
- 1Android第三方库收藏汇总,驱动核心源码详解和Binder超系统学习资源_android 第三方控件库
- 2鸿蒙开发:Universal Keystore Kit(密钥管理服务)【明文导入密钥(C/C++)】
- 3ROS-Moveit和Gazebo联合仿真(二)_gazebo联合moveit运动仿真
- 4Django学习笔记1day59_django preventdefault() 的用法
- 5亚马逊aws深度学习_在线学习的前5大Amazon Web Services或AWS课程-免费和最佳
- 6消息队列常见问题(1)-如何保障不丢消息_消息业务层保证不丢消息方案
- 7Javascript学习笔记(自用)_芙兰朵字符串匹配
- 830个接口自动化测试面试题,看过的已经在上班了_接口自动化常见面试题
- 9昇思25天学习打卡营第19天|ShuffleNet图像分类
- 10使用SM4国密加密算法对Spring Boot项目数据库连接信息以及yaml文件配置属性进行加密配置(读取时自动解密)_sm4 requires a 128 bit key
自然语言处理在文本情感分析领域应用综述
赞
踩
论文地址:全文阅读--XML全文阅读--中国知网 (cnki.net)

0 引言
nlp是一门研究如何让计算机听懂人类语言的学科,各平台用户的言论对商家而言,对用户本身来说提供情绪宣泄。
1 NLP文本预处理
1.1分词,停用词,词典
分词
来源:自然语言处理(1):分词_自然语言处理 分词-CSDN博客
分词是自然语言处理的基础,分词准确度直接决定了后面的词性标注、句法分析、词向量以及文本分析的质量。英文语句使用空格将单词进行分隔,除了某些特定词,如how many,New York等外,大部分情况下不需要考虑分词问题。但中文不同,天然缺少分隔符,需要读者自行分词和断句。故在做中文自然语言处理时,我们需要先进行分词。
比如人名,有的算法认为姓和名应该分开,有的认为不应该分开。这需要制定一个相对统一的标准。又例如“花草”,有的人认为是一个词,有的人认为应该划分开为两个词“花/草”。某种意义上,中文分词可以说是一个没有明确定义的问题。
切分歧义
不同的切分结果会有不同的含义,这又包含如下几种情况
- 组合型歧义:分词粒度不同导致的不同切分结果。比如“中华人民共和国”,粗粒度的分词结果为“中华人民共和国”,细粒度的分词结果为“中华/人民/共和国”。这种问题需要根据使用场景来选择。在文本分类,情感分析等文本分析场景下,粗粒度划分较好。而在搜索引擎场景下,为了保证recall,细粒度的划分则较好。jieba分词可以根据用户选择的模式,输出粗粒度或者细粒度的分词结果,十分灵活。
