
- 1【数学建模】——【python库】——【Pandas学习】_数学建模常用的python的库安装
- 2Spark-机器学习(1)什么是机器学习与MLlib算法库的认识_了解mllib算法
- 3LSTM微博评论情绪识别二分类项目jieba分词遇到的问题
- 4视频生成赛道王者归来!Runway 最新 Gen-3 Alpha 炸场
- 51 MM模块-STO之同一个公司不同工厂之间库存转移UB_ub转储
- 6对话系统最新进展-17篇EMNLP 2021论文_graph based network with contextualized representa
- 7对Image caption的一些理解(看图说话)_imagecaption技术讲解
- 8Springboot入门之集成Actuator_springboot集成actuator
- 9git基础教程(34) 远程仓库管理git remote与git fetch_git remote update
- 10iperf3 网络探测详解(android、iOS、windows)_iperf 安卓
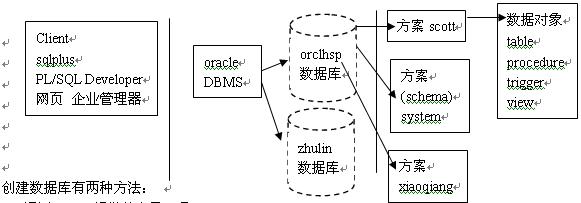
史上最全的oracle常用知识总结_create user ct1030 identified by kanri
赞
踩
Ⅰ.oracle itcast
本文档对应程序在myeclipse的jdbc/src/下
分页查询中的rownum可以方便删除重复记录等各种方便查询
Oracle安装自动生成sys用户和system用户
sys 超级用户 具有最高权限 具有sysDBA角色,有create database权限
该用户默认密码是change_in_install
system 管理操作员 权限也比较大,具有sysoper角色,没有create database权限。
该用户默认密码是 manager
这是通过sqlplus客户端连接数据库时有多个实例采用下面DOS命令:sqlplus scott/tiger@zhulin
见2.13 oracle创建数据库实例
启动sqlplus,然后登陆数据库出现错误:TNS:协议适配器错误
原因有3个:
1.监听服务没有启动:services.msc或开始—>程序—>管理工具—>服务,打开服务面板:
启动oraclehome92TNSlistener服务
2.database instance没有启动:services.msc或开始—>程序—>管理工具—>服务 启动oralceserviceXXX,XXX就是你databaseSID如zhulin
3.注册表问题:
regedit.msc
进入HKEY_LOCAL_MACHINE\SOFTWARE\ORACLE\KEY_OraDb11g_home1
下的ORACLE_SID值修改为zhulin
你的全局数据库名字 你的数据库SID即可。
ORACLE用SYS和SYSTEM默认密码登录提示ORA-01017:invalidusername/password;logond denied该怎么解决?
|
|
解决办法:
有可能是你在建数据库的时候,
修改了默认的密码
而自己又忘记
你可再重新修改过来
sqlplus / assysdba
alter user system identified by manager;
alter user sys identified by manager;
或者改成其他的你自己容易记住的
默认scott用户密码是tiger
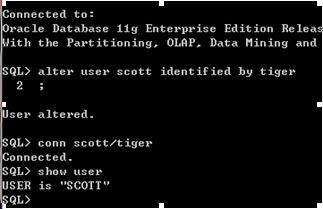
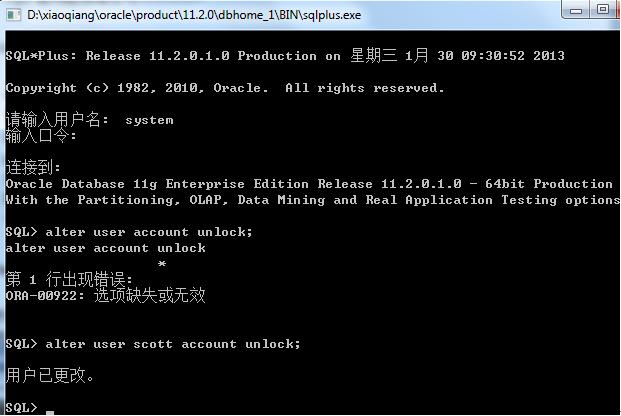
1.oralce解锁步骤
先使用system登录
然后输入alter user scott account unlock; //解锁scott账号
SQL语句必须带分号!!!!!!!!!!!!!最好都分号结束
2.oralce开发工具
sqlpulsw和sqlus工具
在开始→程序→oracle oradb_home10g→application development→sqlplus
或在运行栏输入sqlplus
pl/sqldeveloper 这款软件用的很多 第三方软件 需要单独安装
企业管理器(web) 首先保证相关服务启动即oracleDBconsole+实例名启动
在浏览器中输入http://ip:1158//em ip是指你的具体ip地址或者你的机器名 1158是端口
一般情况下 这个服务是不启动 很不安全
3.oracle常用sql plus命令
(1)请使用scott用户登录oracle数据库实例,然后切换为身份为system
简单使用 conn 用户名/密码
登录后,使用 conn[ect] 用户名/密码@网络 [assysdba/sysoper]
(2)showuser 显示当前用户名
(3) 断开连接 disc[onnect]
(4)exit断开连接和退出sqlplus窗口
(5) 修改密码(前提是system或sys用户) passw[ord]
基本用法 password 用户名
如果给自己修改密码 则可以不带用户名
如果给别人修改密码 则需要带用户名
(6)& 交互命令可以替代变量的值
select* from emp where job=”&job”;
(7)edit用于编辑脚本(文本)
SQL>edit d:\
(8)spool 把屏幕上显示的记录,保存到文件中
spool on
spool d:/bak.sql
查询语句
spool off
(9)linesize用户控制每行显示多少个字符,默认80个字符 每次都要重新设置
基本用法: set linesize 120
(10)pagesize 用于每页显示多少行
基本用法: set pagesize 100
4.oracle用户管理
(1)创建用户 只有具有DBA权限才能创建比如system sys
基本用法:create user 用户名 identified by 密码
举例:create user xiaoqiang identified by hao200881037[oracle要求用户密码不能用数字开头]

后面我将密码修改为了200881037
?为什么创建的用户无法登陆
这是因为oracle 刚刚创建的用户是没有任何权限,需要管理员给用户分配适应的权限,才能够登陆
grantcreate session to xiaoqiang //会话权限
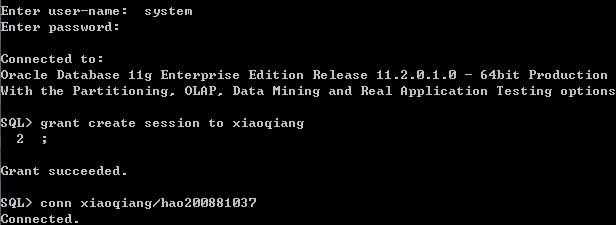
(1)权限
系统权限:和数据库管理相关的权限:
create session;create table;create index;createview;create sequence;create trigger
对象权限:和用户操作数据对象相关的权限:
update;insert;delete;select
(2)角色
预定义角色:把常用的权限集中起来,形成角色(套餐)
比如dba connect resource 三种角色
自定义角色:自己定义套餐
(3)方案(schema)
在一个数据库实例下:
当一个用户,创建好后,如果该用户创建了任意一个数据对象(表或触发器等),这时我们的DBMS就会创建一个对应的方案与该用户对应,并且该方案名字和用户名一致。
小技巧:如果希望看到某个用户的方案的数据对象,可以使用PL/SQL developer工具
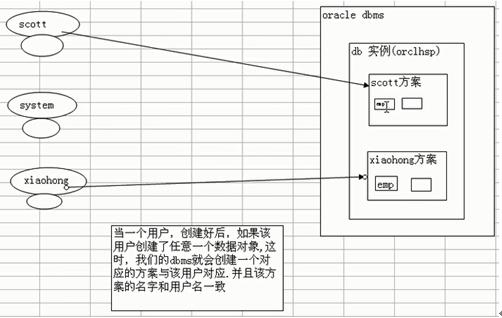
案例1:完成一个功能;让xiaoqiang用户去查询scott的emp表
步骤1:先用scott登录
connscott/tiger
步骤2:在scott账号上给xiaoqiang赋权限
grant select[update|delete|insert|all] on emp to xiaoqiang
这里就可以看出来 方案A和方案B可以有相同名的数据库,但是方案A中不可以有相同名的数据库
步骤3:登录xiaoqiang用户去查询emp表
错误用法:select * from emp 原因是在xiaoqiang登录状态下需要制定emp表来自哪里?
