
- 1RabbitMQ安装UI监控插件
- 2《图像处理的璀璨星空:技术演进与热点聚焦》_图像处理技术现如今的前沿技术有哪些
- 3C++ + QT (不使用QT插件模式)的heic图片显示。_qt heic
- 4欧拉操作系统_欧拉系统
- 5网络资源模板--基于 Android Studio 实现的新闻App_android studio新闻客户端制作
- 6Android数据库高手秘籍_android 数据库密集
- 7【kafka专栏】消息队列通用消息传递模型(带视频)_可以传输图片视频的消息队列
- 8Git工具常用命令详解_git命令工具
- 9深入理解哈希表
- 10【大模型应用篇6】私有化智能体平台,为了数据更安全........_dify和coze
大数据:聚类算法深度解析_大数据分析聚类算法
赞
踩
文章目录
深度解析大数据聚类分析
大数据聚类分析是数据科学领域中的关键技术之一,它能够帮助我们从庞大而复杂的数据集中提取有意义的信息和模式。在这篇博文中,我们将深入探讨大数据聚类分析的概念、方法、应用和挑战。
1. 聚类分析的基本概念
1.1 什么是聚类分析?
聚类分析是一种将数据分成具有相似特征的组的技术。其目标是使组内的数据点相似度最大化,而组间的相似度最小化。这有助于发现数据中的隐藏结构和模式,为进一步的分析和决策提供基础。
在聚类分析中,我们将数据点划分为不同的簇,使得同一簇内的数据点相互之间更为相似。这种相似性是通过一定的距离度量来定义的,常见的包括欧氏距离、曼哈顿距离等。而组间的相似度最小化,则意味着不同簇之间的差异性较大。
聚类的过程类似于将一堆未标记的数据分成若干组,使得同一组内的数据点更加相似,例如下面分类结果。
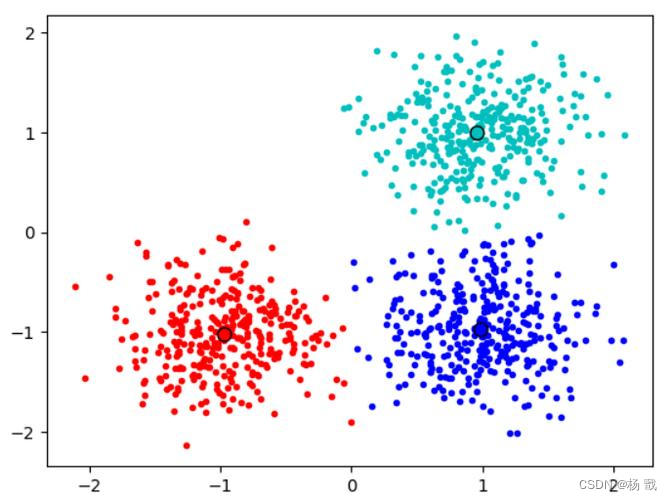
这有助于我们在没有先验标签的情况下发现数据中的潜在结构,为后续的分析和应用提供了基础。
# 伪代码:K均值算法实现聚类分析 from sklearn.cluster import KMeans import numpy as np # 假设有一组数据 points,其中每一行代表一个数据点的特征 points = np.array([[1, 2], [5, 8], [1.5, 1.8], [8, 8], [1, 0.6], [9, 11]]) # 假设我们要将数据分成两个簇 kmeans = KMeans(n_clusters=2) kmeans.fit(points) # 获取每个数据点所属的簇 labels = kmeans.labels_ # 输出结果 print("数据点所属簇:", labels)

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
在上述代码中,我们使用了K均值算法对一组数据进行聚类分析。该算法将数据点划分为两个簇,输出每个数据点所属的簇。这就是聚类分析的基本原理之一。
聚类分析的应用非常广泛,从市场细分到图像分割,都离不开聚类的帮助。通过深入理解聚类分析的概念和方法,我们能够更好地应用它来解决实际问题。
1.2 大数据背景下的挑战
在大数据背景下,数据量巨大、多样性高、实时性要求等因素给聚类分析带来了巨大的挑战。传统的聚类算法可能无法有效处理这些庞大的数据集,因此需要采用分布式计算和更高效的算法来应对这些挑战。
1.2.1 数据量巨大
大数据的特点之一是其庞大的数据量,传统的单机计算无法处理如此大规模的数据。对于聚类分析而言,这就要求我们使用分布式计算框架,如Apache Spark,以同时处理并行计算,提高处理效率。

1.2.2 多样性高
大数据往往涉及多种类型的数据,包括结构化数据、半结构化数据和非结构化数据。传统聚类算法可能只适用于特定类型的数据,因此需要采用更灵活的算法或者组合多种算法来处理这种多样性。
1.2.3 实时性要求
在大数据背景下,很多应用场景要求对数据进行实时的聚类分析。例如,在在线广告投放中,需要实时了解用户的兴趣以提供更精准的广告。因此,聚类算法不仅需要高效处理大规模数据,还需要具备实时性能。
