- "flags": {},
- "shapes": [
-
- ]
-
- }
- json_data = json.dumps(data, indent=4)
- imgName = img_path.split("/")[-1]
- print(img_path)
- savePath = "/home/ebo/test/high/_merge/" + imgName.split(".")[0] + ".json"
- with open(savePath, 'w') as file:
- file.write(json_data)
- for j in range(pred.shape[0]):
- # 将字典转换为JSON格式
- # 打开文件,并将JSON数据写入文件
- with open(savePath, 'r') as f:
- data = json.load(f)
- # 在字典列表中插入新的字典
- bbox = {"label": "person", 'points': [[float(pred[j][0].item()), float(pred[j][1].item())],
- [float(pred[j][2].item()), float(pred[j][3].item())]],
- "group_id": (j + 1),
- "shape_type": "rectangle", "flags": {}}
- data['shapes'].append(bbox)
- data.update({"imagePath": imgName})
- data.update({"imageData": base64_string})
- # data.update({"imageData": str(base64.b64encode(open(img_path, "rb").read()))})
- data.update({"imageHeight": orig_img.shape[0]})
- data.update({"imageWidth": orig_img.shape[1]})
- for i in range(17):
- if float(pred_kpts[j][i][2].item()) > 0.5:
- # print(float(pred_kpts[:, i, 0]), float(pred_kpts[:, i, 1]))
- keypoints = {'label': str(i),
- 'points': [[float(pred_kpts[j][i][0].item()), float(pred_kpts[j][i][1].item())]],
- 'group_id': (j + 1), 'shape_type': 'point', 'flags': {}}
- # keypoints = {'label': i, 'points': 0, 'group_id': 1, 'shape_type': 'point', 'flags': {}}
- # print(keypoints)da
-
- data['shapes'].append(keypoints)
- # 将更新后的数据写回到JSON文件
- with open(savePath, 'w') as f:
- json.dump(data, f, indent=4)
-
- # print(pred)
- results.append(
- Results(orig_img, path=img_path, names=self.model.names, boxes=pred[:, :6], keypoints=pred_kpts))
-
- return results
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/木道寻08/article/detail/758714
推荐阅读
相关标签