正确用法:select * from scott.emp;
查询时如果查询其他方案 一定要用带上其他方案名。
如果不带,就默认是select* from xiaoqiang.emp
案例2:完成一个功能想办法将xiaoqiang拥有的对scott.emp的权限转给stu用户。
scott—>xiaoqiang—>stu[权限转移]
conn scott/tiger;
grant all on scott.emp to stu with grantoption;
//with grant option 对象权限 表示得到权限的用户可以把权限继续分配
//with admin option系统权限 如果是系统权限,则带with admin iption
创建了普通账户 xiaoqiang 密码hao200881037
修改密码(前提是system或sys用户) passw[ord]
基本用法 password 用户名
如果给自己修改密码 则可以不带用户名
如果给别人修改密码 则需要带用户名
表空间:表存在的空间,一个表空间就是指向具体的数据文件
(4)用户管理的综合案例
创建的新用户是没有任何权限的,甚至连登录(会话)的数据库的权限都没有,需要为其指定响应的权限,给一个用户赋权限使用命令grant,回收权限revoke
grant权限/角色 to 用户
(1) 使用system创建xiaoqiang

后面我将密码修改为了200881037
(2) 使用system给小红分配2个常用角色
grantconnect to xiaoqiang
grantresource to xiaoqiang
disconn //切断连接
(3) 让xiaoqiang登录
conn xiaoqiang/200881037
(4) xiaoqiang修改密码 pasw[ord] xiaoqiang即可 然要求你输入旧密码 当然 超级管理员不需要输入旧密码
(5) xiaohong创建一张最简单的表
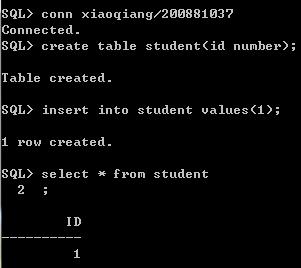
(6) 使用system登录,然后回收角色。
revoke connect fromxiaoqiang
revoke resource fromxiaoqiang
(7) 删除xiaoqiang用户:
drop user 用户名[cascade]
☞当我们删除一个用户的时候,若这个用户自己已经创建了数据对象(表、触发器等),需要加选项cascade表示把这个用户删除同时,把该用户创建的数据对象一并删除。
否则无法删除该用户,oracle用户认为删除了该用户就彻底抛弃了
(5)账号锁定
使用profile管理用户口令,账号锁定指用户登录时最多可以输入密码的次数,也可以指定用户锁定的时间(天)一般用DBA的身份去执行该命令。 profile文件[规则]
eg:
create profile lock_accountlimit failed_login_attempts 3 paswword_lock_time 2;
alter user tea profilelock_account;//其中lock_account是文件名
(6)账号解锁
alter user 用户名 account unlock;
(7)终止口令
eg:给tea创建一个profile文件,要求该用户每隔10天必须修改自家的登录密码,款限期为2天。
create profilemyprofile limit password_life_time 10 password_grace_time 2;
//可以继续加限制条件
alter user tea profile myprofile;
(8)删除profile文件
当不需要某个profile文件时,可以删除该文件。
drop profile profile文件名。5.oracle数据库启动流程
oracle可以通过命令行的方式启动,我们看看具体如何操作:
windows下:
(1)lsnrctl start (启动监听)
(2)oradim –startup –sid 数据库实例名
linux下:
(1) lsnrctl start (启动监听)
(2) sqlplus sys/chang_on_install as sysdba(以sysdba身份登录)
sqlplus /nolog
conn sys/chang_on_install assysdba
(3)startup
height�oml L h8H rid-mode:char;mso-layout-grid-align:none'> (8) 删除 profile 文件当不需要某个profile文件时,可以删除该文件。
drop profile profile文件名。
6.oracle登录认证方式
oracle在windows和linux下是不完全相同的:
windows下:
如果当前用户属于本地操作系统的ora_dba组(对于windows操作系统而言),即可通过操作系统认证。
普通用户:默认是以数据库方式认证,比如conn scott/tiger;
特权用户:默认是以操作系统认证(即:只要当前用户是在ora_dba组中则可以通过认证),比如connsystem/manager as sysdba;DBMS一看到assysdba则认为要以特权用户登录,前面的用户名和密码不看,登录后自动切换成sys用户<=>connsys/manager。
如果当前用户(win7系统账号)不在ora_dba组中,conn sys/manager输对了密码还是可以登录进去的(这时是采用了数据库方式验证)
sqlnet.ora文件在D:\xiaoqiang\oracle\product\11.2.0\dbhome_1\NETWORK\ADMIN目录下:
同时如果你安装第三方工具PL/SQL Developer,同时也需要修改
D:\xiaoqiang\oracle\product\instantclient_11_2目录下的sqlnet.ora文件
通过配置sqlnet.ora文件,可以修改oracle登录认证方式:
SQLNET.AUTHENTICATION_SERVICES=(NTS)是基于操作系统验证
SQLNET.AUTHENTICATION_SERVICES=(NONE)是基于Oracle验证
SQLNET.AUTHENTICATION_SERVICES=(NONE,NTS)是二者共存
linux下:
默认情况下linux下的oracle数据库sqlnet.ora文件没有SQLNET.AUTHENTICATION_SERVICES参数,此时是基于操作系统认真和oracle密码验证共存,加上SQLNET.AUTHENTICATION_SERVICES参数后,不管SQLNET.AUTHENTICATION_SERVICES设置为NONE还是NTS都是基于oracle密码验证。7.oracle丢失管理员密码怎么办
数据库实例名是根据实际情况命名的。
恢复办法:把原有密码文件删除,生成一个新的密码文件
恢复步骤如下:(1)搜索名为PWD数据库实例名.ora文件
(2)删除该文件,为以防万一,建议备份
(3)生成新的密码文件,在DOS控制台下输入命令
orapwdfile=原来密码文件的全路径\密码文件名.ora password=新密码 entries=10;
这里密码文件名是原来的密码文件名=PWD数据库实例名
entries 表示登录sys的最多用户(特权用户)
如果希望新的密码生效,则需要重新启动数据库实例服务.dos下services.exe
还有出现以下情况:
ORACLE用SYS和SYSTEM默认密码登录提示ORA-01017:invalidusername/password;logond denied该怎么解决?
解决办法:
有可能是你在建数据库的时候,
修改了默认的密码
而自己又忘记
你可再重新修改过来
sqlplus / assysdba
alter user system identified by manager;
alter user sys identified by manager;
或者改成其他的你自己容易记住的
默认scott用户密码是tiger
8.oracle表管理
类(对象)和表(记录)之间的关系

◆创建表
基本语法
- create table table_name(
- 列名 列类型,
- ……
- )
◆数据类型
① char(size) 存放字符串最大2000个字符,是定长
eg:char(32) 最多只能放入32个字符 如果超过就报错,如果不够’abc’则用空格补全
② varchar2(size)变长最大可以存放4000个字符
③ nchar(size) 定长 编码方式unicode 最大字符数是2000个
一个汉字占用nchar的一个字符空间,一个汉字,占用char的两个字符空间
④ nvarchar2(size)变长编码方式unicode最大字符数是4000个
⑤ clob 字符型大对象 变长 最大8TB
⑥ blob 变长
说明:我们在实际开发中很少把文件存放在数据库中(效率问题),实际上我们一般记录文件的一个路径(URL或本地路径),然后通过IO或网络来操作。
如果我们要求对文件安全性比较高,可以考虑放入数据库。
⑦ number(p,s) p为整数位,s为小数位,范围是1<=p<=38,-84<=s<=-127 变长
保存数据范围:-1.0e-130<=numbervalue<=1.0e+126 保存机器位数1-22byte
e.gnumber(5,2) 表示一个小数有5位有效位,2位小数,范围-999,99-999,99
比如你输入 573.316则真正保存是573.32,无法保存数据1000
number(5)等价于number(5,0),表示一个5位整数,范围-99999-99999,输入57523.316则保存57523
原则:如果在做实际开发中,我们没有指定数据小数位,则直接使用number
⑧date 日期类型
包含年月日,时分秒
插入数据时要使用默认格式是:'dd-mm-yyy';当然 如果用自己格式需要借用to_date函数
SQL> insert into test1 values(to_date('2005-11-11','YYYY-MM-DD'));
1 row inserted
to_char
你可以使用select ename, hiredate, sal from emp where deptno =10;显示信息,可是,在某些情况下,这个并不能满足你的需求。
问题:日期是否可以显示 时/分/秒
SQL> select ename, to_char(hiredate, 'yyyy-mm-ddhh24:mi:ss') from emp;
9.oracle基本查询
oracle的crud操作(create retrieve/read update delete)
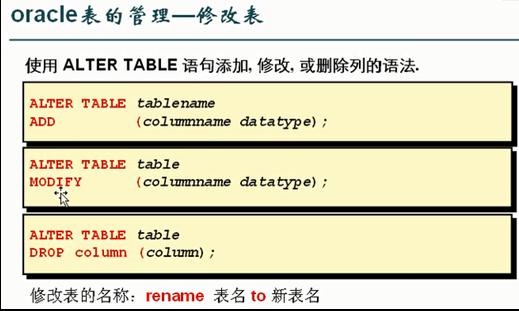
添加一个字段
SQL>ALTER TABLE student add (classIdNUMBER(2));
修改一个字段的长度
SQL>ALTER TABLE student modify (xm VARCHAR2(30));
修改字段的类型/或是名字(不能有数据) 不建议做
SQL>ALTER TABLE student modify (xm CHAR(30));
删除一个字段 不建议做(删了之后,顺序就变了。加就没问题,应为是加在后面)
SQL>ALTER TABLE student DROP COLUMN sal;
修改表的名字 很少有这种需求
SQL>RENAME studentTO stu;
删除表
SQL>DROP TABLE student;
添加数据
所有字段都插入数据
INSERT INTOstudent VALUES('A001', '张三', '男', '01-5月-05',10);
oracle中默认的日期格式‘dd-mon-yy’ dd日子(天) mon 月份 yy 2位的年 ‘09-6月-99’ 1999年6月9日
修改日期的默认格式(临时修改,数据库重启后仍为默认;如要修改需要修改注册表)
ALTER SESSIONSETNLS_DATE_FORMAT ='yyyy-mm-dd';
修改后,可以用我们熟悉的格式添加日期类型:
INSERT INTOstudent VALUES('A002', 'MIKE', '男','1905-05-06', 10);
插入部分字段
INSERT INTOstudent(xh, xm, sex) VALUES ('A003', 'JOHN', '女');
插入空值
INSERT INTOstudent(xh, xm, sex, birthday) VALUES ('A004', 'MARTIN', '男', null);
问题来了,如果你要查询student表里birthday为null的记录,怎么写sql呢?
