
- 1哈工大数据库系统(上):关系模型之关系代数(四)课后测验与作业_7)关系r与关系s只有一个公共属性,t1是r与s做θ连接的结果,t2是r与s自然连接的结
- 2前端学习DAY9
- 3互联网大厂产品面试分析(多年猎头通过候选人总结,着重感谢一位刘女士)_产品面试项目最大挑战
- 4求解具有多个初始条件的ODE方程组_ode45中有6个初始条件应该怎么给出
- 5【RAG】内部外挂知识库搭建-本地GPT_本地rag
- 6Fixed-Point Designer(设计、仿真和分析定点系统)
- 7android profiler启动分析,Android冷启动优化总结(四)——profile分析
- 8flutter 打包apk_flutter build apk
- 9仕考网:公务员考试面试时间一般多长?
- 10git提交大文件报错,删除大文件后,还是提交不成功解决办法
给想玩AI的新手|Stable Diffusion 保姆级入门手册_stablediffusion元素法典
赞
踩
最近,AI图像生成引人注目,它能够根据文字描述生成精美图像,这极大地改变了人们的图像创作方式。Stable Diffusion作为一款高性能模型,它生成的图像质量更高、运行速度更快、消耗的资源以及内存占用更小,是AI图像生成领域的里程碑。本篇文章作者将手把手教大家入门 Stable Diffusion,可以先收藏再浏览,避免迷路!(SD安装包,大模型,lora,关键词还是入门的基础资料等,都给大家打包好了!需要的小伙伴文末扫码找我获取就行啦!)