另外,有时候汉字串AB中,AB A B可以同时成词,这个时候也容易产生组合型歧义。比如“他/将/来/网商银行”,“他/将来/想/应聘/网商银行”。这需要通过整句话来区分。
组合型歧义描述的是AB A B均可以同时成词的汉字串,它是可以预测的,故也有专家称之为“固有型歧义” - 交集型歧义:不同切分结果共用相同的字,前后组合的不同导致不同的切分结果。比如“商务处女干事”,可以划分为“商务处/女干事”,也可以划分为“商务/处女/干事”。这也需要通过整句话来区分。交集型歧义前后组合,变化很多,难以预测,故也有专家称之为“偶发型歧义”。
- 真歧义:本身语法或语义没有问题,即使人工切分也会产生歧义。比如“下雨天留客天天留人不留”,可以划分为“下雨天/留客天/天留/人不留”,也可以划分为“下雨天/留客天/天留人不/留”。此时通过整句话还没法切分,只能通过上下文语境来进行切分。如果是不想留客,则切分为前一个。否则切分为后一个。
有专家统计过,中文文本中的切分歧义出现频次为1.2次/100汉字,其中交集型歧义和组合型歧义占比为12:1。而对于真歧义,一般出现的概率不大。
分词算法
分为三类:
基于词典的分词
基于词典的分词算法,本质上就是字符串匹配。将待匹配的字符串基于一定的算法策略,和一个足够大的词典进行字符串匹配,如果匹配命中,则可以分词。根据不同的匹配策略,又分为正向最大匹配法,逆向最大匹配法,双向匹配分词,全切分路径选择等。
__最大匹配法__主要分为三种:
- 正向最大匹配法,从左到右对语句进行匹配,匹配的词越长越好。比如“商务处女干事”,划分为“商务处/女干事”,而不是“商务/处女/干事”。这种方式切分会有歧义问题出现,比如“结婚和尚未结婚的同事”,会被划分为“结婚/和尚/未/结婚/的/同事”。
- 逆向最大匹配法,从右到左对语句进行匹配,同样也是匹配的词越长越好。比如“他从东经过我家”,划分为“他/从/东/经过/我家”。这种方式同样也会有歧义问题,比如“他们昨日本应该回来”,会被划分为“他们/昨/日本/应该/回来”。
- 双向匹配分词,则同时采用正向最大匹配和逆向最大匹配,选择二者分词结果中词数较少者。但这种方式同样会产生歧义问题,比如“他将来上海”,会被划分为“他/将来/上海”。由此可见,词数少也不一定划分就正确。
基于统计的分词
基于统计的分词算法,本质上是一个序列标注问题。我们将语句中的字,按照他们在词中的位置进行标注。标注主要有:B(词开始的一个字),E(词最后一个字),M(词中间的字,可能多个),S(一个字表示的词)。例如“网商银行是蚂蚁金服微贷事业部的最重要产品”,标注后结果为“BMMESBMMEBMMMESBMEBE”,对应的分词结果为“网商银行/是/蚂蚁金服/微贷事业部/的/最重要/产品”。