错误写法:select * from student wherebirthday = null;
正确写法:select * from student wherebirthday is null;
如果要查询birthday不为null,则应该这样写:
select * from student wherebirthday is not null;
修改数据
修改一个字段
UPDATE student SETsex = '女'WHERE xh = 'A001';
修改多个字段
UPDATE student SETsex = '男',birthday = '1984-04-01' WHERE xh = 'A001';
修改含有null值的数据
不要用 = null 而是用 is null;
SELECT * FROM student WHEREbirthday IS null;
删除数据
DELETE FROMstudent;
删除所有记录,表结构还在,写日志,可以恢复的,速度慢。
Delete 的数据可以恢复。
savepoint a; --创建保存点
DELETE FROMstudent;
rollback to a; --恢复到保存点
一个有经验的DBA,在确保完成无误的情况下要定期创建还原点。
DROP TABLE student; --删除表的结构和数据;
delete fromstudent WHERExh = 'A001'; --删除一条记录;
truncate TABLE student; --删除表中的所有记录,表结构还在,不写日志,无法找回删除的记录,速度快。
oracle基本所有查询案例
在我们讲解的过程中我们利用scott用户存在的几张表(emp,dept)为大家演示如何使用select语句,select语句在软件编程中非常有用,希望大家好好的掌握。

查看表结构
DESC emp;
查询所有列
SELECT * FROM dept;
切忌动不动就用select*
SET TIMINGON;打开显示操作时间的开关,在下面显示查询时间。
CREATE TABLE users(userId VARCHAR2(10),uName VARCHAR2 (20), uPassw VARCHAR2(30));
INSERT INTO users VALUES('a0001', '啊啊啊啊', 'aaaaaaaaaaaaaaaaaaaaaaa');
--从自己复制,加大数据量大概几万行就可以了 可以用来测试sql语句执行效率
INSERT INTO users (userId,UNAME,UPASSW)SELECT * FROM users;
SELECT COUNT (*) FROM users;统计行数
查询指定列
SELECT ename, sal, job, deptno FROM emp;
如何取消重复行DISTINCT
SELECT DISTINCT deptno, job FROM emp;
查询SMITH所在部门,工作,薪水
SELECT deptno,job,sal FROM emp WHERE ename= 'SMITH';
注意:oracle对内容的大小写是区分的,所以ename='SMITH'和ename='smith'是不同的
使用算术表达式 nvl null
问题:如何显示每个雇员的年工资?
SELECT sal*13+nvl(comm, 0)*13 "年薪" , ename, comm FROM emp;
使用列的别名
SELECT ename "姓名", sal*12 AS "年收入" FROM emp;
如何处理null值使用nvl函数来处理
如何连接字符串(||)
SELECT ename || ' is a ' || job FROMemp;
使用where子句
问题:如何显示工资高于3000的 员工?
SELECT * FROM emp WHERE sal > 3000;
问题:如何查找1982.1.1后入职的员工?
SELECT ename,hiredate FROM emp WHEREhiredate >'1-1月-1982';
问题:如何显示工资在2000到3000的员工?
SELECT ename,sal FROM emp WHERE sal>=2000 AND sal <= 3000;
如何使用like操作符
%:表示0到多个字符 _:表示任意单个字符
问题:如何显示首字符为S的员工姓名和工资?
SELECT ename,sal FROM emp WHERE ename like'S%';
如何显示第三个字符为大写O的所有员工的姓名和工资?
SELECT ename,sal FROM emp WHERE ename like'__O%';
在where条件中使用in
问题:如何显示empno为7844, 7839,123,456 的雇员情况?
SELECT * FROM emp WHERE empno in (7844,7839,123,456);
使用is null的操作符
问题:如何显示没有上级的雇员的情况?
错误写法:select *from emp where mgr = '';
正确写法:SELECT *FROM emp WHERE mgr is null;
使用逻辑操作符号
问题:查询工资高于500或者是岗位为MANAGER的雇员,同时还要满足他们的姓名首字母为大写的J?
SELECT * FROM emp WHERE (sal >500 or job= 'MANAGER') and ename LIKE 'J%';
使用order by字句 默认asc
问题:如何按照工资的从低到高的顺序显示雇员的信息?
SELECT * FROM emp ORDER by sal;
问题:按照部门号升序而雇员的工资降序排列
SELECT * FROM emp ORDER by deptno, sal DESC;
使用列的别名排序
问题:按年薪排序
select ename, (sal+nvl(comm,0))*12 "年薪" from emp order by "年薪" asc;
别名需要使用“”号圈中,英文不需要“”号
Clear清屏命令
数据分组 ——max,min, avg, sum, count
问题:如何显示所有员工中最高工资和最低工资?
SELECT MAX(sal),min(sal) FROM emp e;
最高工资那个人是谁?
错误写法:selectename, sal from emp where sal=max(sal);
正确写法:selectename, sal from emp where sal=(select max(sal) from emp);
注意:selectename, max(sal) from emp;这语句执行的时候会报错,说ORA-00937:非单组分组函数。因为max是分组函数,而ename不是分组函数.......
但是selectmin(sal), max(sal) from emp;这句是可以执行的。因为min和max都是分组函数,就是说:如果列里面有一个分组函数,其它的都必须是分组函数,否则就出错。这是语法规定的问题:如何显示所有员工的平均工资和工资总和?
问题:如何计算总共有多少员工问题:如何
扩展要求:
查询最高工资员工的名字,工作岗位
SELECT ename, job, sal FROM emp e where sal= (SELECT MAX(sal) FROM emp);
显示工资高于平均工资的员工信息
SELECT * FROM emp e where sal > (SELECTAVG(sal) FROM emp);
groupby 和 having子句
groupby用于对查询的结果分组统计 having子句用于限制分组显示结果
问题:如何显示每个部门的平均工资和最高工资?
SELECT AVG(sal), MAX(sal), deptno FROM empGROUP by deptno;
(注意:这里暗藏了一点,如果你要分组查询的话,分组的字段deptno一定要出现在查询的列表里面,否则会报错。因为分组的字段都不出现的话,就没办法分组了)
问题:显示每个部门的每种岗位的平均工资和最低工资?
SELECT min(sal), AVG(sal), deptno, job FROMemp GROUP by deptno, job;
问题:显示平均工资低于2000的部门号和它的平均工资?
SELECT AVG(sal), MAX(sal), deptno FROM empGROUP by deptno having AVG(sal) < 2000;
对数据分组的总结
1 分组函数只能出现在选择列表、having、order by子句中(不能出现在where中)
2 如果在select语句中同时包含有groupby, having, order by 那么它们的顺序是group by, having, order by
3 在选择列中如果有列、表达式和分组函数,那么这些列和表达式必须有一个出现在group by 子句中,否则就会出错。
如SELECTdeptno, AVG(sal), MAX(sal) FROM emp GROUP by deptno HAVING AVG(sal) < 2000;
这里deptno就一定要出现在group by 中
问题:显示雇员名,雇员工资及所在部门的名字【笛卡尔集】?
规定:多表查询的条件是 至少不能少于 表的个数-1 才能排除笛卡尔集
(如果有N张表联合查询,必须得有N-1个条件,才能避免笛卡尔集合)
SELECT e.ename, e.sal, d.dname FROM emp e,dept d WHERE e.deptno = d.deptno;
问题:显示部门号为10的部门名、员工名和工资?