为了解决这些挑战,大数据聚类分析引入了诸如流式计算、近似算法和增量式计算等技术。下面是一个简单的流式聚类的示例:
# 伪代码:流式聚类示例 from sklearn.cluster import MiniBatchKMeans import numpy as np # 初始化MiniBatchKMeans模型 mbk = MiniBatchKMeans(n_clusters=3, random_state=42) # 模拟流式数据输入 streaming_data = np.array([[1, 2], [5, 8], [1.5, 1.8], [8, 8], [1, 0.6], [9, 11]]) # 逐步更新聚类模型 for i in range(len(streaming_data)): mbk.partial_fit([streaming_data[i]]) # 获取聚类结果 labels = mbk.labels_ print("数据点所属簇:", labels)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
在上述示例中,我们使用了MiniBatchKMeans模型来模拟流式数据输入,并逐步更新聚类模型。这种方式使得算法能够在数据流不断到来的情况下进行实时聚类。
通过克服大数据背景下的这些挑战,我们可以更好地应用聚类分析在复杂和庞大的数据集中发现有价值的模式和信息。
2. 大数据聚类算法
2.1 K均值算法
K均值是最常用的聚类算法之一,它通过将数据点分配到K个簇,使得簇内的数据点尽量相似。该算法迭代进行簇分配和簇中心更新,直至收敛。在大数据背景下,可以使用分布式计算框架如Apache Spark来加速计算过程。
K均值算法步骤:
- 初始化: 随机选择K个数据点作为初始簇中心。
- 分配: 将每个数据点分配到距离最近的簇中心。
- 更新: 重新计算每个簇的中心,即取簇中所有数据点的平均值。
- 重复: 重复步骤2和步骤3,直至簇中心不再发生明显变化或达到预定迭代次数。
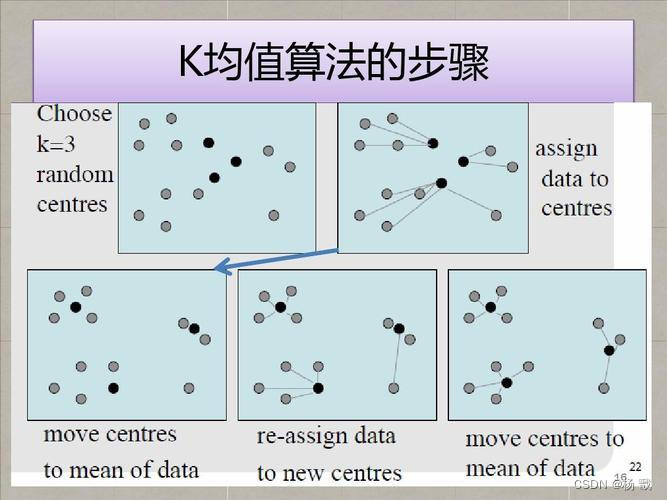
K均值算法的优点之一是其简单性和易于理解。然而,在大数据背景下,传统的K均值算法可能面临计算效率低下的问题。因此,我们可以借助分布式计算框架来提高其处理大规模数据的能力。
# 伪代码:K均值算法在Apache Spark中的实现
from pyspark.ml.clustering import KMeans
# 假设data是一个大数据集的DataFrame
kmeans = KMeans().setK(3).setSeed(1)
model = kmeans.fit(data)
result = model.transform(data)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
上述伪代码演示了如何在Apache Spark中使用K均值算法。Spark的分布式计算能力使得K均值算法能够处理大规模数据集,加速聚类过程。
2.2 层次聚类算法
层次聚类通过构建一棵聚类树,逐步合并或分裂簇来达到聚类的目的,例如下面步骤。
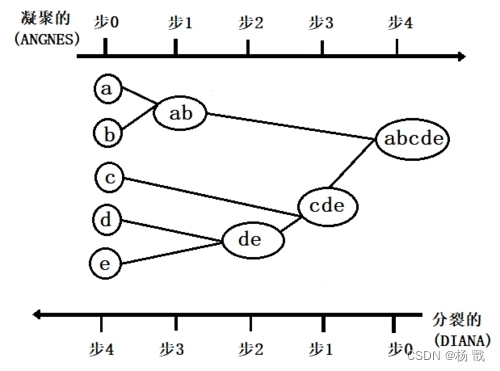
这种方法的优势在于可以形成聚类的层次结构,对数据的结构有更全面的了解。
# 伪代码:层次聚类算法
from scipy.cluster.hierarchy import linkage, dendrogram
import matplotlib.pyplot as plt
# 假设data是一个大数据集的特征矩阵
Z = linkage(data, 'ward')
dendrogram(Z)
plt.show()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
上述伪代码演示了如何使用层次聚