1 硬件要求
2 环境部署
2.1 手动部署
2.2 自动整合包
- 1
- 2
- 3
3 关于插件
4 文生图最简流程——重点步骤与参数
5 提示词
5.1 提示词内容
5.2 提示词语法
5.3 Token
5.4 提示词模板
- 1
- 2
- 3
- 4
- 5
- 6
- 7
6 Controlnet
6.1 基本流程
6.2 可用预处理/模型
6.3 多 ControlNet 合成
- 1
- 2
- 3
- 4
- 5
7 模型:从下载、安装、使用到训练
7.1 模型下载
7.2 模型安装
7.3 模型使用
7.4 模型训练
7.5 环境搭建
7.6 环境更新
7.7 界面启动
7.8 训练流程
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
8 风格训练与人物训练
01
硬件要求
本篇我们将详细讲解SD模型的使用教程,各位读者可以在公众号后台回复**「AIGC」**直接获取模型以及实现快速部署的GPU服务器限量优惠券。
建议使用不少于 16GB 内存,并有 60GB 以上的硬盘空间。需要用到 CUDA架构,推荐使用 N 卡。(目前已经有了对 A 卡的相关支持,但运算的速度依旧明显慢于N卡,参见:
Install and Run on AMD GPUs · AUTOMATIC1111/stable-diffusion-webui Wiki · GitHub。)
注意:过度使用,显卡会有损坏的风险。进行 512x 图片生成时主流显卡速度对比:
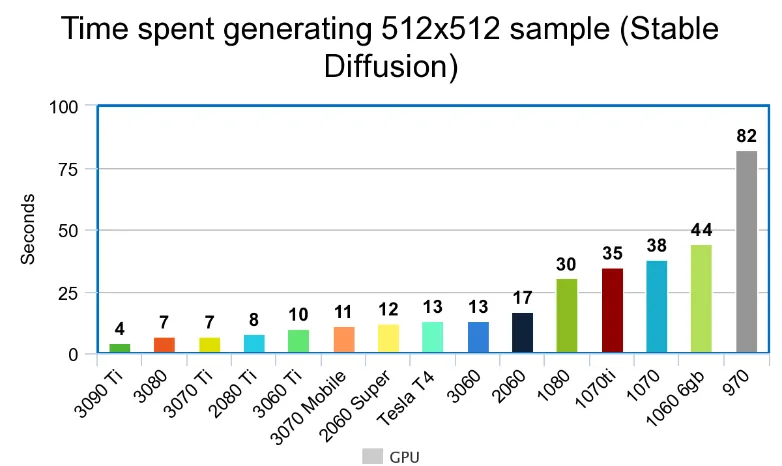
02
环境部署
2**.1** 手动部署
可以参考 webui 的官方 wiki 部署:
Home · AUTOMATIC1111/stable-diffusion-webui Wiki (github.com)
stable diffusion webui 的完整环境占用空间极大,能达到几十 G。值得注意的是,webui 需要联网下载安装大量的依赖,在境内网络环境下载较慢。接下来是手动部署的6个步骤:
1、安装 Python
安装 Python 3.10,安装时须选中 Add Python to PATH
2、安装 Git
在 Git-scm.com 下载 Git 安装包并安装。下载 webui 的 github 仓库,按下 win+r 输入 cmd,调出命令行窗口。运行下方代码,并请把代码中的 PATH_TO_CLONE 替换为自己想下载的目录。
cd PATH_TO_CLONE
git clone https://github.com/AUTOMATIC1111/stable-diffusion-webui.git