SELECT d.dname, e.ename, e.sal FROM emp e,dept d WHERE e.deptno = d.deptno and e.deptno = 10;
问题:显示各个员工的姓名,工资及工资的级别?
先看salgrade的表结构和记录
SQL>select * from salgrade;
GRADE LOSAL HISAL
------------- ------------- ------------
1 700 1200
2 1201 1400
3 1401 2000
4 2001 3000
5 3001 9999
SELECT e.ename, e.sal, s.grade FROM emp e,salgrade s WHERE e.sal BETWEEN s.losal AND s.hisal;
扩展要求:
问题:显示雇员名,雇员工资及所在部门的名字,并按部门排序?
SELECT e.ename, e.sal, d.dname FROM emp e,dept d WHERE e.deptno = d.deptno ORDER by e.deptno;
(注意:如果用groupby,一定要把e.deptno放到查询列里面)
自连接
自连接是指在同一张表的连接查询
问题:显示某个员工的上级领导的姓名?
比如显示员工‘FORD’的上级
SELECT worker.ename, boss.ename FROM emp worker,emp boss WHERE worker.mgr = boss.empno AND worker.ename ='FORD';
请思考:显示与SMITH同部门的所有员工?
思路:
1 查询出SMITH的部门号
select deptno from emp WHERE ename = 'SMITH';
2 显示
SELECT * FROM emp WHERE deptno = (select deptno from emp WHERE ename= 'SMITH');
数据库在执行sql 是从左到右扫描的, 如果有括号的话,括号里面的先被优先执行。
请思考:如何查询和部门10的工作相同的雇员的名字、岗位、工资、部门号
SELECT DISTINCT job FROM emp WHERE deptno = 10;
SELECT * FROM emp WHERE job IN(SELECT DISTINCT job FROM emp WHERE deptno = 10);
(注意:不能用job=..,因为等号=是一对一的)
在多行子查询中使用all操作符
问题:如何显示工资比部门30的所有员工的工资高的员工的姓名、工资和部门号?
SELECT ename, sal, deptno FROM emp WHERE sal > all (SELECT sal FROM emp WHERE deptno = 30);
扩展要求:
大家想想还有没有别的查询方法。
SELECT ename, sal, deptno FROM emp WHERE sal > (SELECT MAX(sal) FROM emp WHERE deptno = 30);
执行效率上, 函数高得多
在多行子查询中使用any操作符
问题:如何显示工资比部门30的任意一个员工的工资高的员工姓名、工资和部门号?
SELECT ename, sal, deptno FROM emp WHERE sal > ANY (SELECT sal FROM emp WHERE deptno = 30);
扩展要求:
大家想想还有没有别的查询方法。
SELECT ename, sal, deptno FROM emp WHERE sal > (SELECT min(sal)FROM emp WHERE deptno = 30);
多列子查询
单行子查询是指子查询只返回单列、单行数据,多行子查询是指返回单列多行数据,都是针对单列而言的,而多列子查询是指查询返回多个列数据的子查询语句。
请思考如何查询与SMITH的部门和岗位完全相同的所有雇员。
SELECT deptno, job FROM emp WHERE ename = 'SMITH';
SELECT * FROM emp WHERE (deptno, job) = (SELECT deptno, job FROM empWHERE ename = 'SMITH');
在from子句中使用子查询
请思考:如何显示高于自己部门平均工资的员工的信息
思路:
1. 查出各个部门的平均工资和部门号
SELECT deptno, AVG(sal) mysal FROM empGROUP by deptno;
2. 把上面的查询结果看做是一张子表
SELECT e.ename, e.deptno, e.sal, ds.mysalFROM emp e, (SELECT deptno, AVG(sal) mysal FROM emp GROUP by deptno) ds WHEREe.deptno = ds.deptno AND e.sal > ds.mysal;
如何衡量一个程序员的水平?
网络处理能力, 数据库, 程序代码的优化程序的效率要很高
小总结:
在这里需要说明的当在from子句中使用子查询时,该子查询会被作为一个视图来对待,因此叫做内嵌视图,当在from子句中使用子查询时,必须给子查询指定别名。
注意:别名不能用as,如:SELECT e.ename, e.deptno, e.sal,ds.mysal FROM emp e, (SELECT deptno, AVG(sal) mysal FROM emp GROUP by deptno)as ds WHERE e.deptno = ds.deptno AND e.sal > ds.mysal;
在ds前不能加as,否则会报错 (给表取别名的时候,不能加as;但是给列取别名,是可以加as的)
10.oracle分页查询
mysql: select * from 表名 where 条件 limit 从第几条取,取几条 见mysql分页查询
sql server: select top 取几条 * from 表名 where id notin(select top 4 id from 表名 where 条件) 也可以使用行集函数 见3.sql server分页查询
排除前4条,再取4条,这个案例实际上是取5-8条
oracle:
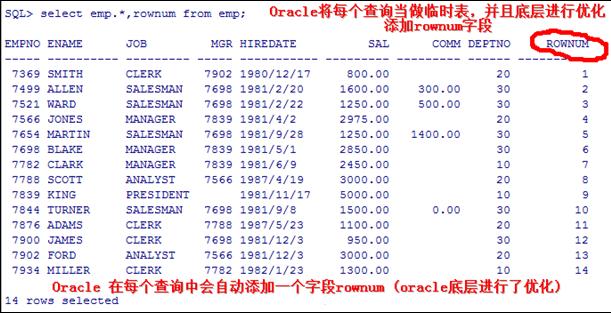
以scott/tiger账号登陆进行查询:[分页查询模板]
select t2.* from
(selectt1.*,rownum rn from
(select * from emp) t1
where rownum<=6) t2 where rn>=4;
先找到小于6的然后找到大于4的
【顺序可以反】
select t2.* from
(selectt1.*,rownum rn from
(select * from emp) t1
where rownum>=4) t2 where rn<=6;
oracle使用三层过滤:
第一层:select * fromemp
第二层:selectt1.*,rownum rn from (select * from emp) t1
whererownum<=6
第三层: select t2.* from
(selectt1.*,rownum rn from
(select * from emp) t1
where rownum<=6) t2 where rn>=4;
上面是一个分页模板,6表示取到第几条,4表示从第几条取
(1)删除重复记录
在几千条记录里,存在着些相同的记录,请用sql语句删除。
【注意】1.表中肯定是没有主键的,这才叫记录相同
2.若有主键(主键肯定不同),那请你把其他字段变成一个临时表,再使用下面方法
准备:
- --创建表
- create table people(
- peopleId number,
- peopleName varchar(50),
- peopleAge number);
-
- --插入数据
- insert into people values(1,'haozl',22);
- insert into people values(2,'wangx',23);
- insert into people values(3,'liwr',24);
- insert into people values(4,'zhanggh',25);
- insert into people values(5,'cheng',26);
- --自我复制
- insert into people(peopleId,peopleName,peopleAge) (select peopleId,peopleName,peopleAge from people);
- insert into people values(6,'hancl',27);
- insert into people values(7,'yangqp',22);
- insert into people values(8,'wangt',23);
- insert into people values(9,'nieyp',18);
- insert into people values(10,'tianx',19);
- insert into people(peopleId,peopleName,peopleAge) (select peopleId,peopleName,peopleAge from people);
- insert into people values(11,'hansm',41);
- insert into people values(12,'haog',31);
- insert into people values(13,'chengyy',51);
- insert into people values(14,'chenmm',61);
- insert into people values(15,'xujf',11);
- insert into people(peopleId,peopleName,peopleAge) (select peopleId,peopleName,peopleAge from people);
- insert into people values(16,'wanggl',23);
- insert into people values(17,'dujl',32);
- insert into people values(18,'gaozg',28);
- insert into people values(19,'haow',27);
- insert into people values(20,'lizy',25);
- --统计重复个数
- select peopleId,COUNT(peopleId) from people group by peopleId having COUNT(peopleId)>1;
-
- --查询具体重复记录(单个字段)
- select distinct * from people where peopleId in
- (select peopleId from people group by peopleId having COUNT(peopleId)>1);
-
- --查询具体重复记录(多个字段)
- select distinct * from people a where (peopleId,a.peoplename) in
- (select peopleId,peoplename from people group by peopleId,peoplename having COUNT(*)>1);
-
-
- savepoint savepoint1;--使用事务
- --删除表中多余记录(多个字段)
- delete from people a where (a.peopleId,a.peoplename) in
- (select peopleId,peoplename from people group by peopleId,peoplename having COUNT(*)>1)
- and
- rowid not in