我们基于统计分析方法,得到序列标注结果,就可以得到分词结果了。这类算法基于机器学习或者现在火热的深度学习,主要有HMM,CRF,SVM,以及深度学习等。
基于规则的分词
基于规则的分词方法也是一种常见的中文分词方法。与基于词典的方法不同,基于规则的方法是根据人工定义的一系列规则来对句子进行切分。这些规则可以基于语言学知识、语法规则或其他领域特定的规则,或者是根据前面已经切分好的部分顺势推断后面的切分位置。基于规则的分词方法可分为基于有限状态自动机(Finite State Automata, FSA)和基于上下文无关文法(CFG)两类。
基于有限状态自动机的规则分词方法是将分词过程看作有限状态自动机,在自动机中,每个状态表示一个位置,转移边表示一个字(或几个字)和预期的状态和输出(即分出来的词)。通过将词典中的词作为合法序列添加到自动机中寻找对应的词语,同时在自动机上定义分词规则。在实际应用中,由于需要人工编写规则,这种方法需要耗费大量的人力和时间。
基于上下文无关文法的规则分词方法是将中文分词问题看作是一个语言模型问题,就好像将一个句子作为一个句法结构来表示。这种方法可以通过语法规则推断和分类无限制长度和形式变化的句子,并根据推断结果进行分割,也需要人工编写,但在一些特定领域(比如医学)中有应用。
基于规则的分词方法通常用于一些规则相对固定、文本稳定、领域专业词汇较多的领域,例如机器翻译、信息提取和语料库构建等应用。
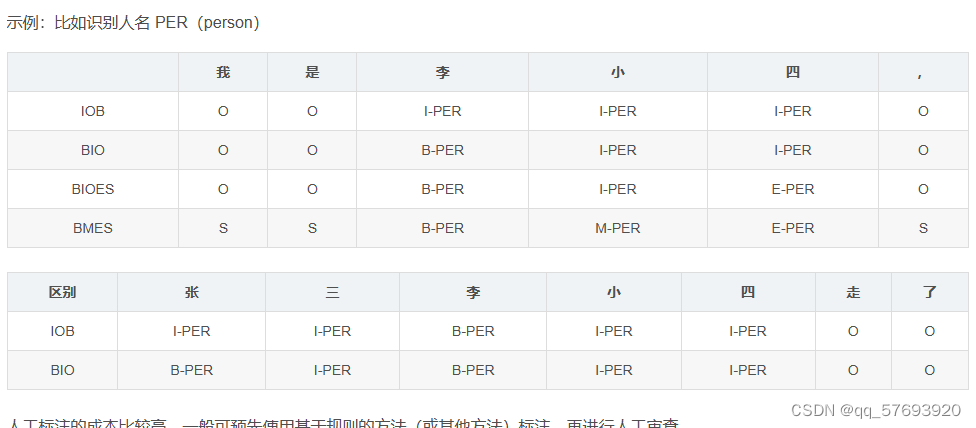
1.2 命名实体识别
命名实体识别是一种信息抽取技术,信息抽取就是从非结构化的文本中抽取结构化的数据和特定的关系。识别文本中的人名,地名,时间等实体的名称,就叫做命名实体识别。
命名实体识别的任务就是识别出待处理文本中三大类(实体类、时间类和数字类)、七小类(人名、机构名、地名、时间、日期、货币和百分比)命名实体。
命名实体识别的方法分为三类:
基于词典和规则的方法
将识别对象放入对应字典中,以模式和字符串方式进行匹配。此方法只适合小规模的数据,而且系统移植性不强。
基于机器学习的方法
将命名实体识别看作一个序列标注问题。常用的序列标注模型有:隐马尔可夫模型(HMM),最大熵马尔可夫模型(MEMM),条件随机场(CRF),支持向量机(SVM)。
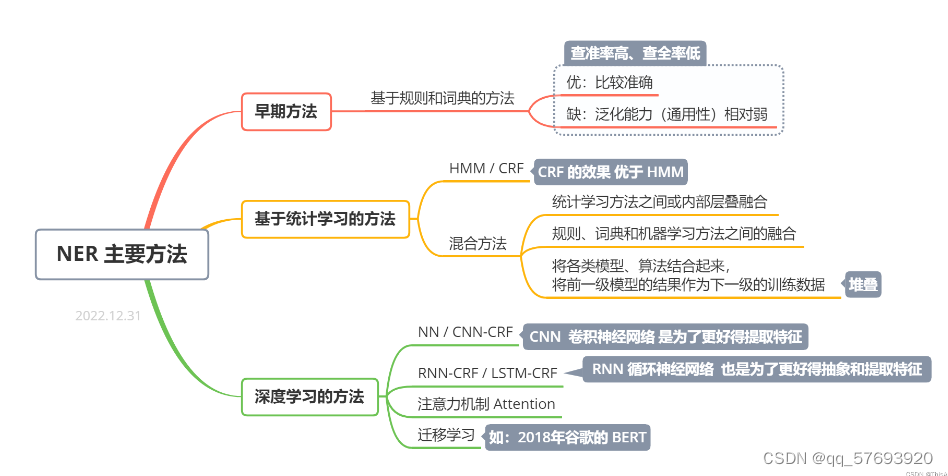

基于深度学习的方法
在神经网络逐渐发展成熟后提出的,词向量的出现,可以解决高维空间的数据稀疏问题。
2 基于情感词典的情感分析法
利用情感词典获取文档中情感词的情感值,再通过加权计算来确定文档整体情感倾向。不光包括文字还有颜文字,表情包等。