3、装配****模型
可在如 Civitai 上下载标注有 CKPT 的模型,有模型才能作画。下载的模型放入下载后文件路径下的 models/Stable-diffusion 目录。
4、使用
双击运行 webui-user.bat 。脚本会自动下载依赖,等待一段时间(可能很长),程序会输出一个类似 http://127.0.0.1:7860/ 的地址,在浏览器中输入这个链接开即可。详细可参见模型使用。
5、更新
按下 win+r 输入 cmd,调出命令行窗口。运行下方,并请把代码中的 PATH_TO_CLONE 替换为自己下载仓库的目录。
cd PATH_TO_CLONE
git pull
2**.2 自动****整合包**
**觉得上述步骤麻烦的开发者可以直接使用整合包,解压即用。**比如独立研究员的空间下经常更新整合包。秋叶的启动器也非常好用,将启动器复制到下载仓库的目录下即可,更新管理会更方便。
打开启动器后,可一键启动:
如果有其它需求,可以在高级选项中调整配置。
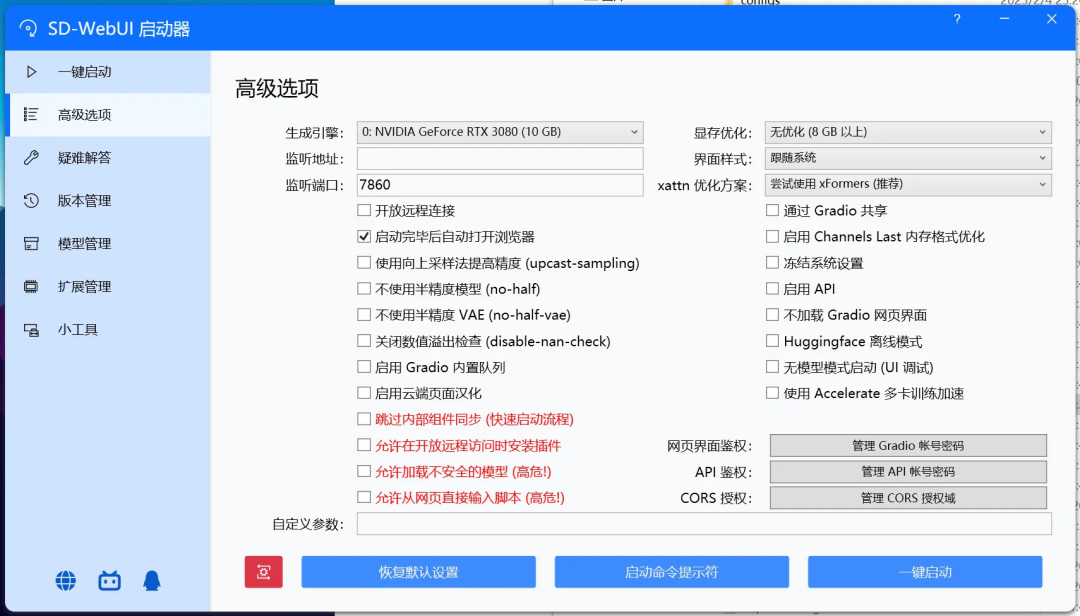
显存优化根据显卡实际显存选择,不要超过当前显卡显存。不过并不是指定了显存优化量就一定不会超显存,在出图时如果启动了过多的优化项(如高清修复、人脸修复、过大模型)时,依然有超出显存导致出图失败的几率。