- (select min(rowid) from people group by peopleId,peoplename having COUNT(*)>1);
- rollback to savepoint1;--还原

11.oracle合并查询
有时在实际应用中,为了合并多个select语句的结果,可以使用集合操作符号union,union all,intersect,minus 多用于数据量比较大的数据局库,运行速度快。
1).union
该操作符用于取得两个结果集的并集。当使用该操作符时,会自动去掉结果集中重复行。
SELECT ename, sal, job FROM emp WHERE sal>2500
UNION
SELECT ename, sal, job FROM emp WHERE job ='MANAGER';
2).unionall
该操作符与union相似,但是它不会取消重复行,而且不会排序。
SELECT ename, sal, job FROM emp WHERE sal>2500
UNION ALL
SELECT ename, sal, job FROM emp WHERE job ='MANAGER';
该操作符用于取得两个结果集的并集。当使用该操作符时,会自动去掉结果集中重复行。
3).intersect 使用该操作符用于取得两个结果集的交集。
SELECT ename, sal, job FROM emp WHERE sal>2500
INTERSECT
SELECT ename, sal, job FROM emp WHERE job ='MANAGER';
4).minus 使用改操作符用于取得两个结果集的差集,他只会显示存在第一个集合中,而不存在第二个集合中的数据。
SELECT ename, sal, job FROM emp WHERE sal>2500
MINUS
SELECT ename, sal, job FROM emp WHERE job ='MANAGER';
(MINUS就是减法的意思)12.oracle连接
(1)内连接:使我们用的最多的一种连接,前面我们使用的都是内连接。
eg:显示员工的信息和部门名称
select emp.ename,dept.dname fromemp,dept whereemp.deptno=dept.deptno;
等价于
select emp.ename,dept.dname from emp inner join deptonemp.deptno=dept.deptno;
基本语法:select 字段1, 字段2… from表名1inner join表名2on条件
(2)外连接:
我们创建2种表做测试:
--表stu
id name
1 Jack
2 Tom
3 Kity
4 Nono
create tablestu(id number,
name varchar2(4));
insert into stuvalues(1,'Jack');
insert into stuvalues(2,'Tom');
insert into stuvalues(3,'Kity');
insert into stuvalues(4,'Nono');--表exam
id grade
1 56
2 76
11 80
3 65
create tableexam(id number,
grade number);
insert into examvalues(1,56);
insert into examvalues(2,76);
insert into examvalues(11,80);
insert into examvalues(3,65);
①左外连接(显示所有人的成绩,如果没有成绩,也要显示该人的姓名和id号,成绩显示为空)
selectstu.id,stu.name,exam.grade from stuleftjoinexam on stu.id=exam.id;
有的程序员喜欢这样写 左外连接:
select stu.id,stu.name,exam.grade from stu,exam wherestu.id=exam.id(+);
ID NAME GRADE
左外连接------ ------------
1 Jack 56
2 Tom 76
3 Kity 65
4 Nono
ID NAME GRADE
右外连接------ ------------
1 Jack 56
2 Tom 76
3 Kity 65
80
②右外连接(显示所有成绩,如果没有名字匹配,显示为空)
selectstu.id,stu.name,exam.grade from sturightjoinexam onstu.id=exam.id;
有的程序员喜欢这样写 左外连接:
select stu.id,stu.name,exam.gradefrom stu,examwhere stu.id(+)=exam.id;
③完全外连接(显示所有成绩和所有人的名字,如果响应的匹配值,则显示为空)不管有无匹配均显示
selectstu.id,stu.name,exam.grade from stufullouterjoin exam on stu.id=exam.id;
13.oracle函数
(1)字符函数
字符函数是oracle中最常用的函数,我们来看看有哪些字符函数:
lower(char):将字符串转化为小写的格式.
upper(char):将字符串转化为大写的格式.
length(char):返回字符串的长度。
substr(char,m,n):取字符串的子串;n代表取n个的意思,不是代表取到第n个
replace(char1,search_string,replace_string)
instr(char1,char2,[,n[,m]])取子串在字符串的位置
问题:将所有员工的名字按小写的方式显示
SQL> select lower(ename) from emp;
问题:将所有员工的名字按大写的方式显示。
SQL> select upper(ename) from emp;
问题:显示正好为5个字符的员工的姓名。
SQL> select * from emp where length(ename)=5;
问题:显示所有员工姓名的前三个字符。
SQL> select substr(ename,1,3) from emp;
问题:以首字母大写,后面小写的方式显示所有员工的姓名。
SQL> select upper(substr(ename,1,1)) || lower(substr(ename,2,length(ename)-1)) from emp;
问题:以首字母小写,后面大写的方式显示所有员工的姓名。
SQL> select lower(substr(ename,1,1)) || upper(substr(ename,2,length(ename)-1)) from emp;
问题:显示所有员工的姓名,用“我是老虎”替换所有“A”
SQL> select replace(ename,'A', '我是老虎') from emp;
(2)数学函数
数学函数的输入参数和返回值的数据类型都是数字类型的。数学函数包括cos,cosh,exp,ln, log,sin,sinh,sqrt,tan,tanh,acos,asin,atan,round,我们讲最常用的:
round(n,[m])该函数用于执行四舍五入,如果省掉m,则四舍五入到整数,如果m是正数, 则四舍五入到小数点的m位后。如果m是负数,则四舍五入到小数点的m位前。
trunc(n,[m]) 该函数用于截取数字。若省掉m,就截去小数部分(等价于trunc(n,0)),如 果m是正数就截取到小数点的m位后,若m是负数,则截取到小数点的前m位。
mod(m,n)
floor(n) 返回小于或是等于n的最大整数
ceil(n) 返回大于或是等于n的最小整数
问题:显示在一个月为30天的情况下,所有员工的日薪金,忽略余数。
SQL> select trunc(sal/30), ename from emp;
or
SQL> select floor(sal/30), ename from emp;
在做oracle测试的时候,可以使用dual表
select mod(10,2) from dual;结果是0
select mod(10,3) from dual;结果是1
其它的数学函数,有兴趣的同学可以自己去看看:abs(n): 返回数字n的绝对值
select abs(-13) from dual;
acos(n): 返回数字的反余弦值
asin(n): 返回数字的反正弦值
atan(n): 返回数字的反正切值
cos(n):
exp(n): 返回e的n次幂
log(m,n): 返回对数值
power(m,n): 返回m的n次幂
(3)日期函数
日期函数用于处理date类型的数据。
默认情况下日期格式是dd-mon-yy即12-7月-78
(1)sysdate: 该函数返回系统时间
(2)add_months(d,n)在日期d上增加n个月
(3)last_day(d):返回指定日期所在月份的最后一天
问题:查找已经入职8个月多的员工
SQL> select * from emp wheresysdate>=add_months(hiredate,8);
问题:显示满10年服务年限的员工的姓名和受雇日期。
SQL> select ename, hiredate from emp
where sysdate>=add_months(hiredate,12*10);
问题:对于每个员工,显示其加入公司的天数。
SQL> select floor(sysdate-hiredate) "入职天数",ename fromemp;
or
SQL> select trunc(sysdate-hiredate) "入职天数",ename fromemp;
(4)给表取别名的时候,不能加as;但是给列取别名,是可以加as
问题:找出各月倒数第3天受雇的所有员工。
SQL> select hiredate,ename from emp wherelast_day(hiredate)-2=hiredate;
(5)转换函数
转换函数用于将数据类型从一种转为另外一种。在某些情况下,oracle server允许值的数据类型和实际的不一样,这时oracle server会隐含的转化数据类型
比如:
create table t1(idint);//这里 注意int不是关键字在oracle下
insert into t1 values('10');-->这样oracle会自动的将10 -->'10 ’
create table t2 (id varchar2(10));
insert into t2 values(1); -->这样oracle就会自动的将1 -->'1';
我们要说的是尽管oracle可以进行隐含的数据类型的转换,但是它并不适应所有的情况,为了提高程序的可靠性,我们应该使用转换函数进行转换。
(6) to_char(date,'format')
你可以使用select ename, hiredate, sal from emp where deptno =10;显示信息,可是,在某些情况下,这个并不能满足你的需求。
问题:日期是否可以显示 时/分/秒
SQL> select ename, to_char(hiredate, 'yyyy-mm-ddhh24:mi:ss') from emp;
问题:薪水是否可以显示指定的货币符号
SQL>
yy:两位数字的年份2004-->04
yyyy:四位数字的年份 2004年
mm:两位数字的月份 8月-->08
dd:两位数字的天 30号-->30
hh24: 8点-->20
hh12:8点-->08
mi、ss-->显示分钟\秒
SQL> select to_char(sysdate,'day') from dual;
显示:星期五
set serveroutput on;
if to_char(sysdate,'day') in ('星期日','星期六') then
dbms_output.put_line('对不起,休息日不能删除员工');
end if;
9:显示数字,并忽略前面0
0:显示数字,如位数不足,则用0补齐
.:在指定位置显示小数点
,:在指定位置显示逗号
$:在数字前加美元
L:在数字前面加本地货币符号
C:在数字前面加国际货币符号
G:在指定位置显示组分隔符、
D:在指定位置显示小数点符号(.)
