- 1局域网访问windows下的虚拟机网站_公司局域如何访问我的虚拟机内的地址网站
- 2DES算法的加解密原理(详细算法+样例Demo)_des解密
- 3【Golang 面试基础题】每日 5 题(二)
- 4事理图谱的构建:知识图谱_事理图谱构建
- 5frameMaxSize
- 6centos7 安装RabbitMQ,webui管理_socat webui
- 7Java中Base64(实例)
- 8大模型为什么是深度学习的未来?_教育大模型的发展现状、创新架构及应用展望
- 9大模型下的Agent、AIGC的商业案例集合_agents 大模型应用案例
- 10【系统架构设计 每日一问】五 搜索型业务,采用MySQL+ES,如何保证数据一致性
【深度学习】 探讨Stable Diffusion模型的训练及其偏向性_stablediffusion 生成的人物为什么都是国外的,需要训练模型吗
赞
踩
探讨Stable Diffusion模型的训练及其偏向性
近年来,生成式模型在图像生成领域取得了显著进展,特别是Stable Diffusion模型。作为一种基于扩散过程的生成模型,Stable Diffusion模型展现了生成高质量图像的巨大潜力。然而,与所有机器学习模型一样,其生成效果和偏向性在很大程度上依赖于所使用的训练数据。本文将深入探讨这一现象,并介绍一些相关技术,如LoRA(Low-Rank Adaptation),以增强模型的多样性和适应性。
背景与简介
Stable Diffusion模型基于扩散过程,通过一系列的反向扩散步骤生成图像。这一过程类似于去噪自编码器,通过从噪声中逐步恢复图像细节,最终生成高质量的图像。然而,模型的生成效果高度依赖于训练数据的质量和多样性。简而言之,模型“见过”什么样的数据,它就更擅长生成什么样的数据。
训练数据对模型效果的影响
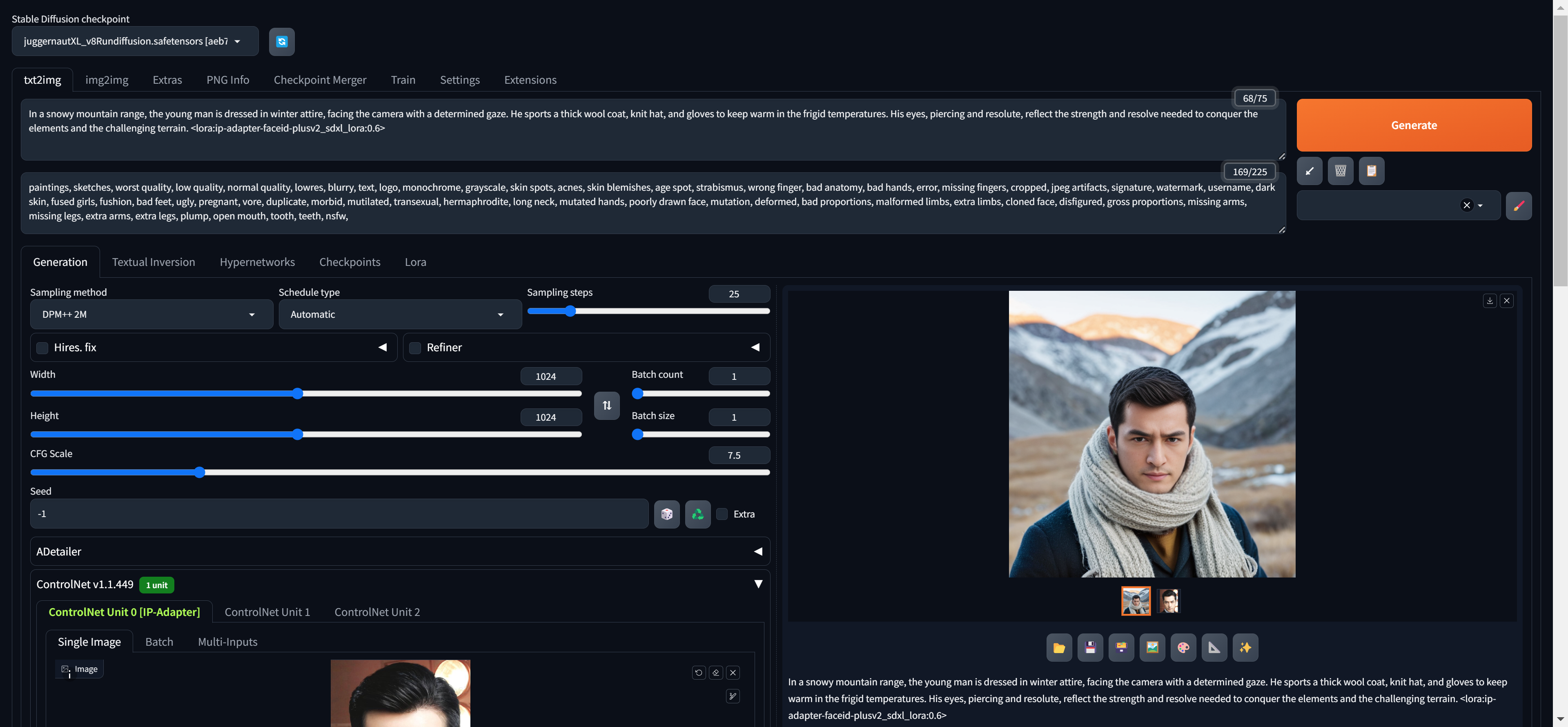
在我训练Stable Diffusion模型的过程中,我发现训练数据的选择对模型生成效果有着决定性的影响。例如,当使用大量人物肖像数据进行训练时,模型在生成人物肖像方面表现出色。具体来说,如果训练数据主要是中国人的肖像,生成的图像自然更符合中国人的特征;反之,若训练数据是外国人的肖像,生成的图像则更符合外国人的特征。
这种现象表明,模型具有一定的偏向性,其生成结果深受训练数据的影响。为了实现更广泛的适用性,我们需要多样化训练数据,同时采用合适的技术手段进行文本监督。
兼顾多种特征的方法
为了同时生成符合不同人种特征的人物图像,文本监督是一种有效的方法。通过在训练数据中添加详细的文本描述,可以增强模型的监督性。例如,在训练数据中,对于中国人的图片,可以在文本描述中明确写明“这是一个中国人”;对于外国人的图片,文本描述中则注明“这是一个外国人”。这样,当我们在生成图像时提供相应的文本描述,Stable Diffusion模型就能生成符合描述的人物图像。
LoRA技术的应用
LoRA(Low-Rank Adaptation)是一种用于适应和微调大型语言模型的新技术。LoRA通过在预训练模型的基础上添加低秩适应层,可以在不显著增加计算资源的情况下,提高模型的适应性和泛化能力。在图像生成领域,LoRA同样可以用于Stable Diffusion模型的训练,通过微调模型参数,使其在多样化数据上的生成效果更加出色。
模型的局限性与改进空间
尽管Stable Diffusion模型在许多应用场景中展现了巨大的潜力,但我们也需要认识到其局限性。模型的生成结果基于其见过的训练数据,因此,当模型未见过某类数据时,其生成效果往往不尽如人意。为了提升模型的泛化能力,我们需要不断丰富和多样化训练数据,并利用诸如文本监督和LoRA等技术手段进行优化。
结论
Stable Diffusion模型作为一种强大的图像生成工具,其效果和偏向性高度依赖于训练数据。通过合理选择和标注训练数据,并结合LoRA等先进技术,我们可以进一步提升模型的生成效果和适用性。希望这些分享能对大家有所帮助,欢迎留言讨论或提出建议!