xFormers 能极大地改善内存消耗和速度,建议开启。准备工作完毕后,点击一键启动即可。等待浏览器自动跳出,或是控制台弹出本地 URL 后说明启动成功。
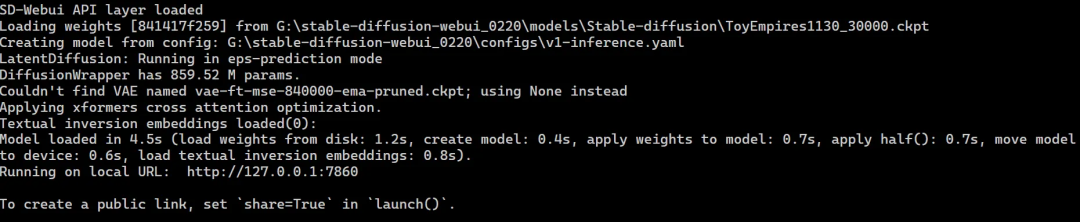
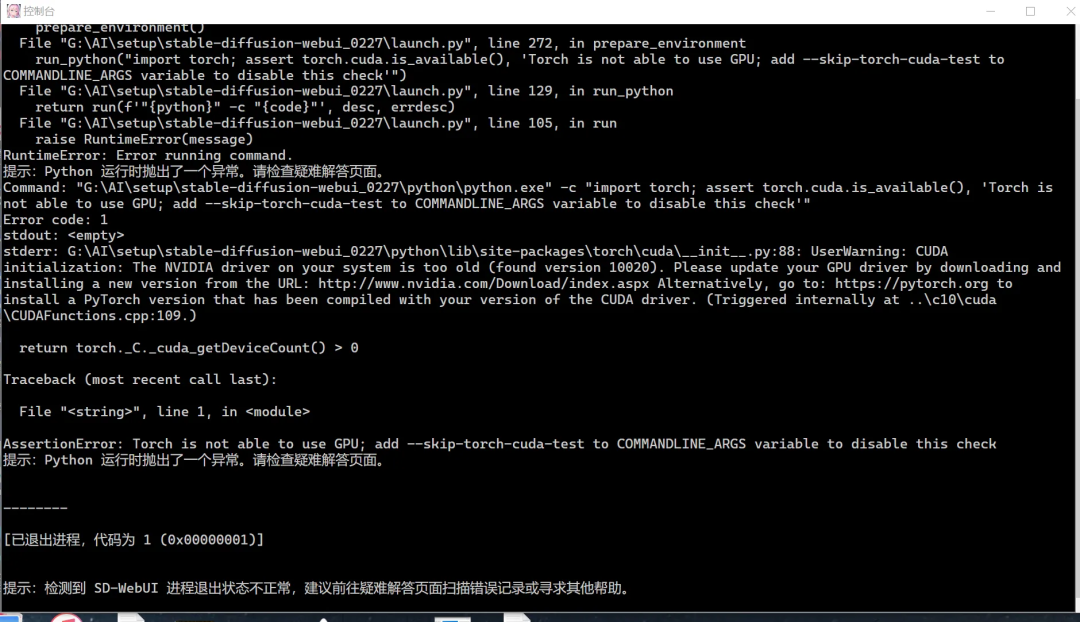
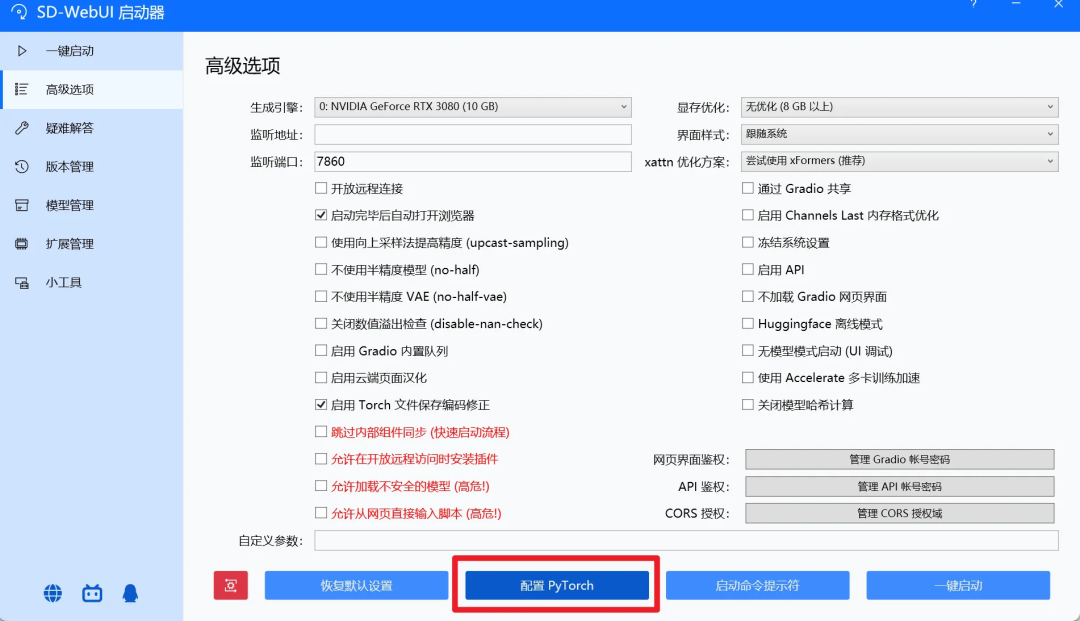
如果报错提示缺少 Pytorch,则需要在启动器中点击配置。
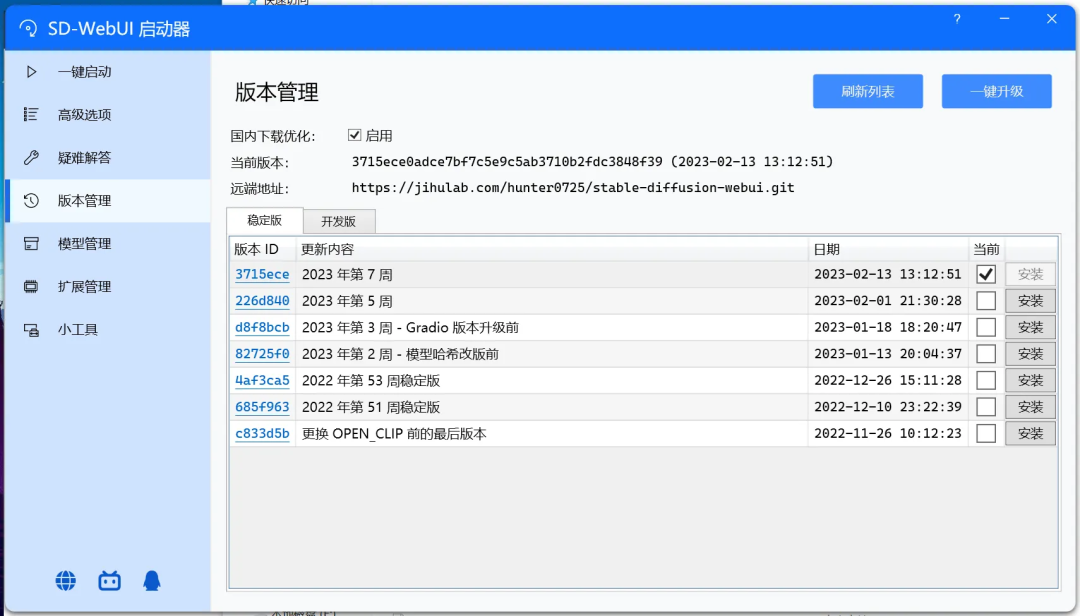
Stable Diffusion webui 的更新比较频繁,请根据需求在“版本管理”目录下更新:
同样地,也请注意插件的更新:
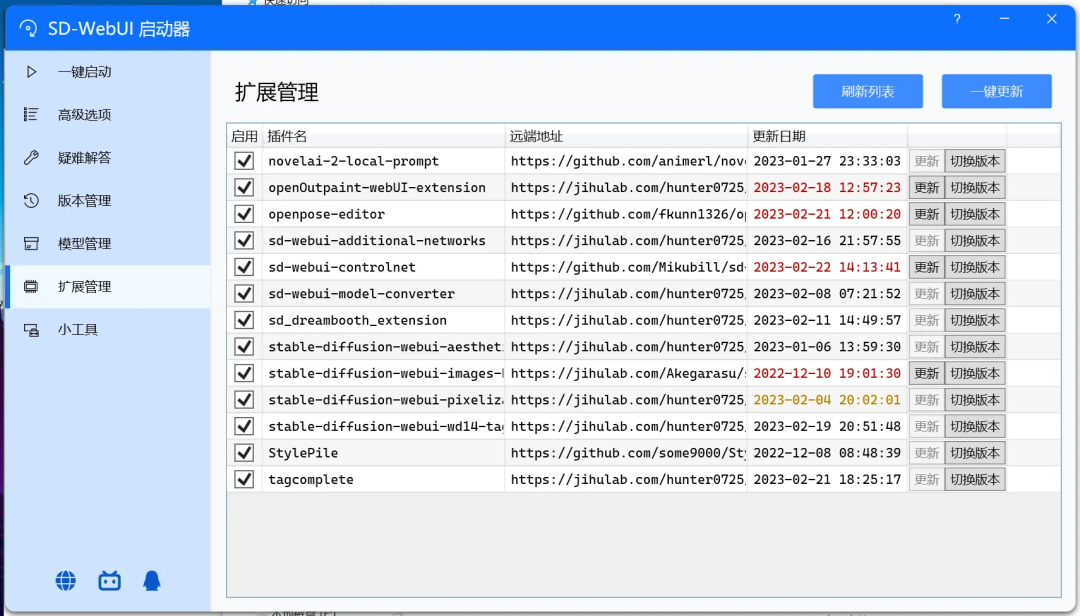
03
关于插件
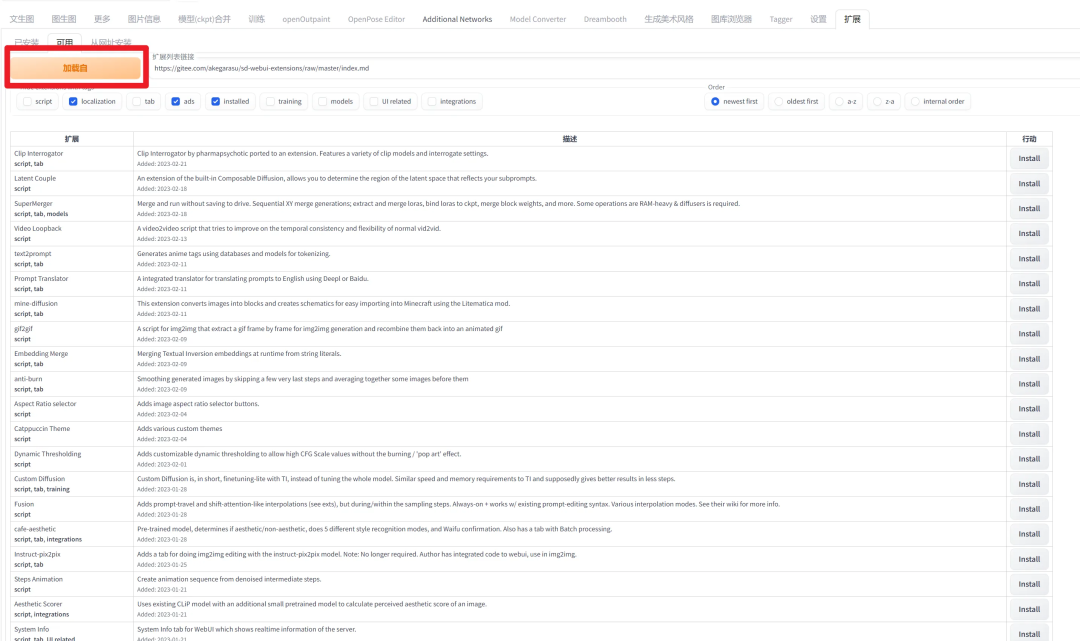
Stable Diffusion 可配置大量插件扩展,在 webui 的“扩展”选项卡下,可以安装插件:

点击「加载自」后,目录会刷新。选择需要的插件点击右侧的 install 即可安装。
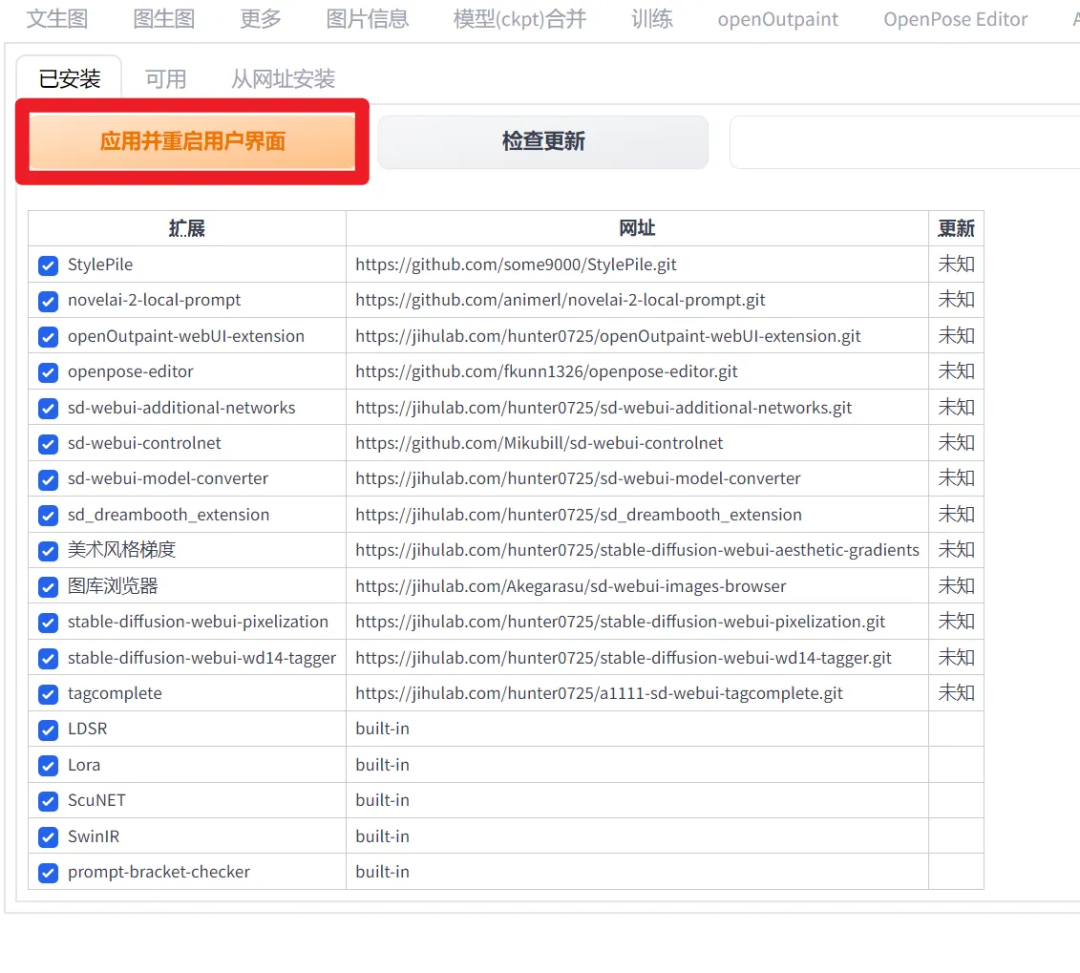
安装完毕后,需要重新启动用户界面:
04
文生图最简流程——重点步骤与参数
4**.1 重点步骤**
主要是4步骤:
1、选择需要使用的模型(底模),这是对生成结果影响最大的因素,主要体现在画面风格上。