问题:显示薪水的时候,把本地货币单位加在前面
SQL> select ename, to_char(hiredate,'yyyy-mm-dd hh24:mi:ss'), to_char(sal,'L99999.99')from emp;
问题:显示1980年入职的所有员工
SQL> select * from emp where to_char(hiredate, 'yyyy')=1980;
问题:显示所有12月份入职的员工
SQL> select * from emp where to_char(hiredate, 'mm')=12;
这里的12和1980可以加''也可以不加,因为Oracle会自动转换,但是最好加。
(7) to_date(string,'format')
函数to_date用于将字符串转换成date类型的数据。
问题:能否按照中国人习惯的方式年—月—日添加日期。
SQL> create table test1(id date);
SQL> insert into test1 values(to_date('2005-11-11','YYYY-MM-DD'));
1 row inserted
(8)系统函数
sys_context
1)terminal:当前会话客户所对应的终端的标示符
2)lanuage: 语言
3)db_name: 当前数据库名称
4)nls_date_format: 当前会话客户所对应的日期格式
5)session_user: 当前会话客户所对应的数据库用户名
6)current_schema:当前会话客户所对应的默认方案名
7)host: 返回数据库所在主机的名称
通过该函数,可以查询一些重要信息,比如你正在使用哪个数据库?
SQL>select sys_context('USERENV','db_name') fromdual;
SYS_CONTEXT('USERENV','DB_NAME
--------------------------------------------------------------------------------
zhulin
注意:USERENV是固定的,不能改的,db_name可以换成其它,比如lanuage SQL>sys_context('USERENV','lanuage') from dual;
SYS_CONTEXT('USERENV','LANGUAG
--------------------------------------------------------------------------------
AMERICAN_AMERICA.ZHS16GBK
SQL>sys_context('USERENV','current_schema')from dual;
SYS_CONTEXT('USERENV','CURRENT
--------------------------------------------------------------------------------
XIAOQIANG
14.oracle创建数据库实例
1). 通过oracle提供的向导工具。
database Configuration Assistant 【数据库配置助手】
2).我们可以用手工步骤直接创建。
☞但我们创建完一个新的数据库实例后,在服务中(services.exe)中就会有两个新的服务创建,这时,你根据实际需要去启动相应的数据库实例。
☞在同一台机器允许同时启动多个数据库实例,我们在登录或链接的时候需要指定主机字符串(SID )
这是通过sqlplus客户端连接数据库时有多个实例采用下面DOS命令:sqlplus scott/tiger@zhulin
15.java操作oracle
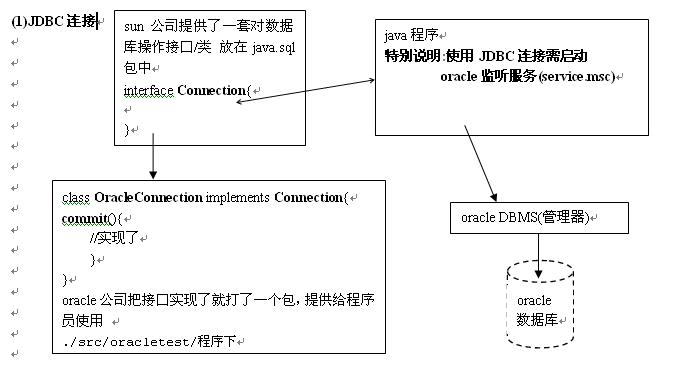
补充一下:
SQL语句分类:
DML语句:数据操作语句(insert、update、delete)
DDL语句:数据定义语言(create table、drop table..)
DQL语句:数据查询语言(select)
对于使用java去查询oracle会出现一个很奇怪的现象?
PL/SQL Developer看到的数据库,可能和java程序中看到的数据不一致,这是事务控制引起的。
对java连接oracle 封装成一个OracleSQLHelper类。
//3.创建 PrepareedStatement或Statement接口引用对象
//Statement用处:主要用于发送sql语句到数据库
//PrepareedStatement:会进行预编译,适合批量的sql语句,有效防止危险字符注入
//PrepareedStatement支持在sql语句中出现问号?作为参数带进去!!!!!!!!!!!!!!!!!!!!!!
我们把连接数据库的配置信息写到一个文件中去,这样代码更加灵活。
这里有一个Java技巧,快速提供类的get和set方法:
然后弹出一个窗口:
最后OK。
(2)JDBC-ODBC连接
配置数据源——管理工具(Administrativetools)——ODBC——userDSN——Add添加ODBC数据源
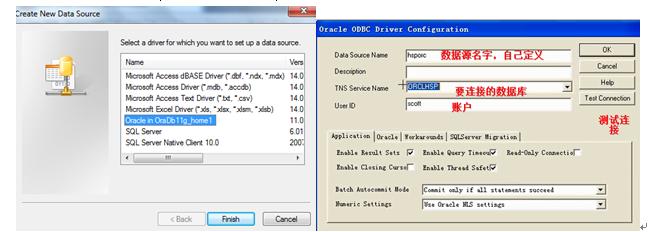
java代码做相应的修改:【与SQLServer一样的】//sun.jdbc.odbc.JdbcOdbcDriver本身自带
Class.Forname("sun.jdbc.odbc.JdbcOdbcDriver");
Connectionct=DriverManager.getConnection("jdbc:odbc:hsporc","scott","tiger");
这里hsporc就是你ODBC数据源名称了。。。。。。
什么时候用JDBC或JDBC-ODBC?
原则:若java程序和DB不在同一机器上,我们一般使用JDBC
若java程序和DB在同一机器上,我们一般使用JDBC-ODBC
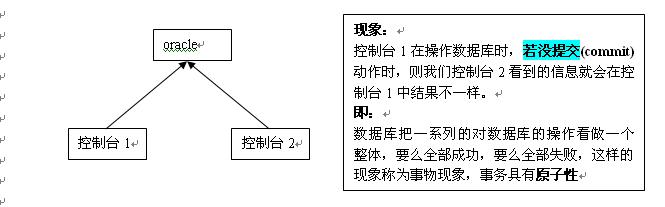
16.oracle事务处理
什么是事务
事务用于保证数据的一致性,它由一组相关的dml语句组成,该组的dml(数据操作语言,增删改,没有查询)语句要么全部成功,要么全部失败。
如:网上转账就是典型的要用事务来处理,用于保证数据的一致性。
dml 数据操作语言 银行转账、QQ申请、车票购买
事务和锁
当执行事务操作时(dml语句),oracle会在被作用的表上加锁,防止其它用户修改表的结构。这里对我们的用户来来讲是非常重要的。
.....其它进程排序,知道1号进程完成,锁打开,2号进程进入。依次进行,如果有进程级别较高的,可以插队。
提交事务
当执行用commit语句可以提交事务。当执行了commit语句之后,会确认事务的变化、结束事务。删除保存点、释放锁,当使用commit语句结束事务之后,其它会话将可以查看到事务变化后的新数据。
保存点就是为回退做的。保存点的个数没有限制
回退事务
在介绍回退事务前,我们先介绍一下保存点(savepoint)的概念和作用。保存点是事务中的一点。用于取消部分事务,当结束事务时,会自动的删除该事务所定义的所有保存点。当执行rollback时,通过指定保存点可以回退到指定的点,这里我们作图说明。
事务的几个重要操作
1.设置保存点 savepoint a
2.取消部分事务 rollback to a
3.取消全部事务 rollback
每个保存点都只有一次回退的机会 设置保存点是有资源开销的 一旦commit了事务则不能回退
注意:这个回退事务,必须是没有commit前使用的;如果事务提交了,那么无论你刚才做了多少个保存点,都统统没有。 如果没有手动执行commit,而是exit了,那么会自动提交
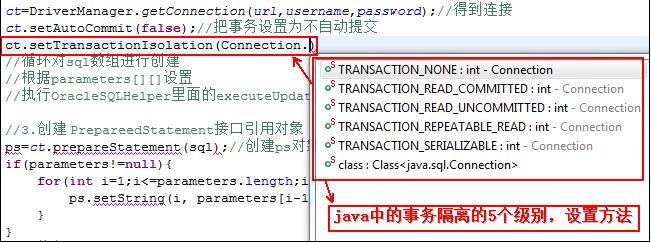
java程序中如何使用事务 ./src/oracle_test/test_oracle_transaction_vital.java
//事先先设置成不自动提交
//事务开始
update emp set=?