但是基于情感词典的方法过度依赖于情感词典的创建, 始终有作为字典的局限,并且对于成语、歇后语等的识别效 果并不理想;
3 基于机器学习的情感分析法
支持向量机,朴素贝叶斯对于文本数据的分类效果较好。
3.1 支持向量机
用于情感分类,SVM的学习策略就是间隔最大化,基本模型是定义在特征空间上间隔最大的线性分类器。
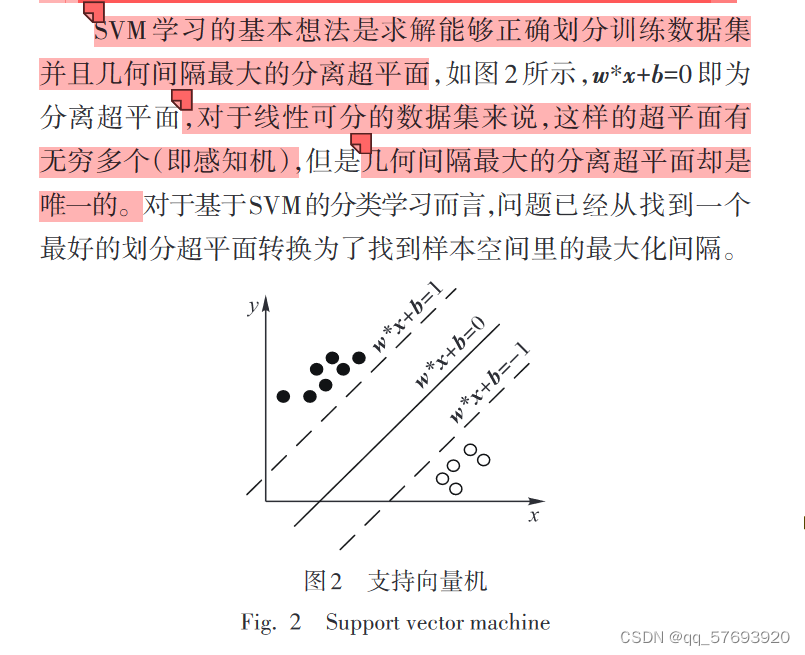
对于输入空间中的非线性分类问题,引入核函数,核函数的主要作用是将样本从原始空间映射到一个更高维的特征空间,使得样本在这个特征空间内线性可分。

3.2 朴素贝叶斯
算法链接有案列:【机器学习】朴素贝叶斯算法-CSDN博客
3.3 机器学习情感分析
基于机器学习的情感分类法比起构建情感词典有一定 的进步,但是还是需要人工对文本特征进行标记,人为的主 观因素会影响的最后的结果;其次,机器学习需要依赖大量 的数据,很容易产生无效的工作,执行的速度会很慢,如果模 型的效率不高,难以适应如今信息量爆炸的时代,这类方法 在进行情感分析时常常不能充分利用上下文文本的语境信 息,对准确性会造成影响。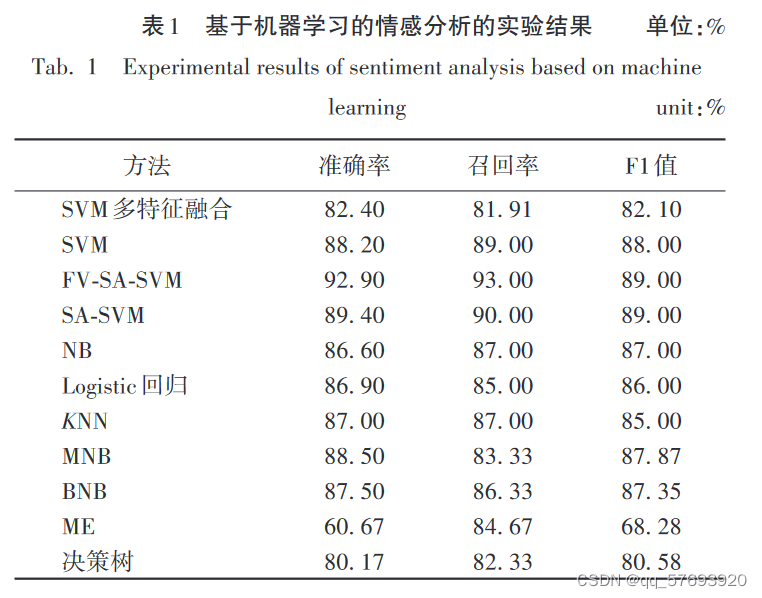
4 基于深度学习的情感分析法
深度学习模型CNN,RNN,LSTM,Transformer,BiLSTM,门控循环单元和注意力机制。
4.1 深度学习常用模型
CNN 如图 5 所示,与普通神经网络相似,它们都由具有 可学习的权重和偏置常量的神经元组成。每个神经元都接 收一些输入,并做一些点积计算,输出是每个分类的分数,普 通神经网络里的一些计算技巧到这里依旧适用。
在有些情况下,为了解决 RNN 可能会出现的梯度消失 或 者 梯 度 爆 炸 问 题 ,又 提 出 了 LSTM 模 型 如 图 7 所 示 。 和 RNN 相比,LSTM 只是运算的逻辑变了,也就是神经元的内 部运算公式变了,但是结构并没有变,因此 RNN 的各种结构 都能通过 LSTM 来替换。
4.2 基于深度学习的分词及情感词典构建
以深度学习为基础构造词典。
4.3 单一神经网络
在深度学习中,CNN 取得了较好的效果,但是 CNN 没有 考虑到文本的潜在主题
RBM BGRU
4.4 单一神经网络与注意力机制
4.5 混合神经网络
4.6 预训练模型
预训练模型作为一种迁移学习的应用,它可以将从开放 领域学到的知识迁移到下游任务,以改善低资源任务,对低 资源语言处理也非常有利,在几乎所有 NLP 任务中都取得 了目前最佳的成果。同时预训练模型+微调机制具备很好的 可扩展性,出现一个新任务时,不需要重复使用大量的时间 和数据训练一个新的模型,只需要根据需求调整参数即可