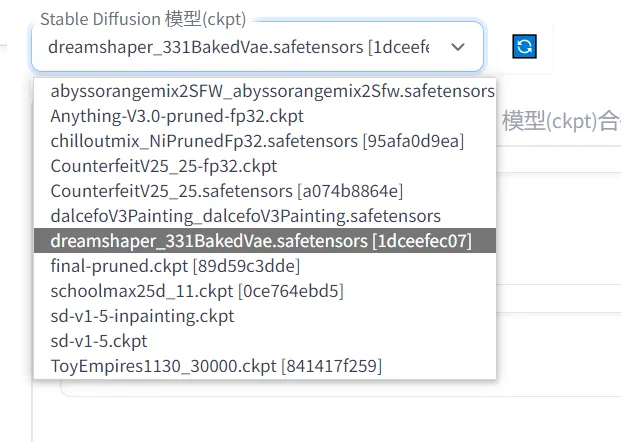
2、在第一个框中填入提示词(Prompt),对想要生成的东西进行文字描述。

3、在第二个框中填入负面提示词(Negative prompt),对不想要生成的东西进行文字描述。

4、选择采样方法、采样次数、图片尺寸等参数。
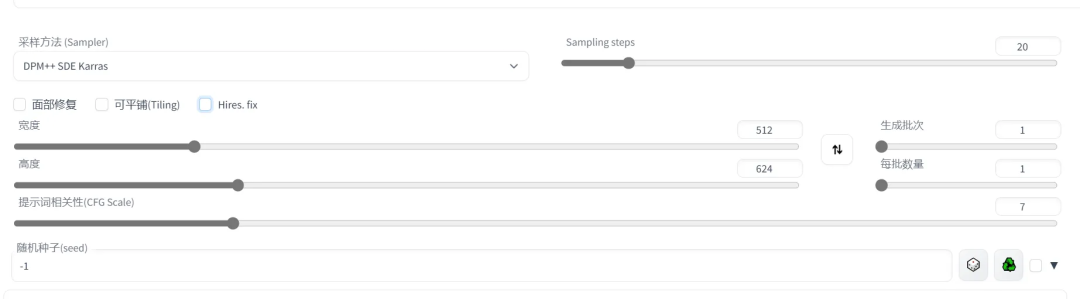
4**.2 参数**
知道完大致的步骤后,下面我们来介绍一些重要的参数,选择不同将会带来较大差异:
- Sampler(采样器/采样方法)选择使用哪种采样器?
|
|
- Sampling Steps(采样步数)
Stable Diffusion 的工作方式是从以随机高斯噪声起步,向符合提示的图像一步步降噪接近。随着步数增多,可以得到对目标更小、更精确的图像。但增加步数也会增加生成图像所需的时间。增加步数的边际收益递减,取决于采样器。一般开到 20~30。
不同采样步数与采样器之间的关系:

- CFG Scale(提示词相关性)
图像与你的提示的匹配程度。增加这个值将导致图像更接近你的提示,但它也在一定程度上降低了图像质量。
可以用更多的采样步骤来抵消。过高的 CFG Scale 体现为粗犷的线条和过锐化的图像。一般开到 7~11。
CFG Scale 与采样器之间的关系:

- 生成批次