insert…
update…
commit();
如果一个事务中,只有select则事务可以忽略,若一个事务有多个(update,insert,delete)则需要考虑事务。
事务的隔离级别:定义了事务与事务之间的隔离程度。
ANSI/ISOSQL92国际标准化组织定义了一个标准,不同的数据库在实现时有所不同。
| 隔离级别 | 脏读 | 不可重复读 | 幻读 |
| 读未提交(Read uncommitted) | √ | √ | √ |
| 读已提交(Read committed) | × | √ | √ |
| 可重复读(Repeatable read) | × | × | √ |
| 可串行化(Serializable) | × | × | × |
×不会出现 √可能出现
oracle提供了三种隔离级别:读已提交、可串行化、(Read Only 非ANSI/ISO SQL92标准)
脏读(dirty read):当事务A读取事务B尚未提交的修改时,产生脏读。在oracle中不会出现
不可重复读(nonrepeatable read):同一查询在同一事务中多次进行,由于其他提交事务所在的修改或删除,每次返回不同的结果集,此时发生非重复读。
幻读(phantom read):同一查询在同一事务中多次进行,由于其他提交事务所做的插入操作,每次返回不同的结果集(结果集到底是对还是错?),此时发生幻读。
oracle中设置事务隔离级别:
设置一个事务的隔离级别:
set transactionisolation level read committed;(默认级别)
set transactionisolation level serializable;(手动)
设置整个会话的隔离级别:
alter session setisolation_level serializable;
alter session setisolation_level read committed;
java程序中设置事务隔离级别: public Connection ct=null;
说明:一般情况下,我们java程序员无需设置事务的隔离级别。
17.oracle数据完整性
约束:用于确保数据库数据满足特定的商业规则。在oracle中,约束包括:not null、 unique, primary key, foreign key,和check五种。
not null(非空)
如果在列上定义了not null,那么当插入数据时,必须为列提供数据。
unique(唯一)
当定义了唯一约束后,该列值是不能重复的,但是可以为null。
primary key(主键)n
用于唯一的标示表行的数据,当定义主键约束后,该列不但不能重复而且不能为null。
需要说明的是:一张表最多只能有一个主键,但是可以有多个unqiue约束。
foreign key(外键)
用于定义主表和从表之间的关系。外键约束要定义在从表上,主表则必须具有主键约束或是unique约束,当定义外键约束后,要求外键列数据必须在主表的主键列存在或是为null。
check
用于强制行数据必须满足的条件,假定在sal列上定义了check约束,并要求sal列值在1000-2000之间如果不在1000-2000之间就会提示出错。
商店售货系统表设计案例
现有一个商店的数据库,记录客户及其购物情况,由下面三个表组成:商品goods(商品号goodsId,商品名goodsName,单价 unitprice,商品类别category,供应商provider);
客户customer(客户号customerId,姓名name,住在address,电邮email,性别sex,身份证cardId);
购买purchase(客户号customerId,商品号goodsId,购买数量nums);
请用SQL语言完成下列功能:
1. 建表,在定义中要求声明:
(1). 每个表的主外键;
(2). 客户的姓名不能为空值;
(3). 单价必须大于0,购买数量必须在1到30之间;
(4). 电邮不能够重复;
(5). 客户的性别必须是 男 或者 女,默认是男;
SQL> createtable goods(goodsId char(8) primary key,--主键
goodsName varchar2(30),
unitprice number(10,2) check(unitprice>0),
category varchar2(8),
provider varchar2(30)
);
SQL> createtable customer( customerId char(8) primary key, --主键
name varchar2(50) not null, --不为空
address varchar2(50),
email varchar2(50) unique,
sex char(2) default'男' check(sex in ('男','女')),
-- 一个char能存半个汉字,两位char能存一个汉字
cardId char(18)
);
SQL> createtable purchase( customerId char(8) referencescustomer(customerId),
goodsId char(8) referencesgoods(goodsId),
nums number(10)check (nums between 1 and 30)
);
表是默认建在SYSTEM表空间的
维护
商店售货系统表设计案例(2)
如果在建表时忘记建立必要的约束,则可以在建表后使用alter table命令为表增加约束。但是要注意:增加not null约束时,需要使用modify选项,而增加其它四种约束使用add选项。
1. 增加商品名也不能为空
SQL> altertable goods modify goodsName notnull;
2. 增加身份证也不能重复
SQL> altertable customer add constraint xxxxxx unique(cardId);
3. 增加客户的住址只能是’海淀’,’朝阳’,’东城’,’西城’,’通州’,’崇文’,’昌平’;
SQL> altertable customer add constraint yyyyyycheck (address in (’海淀’,’朝阳’,’东城’,’西城’,’通州’,’崇文’,’昌平’));
删除约束
当不再需要某个约束时,可以删除。
alter table 表名 drop constraint 约束名称;
特别说明一下:
在删除主键约束的时候,可能有错误,比如:
alter table 表名 drop primary key;
这是因为如果在两张表存在主从关系,那么在删除主表的主键约束时,必须带上cascade选项 如像:
alter table 表名 drop primary key cascade;
显示约束信息
1.显示约束信息
通过查询数据字典视图user_constraints,可以显示当前用户所有的约束的信息。
selectconstraint_name, constraint_type, status, validated from user_constraints where table_name = '表名';
2.显示约束列
通过查询数据字典视图user_cons_columns,可以显示约束所对应的表列信息。
selectcolumn_name, position from user_cons_columnswhere constraint_name = '约束名';
3.当然也有更容易的方法,直接用pl/sql developer查看即可。简单演示一下下...
表级定义 列级定义
列级定义
列级定义是在定义列的同时定义约束。
如果在department表定义主键约束
create tabledepartment4(dept_id number(12) constraintpk_department primary key,
name varchar2(12),loc varchar2(12));
表级定义
表级定义是指在定义了所有列后,再定义约束。这里需要注意:
not null约束只能在列级上定义。
外键:
以在建立employee2表时定义主键约束和外键约束为例:
create tableemployee2(emp_id number(4), name varchar2(15),
dept_id number(2),constraint pk_employee primary key(emp_id),
constraint fk_department foreign key (dept_id) referencesdepartment4(dept_id));
18.oracle 序列(sequence)
需求:在某张表中,存在一个id列(整数),我们希望添加记录的时候,该列从1开始,自动的增长
解决方式:oracle是利用(sequence)来完成的
序列特点:由用户创建数据库对象,可由多个用户共享(system可以使用scott创建的序列),一般用于主键或唯一列,可为表中的列自动产生值。
问题:若system使用scott的序列,从什么开始增长? 答案:接着增长
insert into test1values(scott.myseq.nextval,'kkk');
eg:创建一个序列:
create sequencemyseq --创建开始
start with 1 --从1开始
increment by 1 --每次增长1
minvalue 1 --最小值
maxvalue 30000 --最大值
cycle //cycle表示当序列增加30000,重新从1开始,如果不希望,就nocycle
nocache; --不缓存,而 cache 10;表示一次产生10个号共你使用,缺点可能会跳号,但提供效率
使用序列创建一张表:
create tabletest1(id number primary key,name varchar2(32));
insert into test1values(myseq.nextval,'abc');
insert into test1values(myseq.nextval,'dc');
insert into test1values(myseq.nextval,'ac');
insert into test1values(myseq.nextval,'ec');
说明:myseq:表示序列名字,nextval:这是一个关键字,序列的一个函数
[序列不是在表定义中附加]是在添加数据时使用
selectscott.myseq.currvalfrom dual; 查看当前序号
何时使用sequence:
不包含子查询、snapshot、view、select的语句中,经常使用在insert(子查询)、update语句中。
在sql server和mysql中都是可以在定义表的时候,直接给指定自增长:
- sql server:
- create table temp1(
- id int primary key identity(1,1),
- name varchar(36));
-
- mysql:
- create table temp1(
- id int primary key auto_incrment,
- name varchar(36));
19.oracle 索引
索引是用于加速数据存取的数据对象。合理的使用索引可以大大降低i/o次数,从而提高数据访问性能。索引有很多种我们主要介绍常用的几种:
为什么添加了索引后,会加快查询速度呢?
创建索引
单列索引
单列索引是基于单个列所建立的索引,比如:
create index 索引名 on 表名(列名);
复合索引
复合索引是基于两列或是多列的索引。在同一张表上可以有多个索引,但是要求列的组合必须不同,比如:
create indexemp_idx1 on emp (ename, job);
create indexemp_idx1 on emp (job, ename);
使用原则
1. 在大表上建立索引才有意义
2. 在where子句或是连接条件上经常引用的列上建立索引
3. 索引的层次不要超过4层
索引的缺点
索引缺点分析
索引有一些先天不足:
1. 建立索引,系统要占用大约为表1.2倍的硬盘和内存空间来保存索引。
2. 更新数据的时候,系统必须要有额外的时间来同时对索引进行更新,以维持数据和索引的一致性。
实践表明,不恰当的索引不但于事无补,反而会降低系统性能。因为大量的索引在进行插入、修改和删除操作时比没有索引花费更多的系统时间。
比如在如下字段建立索引应该是不恰当的:
1. 很少或从不引用的字段;
2. 逻辑型的字段,如男或女(是或否)等。
综上所述,提高查询效率是以消耗一定的系统资源为代价的,索引不能盲目的建立,这是考验一个DBA是否优秀的很重要的指标。
其它索引
介绍
按照数据存储方式,可以分为B*树、反向索引、位图索引;
按照索引列的个数分类,可以分为单列索引、复合索引;
按照索引列值的唯一性,可以分为唯一索引和非唯一索引。
此外还有函数索引,全局索引,分区索引...