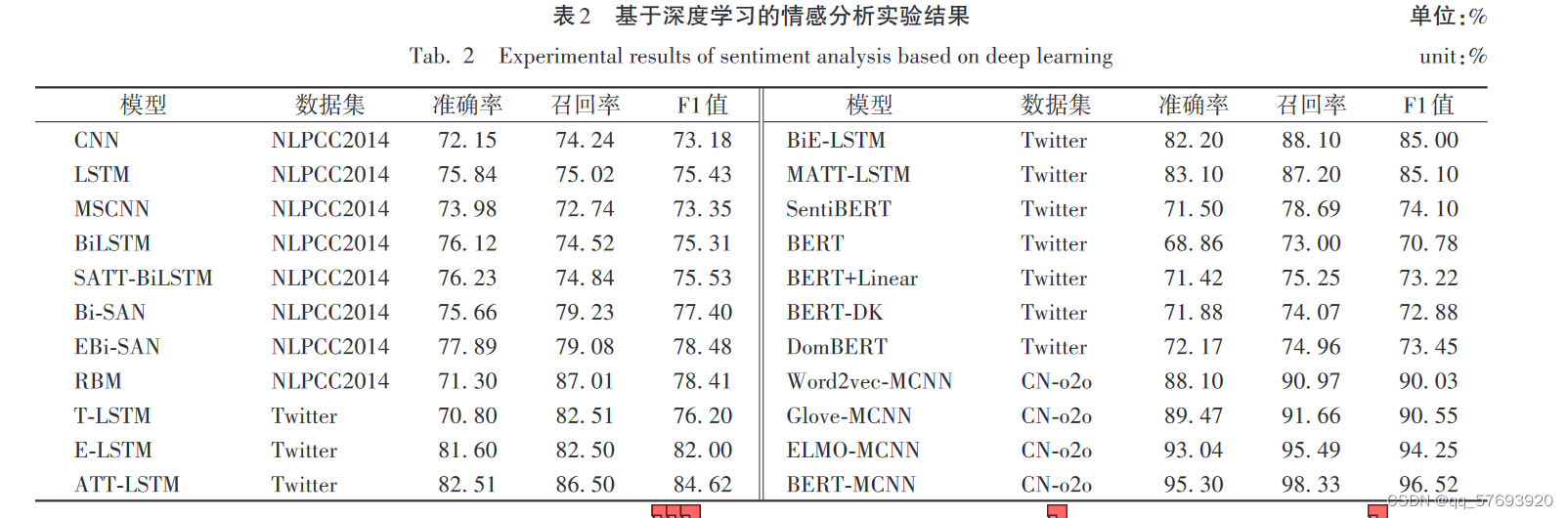
5 结论
在语境中,目前还没有找到较好的方法处理反语;大部分的 分类仍使用的二分类情感分析,对于多分类的情感分析还没 有好的效果;多模态融合语料的情感分类也是近年的热点, 不同模态中情感信息的权重如何分配,考虑外部语义信息对 情感分类的准确性是否有帮助,也需要研究。
4 的文献引用
| 46 | RBM 分析句子 |
| 47 | BGRU 中文文本 |
| 48 | RNN 小语种 |
| 49 | RNN+LSTM 英文 |
| 50 | 基于注意力的LSTM 面向方面层次情感的分类 |
| 51 | LSTM 最佳参数合集 |
| 52 | 推特 微博 表情 |
| 单一神经网络+注意力机制 | |
| 53 | BiLSTM+多极化正交注意力机制 隐式情感分析 |
| 54 | 双向注意力机制+GUR 情感预测 |
| 55 | LSTM+注意力 |
| 56 | 内容注意力 方面的情感分类模型 句子层面 语境注意机制 |
| 57 | 多注意力机制 远距离分离情感特征 结合不同关注点预测情感 |
| 58 | MATT-LSTM 基于方面 |
| 59 | 多层融合LSTM |
| 混合神经网络 | |
| 60 | 注意力+CNN-RNN |
| 61 | LSTM+CNN Wor2vec dropout |
| 62 | CNN-LSTM 短文本情感分类 |
| 63 | CNN BiLSTM |
| 64 | BiLSTM+随机森林 |
| 65 | EBA 隐式情感分析 |
| 66 | MAML+BiLSTM 情感分类 使用梯度下降更新参数 |
| 67 | 注意力+CNN+双向门控循环单元 解决梯度消失和梯度爆炸 |
| 68 | Multi-BiLSTM |
| 69 | CNN+LSTM |
| 预训练模型 | |
| :ELMo (Embeddings from Language Models)、BERT(Bidirectional Encoder Representation from Transformers)、XLNET、ALBERT (A Lite BERT)、Transformer | |
| 70 | ELMo+Transformer+LSTM+多头注意力 情感分类 |
| 71 | 双向自注意力网络Bi-SAN |
| 72 | BERT-MCNN |
| 73 | 基于BERT的新方法 |
| 74 | ELMo+BERT=DomBERT 情感分析 |
| 76 | SentiBERT 捕获否定关系和对比关系以及构建模型方面更有优势 |