每次生成图像的组数。一次运行生成图像的数量为“批次* 批次数量”。
- 每批数量
同时生成多少个图像。增加这个值可以提高性能,但也需要更多的显存。大的 Batch Size 需要消耗巨量显存。若没有超过 12G 的显存,请保持为 1。
- 尺寸
指定图像的长宽。出图尺寸太宽时,图中可能会出现多个主体。1024 之上的尺寸可能会出现不理想的结果,推荐使用小尺寸分辨率+高清修复(Hires fix)。
- 种子
种子决定模型在生成图片时涉及的所有随机性,它初始化了 Diffusion 算法起点的初始值。
理论上,在应用完全相同参数(如 Step、CFG、Seed、prompts)的情况下,生产的图片应当完全相同。
- 高清修复

通过勾选 “Highres. fix” 来启用。默认情况下,文生图在高分辨率下会生成非常混沌的图像。如果使用高清修复,会型首先按照指定的尺寸生成一张图片,然后通过放大算法将图片分辨率扩大,以实现高清大图效果。最终尺寸为(原分辨率*缩放系数 Upscale by)。
放大算法中,Latent 在许多情况下效果不错,但重绘幅度小于 0.5 后就不甚理想。ESRGAN_4x、SwinR 4x 对 0.5 以下的重绘幅度有较好支持。
Hires step 表示在进行这一步时计算的步数。
