
- 1设置hive的执行引擎_0506如何将Hue4.0版本中默认执行引擎设置为Hive而非Impala
- 2高校导师在微信群里公然委托关照考研复试,学校通报处理情况!
- 3腾讯AniPortrait开源:音频合成逼真人脸动画,对标阿里EMO_腾讯aniportrait 模型下载
- 4stable diffusion常用的模型_stable diffusion 常用模型
- 5基于Kafka+Flink+Redis的电商大屏实时计算案例
- 6前端自动化测试(二)Vue Test Utils + Jest_vue+jest 测试api
- 7【前端】从零开始学习编写HTML
- 820240624 每日AI必读资讯
- 9数据结构之冒泡排序图文详解及代码(C++实现)_c++冒泡算法代码
- 10Dagger2 在 Android SystemUI 中的应用_android systemui11 dagger2
扩散模型也能推荐短视频!港大腾讯提出新范式DiffMM
赞
踩
DiffMM团队 投稿
量子位 | 公众号 QbitAI
想象一下你在刷短视频,系统想要推荐你可能会喜欢的内容。
但是,如果系统只知道你过去看过什么,而不了解你喜欢视频的哪些方面(比如是画面、文字描述还是背景音乐),那么推荐可能就不会那么精准。
对此,来自港大和腾讯的研究人员推出了全新多模态推荐系统范式——DiffMM。

简单来说,DiffMM创建了一个包含用户和视频信息的图,这个图会考虑视频的各种元素。
然后它通过一种特殊的方法(图扩散)来增强这个图,让模型更好地理解用户和视频之间的关系。
最后,它使用一种叫做对比学习的技术,来确保不同元素(比如视觉和声音)之间的一致性,这样推荐系统就能更好地理解用户的喜好。
为了测试效果,团队在三个公共数据集上进行了大量实验,结果证明DiffMM相比于各种竞争性基线模型均达到SOTA。

目前相关论文已公开,代码也已开源。
模型方法
DiffMM的总体框架图如下所示,主要包含三个部分:
多模态图扩散模型,通过生成扩散模型实现多模态信息引导的模态感知用户-物品图生成;
多模态图聚合,通过在生成的模态感知用户-物品图上进行图卷积操作以实现多模态信息聚合;
跨模态对比增强,通过对比学习的方式来利用不同模态下用户-物品交互模式的一致性,进一步增强模型的性能。
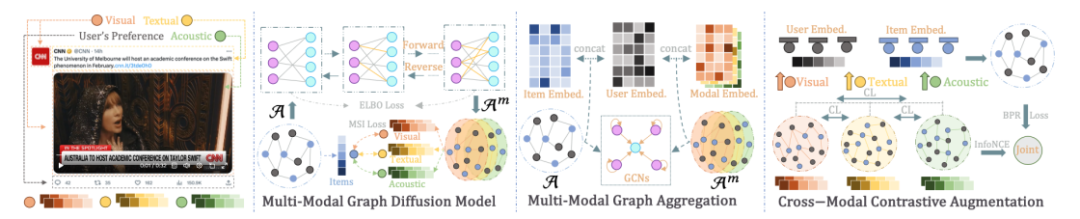
多模态图扩散
受到扩散模型在保留其生成输出中的基本数据模式方面的成功的启发,DiffMM框架提出了一种新颖的多模态推荐系统方法。
具体而言,作者引入了一个多模态图扩散模块,用于生成包含模态信息的用户-物品交互图,从而增强对用户偏好的建模。
该框架专注于解决多模态推荐系统中无关或噪声模态特征的负面影响。
为实现这一目标,作者使用模态感知去噪扩散概率模型将用户-物品协同信号与多模态信息统一起来。
具体而言,作者逐步破坏原始用户-物品图中的交互,并通过概率扩散过程进行迭代学习来恢复原始交互。
这种迭代去噪训练有效地将模态信息纳入用户-物品交互图的生成中,同时减轻了噪声模态特征的负面影响。
此外,为实现模态感知的图生成,作者提出了一种新颖的模态感知信号注入机制,用于指导交互恢复过程。这个机制在有效地将多模态信息纳入用户-物品交互图的生成中起到了关键作用。
通过利用扩散模型的能力和模态感知信号注入机制,DiffMM框架为增强多模态推荐器提供了一个强大而有效的解决方案。
图概率扩散范式
在用户-物品交互上进行图扩散包含两个关键工程。
第一个过程称为前向过程,它通过逐步引入高斯噪声来破坏原始的用户-物品图。这一步骤逐渐破坏了用户和物品之间的交互,模拟了噪声模态特征的负面影响。
第二个过程称为逆向过程,它专注于学习和去噪受损的图连接结构。这个过程旨在通过逐步改进受损的图来恢复用户和物品之间的原始交互。
对于前向图扩散过程,考虑用户声明:本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:【wpsshop博客】
Copyright © 2003-2013 www.wpsshop.cn 版权所有,并保留所有权利。