Denoising strength 字面翻译是降噪强度,表现为最后生成图片对原始输入图像内容的变化程度。该值越高,放大后图像就比放大前图像差别越大。低 denoising 意味着修正原图,高 denoising 就和原图就没有大的相关性了。一般来讲阈值是 0.7 左右,超过 0.7 和原图基本上无关,0.3 以下就是稍微改一些。实际执行中,具体的执行步骤为 Denoising strength * Sampling Steps。
- 面部修复
修复画面中人物的面部,但是非写实风格的人物开启面部修复可能导致面部崩坏。点击“生成”即可。
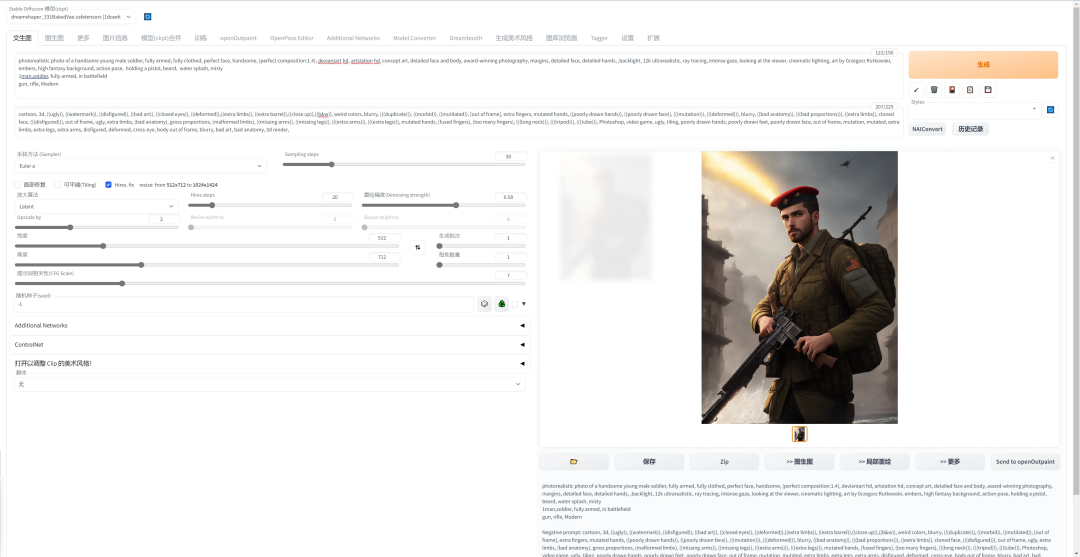
05
提示词
提示词所做的工作是缩小模型出图的解空间,即缩小生成内容时在模型数据里的检索范围,而非直接指定作画结果。
提示词的效果也受模型的影响,有些模型对自然语言做特化训练,有些模型对单词标签对特化训练,那么对不同的提示词语言风格的反应就不同。
5**.1** 提示词内容
提示词中可以填写以下内容:
| 类型 | 要求 |
自然 语言 | 可以使用描述物体的句子作为提示词。大多数情况下英文有效,也可以使用中文。避免复杂的语法。 |
单词 标签 |
|
Emoji 颜文字 | Emoji (声明:本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:【wpsshop博客】 推荐阅读 相关标签 Copyright © 2003-2013 www.wpsshop.cn 版权所有,并保留所有权利。 |