对于索引我还要说:
在不同的情况,我们会在不同的列上建立索引,甚至建立不同种类的索引,请记住,技术是死的,人是活的。比如:
B*树索引建立在重复值很少的列上,而位图索引则建立在重复值很多、不同值相对固定的列上。
显示索引信息
显示表的所有索引
在同一张表上可以有多个索引,通过查询数据字典视图dba_indexs和user_indexs,可以显示索引信息。其中dba_indexs用于显示数据库所有的索引信息,而user_indexs用于显示当前用户的索引信息:
select index_name,index_type from user_indexes where table_name ='表名';
显示索引列
通过查询数据字典视图user_ind_columns,可以显示索引对应的列的信息
select table_name,column_name from user_ind_columns where index_name = 'IND_ENAME';
你也可以通过pl/sqldeveloper工具查看索引信息
20.oracle管理权限和角色
这一部分我们主要看看oracle中如何管理权限和角色,权限和角色的区别在那里。
当刚刚建立用户时,用户没有任何权限,也不能执行任何操作。如果要执行某种特定的数据库操作,则必须为其授予系统的权限;如果用户要访问其它方案的对象,则必须为其授予对象的权限。为了简化权限的管理,可以使用角色。这里我们会详细的介绍。看图:
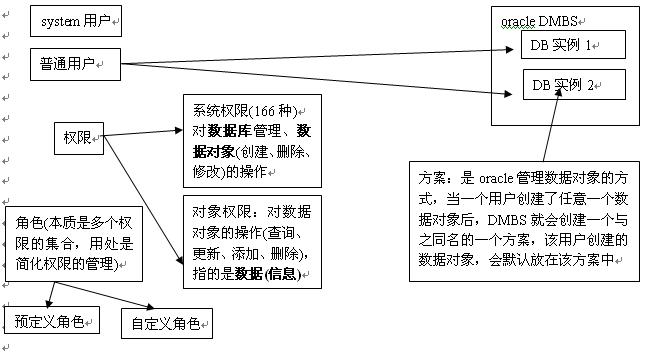
权限是指执行特定类型sql命令或是访问其它方案对象的权利,包括系统权限和对象权限两种。
系统权限是指执行特定类型sql命令的权利。它用于控制用户可以执行的一个或是一组数据库操作。比如当用户具有createtable权限时,可以在其方案中建表,当用户具有create any table权限时,可以在任何方案中建表。oracle提供了100多种系统权限。
常用的有:
| 英文 | 中文 | 英文 | 中文 |
| create session | 连接数据库 | create table | 建表 |
| create view | 建视图 | create public synonym | 建同义词 |
| create procedure | 建过程、函数、包 | create trigger | 建触发器 |
| create cluster | 建簇 |
|
|
显示系统权限
oracle提供了100多种系统权限,而且oracle的版本越高,提供的系统权限就越多,我们可以查询数据字典视图system_privilege_map,可以显示所有系统权限。
select * from system_privilege_maporder by name;
授予系统权限
一般情况,授予系统权限是由DBA完成的,如果用其他用户来授予系统权限,则要求该用户必须具有grantany privilege的系统权限。在授予系统权限时,可以带有with admin option选项,这样,被授予权限的用户或是角色还可以将该系统权限授予其它的用户或是角色。为了让大家快速理解,我们举例说明:
1.创建两个用户ken,tom。初始阶段他们没有任何权限,如果登录就会给出错误的信息。
create user ken identfied by ken;
2 给用户ken授权
1). grant createsession, create table to ken with adminoption;
2). grant createview to ken;
3 给用户tom授权
我们可以通过ken给tom授权,因为with admin option是加上的。当然也可以通过dba给tom授权,我们就用ken给tom授权:
1. grant createsession, create table to tom;
2. grant createview to ken; --ok吗?不ok ,因为没有带上withadmin option
回收系统权限
一般情况下,回收系统权限是dba来完成的,如果其它的用户来回收系统权限,要求该用户必须具有相应系统权限及转授系统权限的选项(with admin option)。回收系统权限使用revoke来完成。
当回收了系统权限后,用户就不能执行相应的操作了,但是请注意,系统权限级联收回的问题?[不是级联回收]
system--------->ken ---------->tom
(createsession)(create session)( create session)
用system执行如下操作:
revoke createsession from ken; --请思考tom还能登录吗?
答案:能,可以登录
对象权限
指访问其它方案对象的权利,用户可以直接访问自己方案的对象,但是如果要访问别的方案的对象,则必须具有对象的权限。比如smith用户要访问scott.emp表(scott:方案,emp:表)
常用的有:
| 英文 | 中文 | 英文 | 中文 |
| alter | 修改 | delete | 删除 |
| select | 查询 | insert | 添加 |
| update | 修改 | index | 索引 |
| references | 引用 | execute | 执行 |
显示对象权限
通过数据字段视图可以显示用户或是角色所具有的对象权限。视图为dba_tab_privs
SQL> connsystem/manager;
SQL> selectdistinct privilege from dba_tab_privs;
SQL> selectgrantor, owner, table_name, privilege from dba_tab_privs wheregrantee = 'BLAKE';
授予对象权限
在oracle9i前,授予对象权限是由对象的所有者来完成的,如果用其它的用户来操作,则需要用户具有相应的(withgrant option)权限,从oracle9i开始,dba用户(sys,system)可以将任何对象上的对象权限授予其它用户。授予对象权限是用grant命令来完成的。
对象权限可以授予用户,角色,和public。在授予权限时,如果带有with grant option选项,则可以将该权限转授给其它用户。但是要注意with grant option选项不能被授予角色。
1.monkey用户要操作scott.emp表,则必须授予相应的对象权限
1). 希望monkey可以查询scott.emp表的数据,怎样操作?
grant select on emp to monkey;
2). 希望monkey可以修改scott.emp的表数据,怎样操作?
grantupdate on emp to monkey;
3). 希望monkey可以删除scott.emp的表数据,怎样操作?
grantdelete on emp to monkey;
4). 有没有更加简单的方法,一次把所有权限赋给monkey?
grant all on emp to monkey;
2.能否对monkey访问权限更加精细控制。(授予列权限)
1). 希望monkey只可以修改scott.emp的表的sal字段,怎样操作?
grantupdate on emp(sal) to monkey
2).希望monkey只可以查询scott.emp的表的ename,sal数据,怎样操作?
grantselect on emp(ename,sal) to monkey
...
3.授予alter权限
如果black用户要修改scott.emp表的结构,则必须授予alter对象权限
SQL> connscott/tiger
SQL> grantalter on emp to blake;
当然也可以用system,sys来完成这件事。
4.授予execute权限
如果用户想要执行其它方案的包/过程/函数,则须有execute权限。
比如为了让ken可以执行包dbms_transaction,可以授予execute权限。
SQL> connsystem/manager
SQL> grant execute on dbms_transaction to ken;
5.授予index权限
如果想在别的方案的表上建立索引,则必须具有index对象权限。
如果为了让black可以在scott.emp表上建立索引,就给其index的对象权限
SQL> connscott/tiger
SQL> grant index on scott.emp to blake;
6.使用with grant option选项
该选项用于转授对象权限。但是该选项只能被授予用户,而不能授予角色
SQL> connscott/tiger;
SQL> grantselect on emp to blake with grant option;
SQL> connblack/shunping
SQL> grantselect on scott.emp to jones;
回收对象权限
在oracle9i中收回对象的权限可以由对象的所有者来完成,也可以用dba用户(sys,system)来完成。
这里要说明的是:收回对象权限后,用户就不能执行相应的sql命令,但是要注意的是对象的权限是否会被级联收回?【级联回收】
如:scott------------->blake-------------->jones
select on emp select onemp select on emp
SQL> connscott/tiger@accp
SQL> revokeselect on emp from blake
请大家思考,jones能否查询scott.emp表数据。
答案:查不了了(和系统权限不一样,刚好相反)
最后总结:
系统权限 with admin option 回收时不级联回收
对象权限 with grantoption 回收时级联回收
角色的管理:
一组权限的集合,目的是为了简化对权限的管理。
请看一个问题:假设有用户123,为了让他们拥有权限:
连接数据库,在scott.emp表上select,insert,update,如果采用直接授权,则需要12次授权。
解决办法:角色 解决具体方法见后面
角色的分类:
①预定义角色(33种)
常用的有(connect,dba,resource)
?查询某个角色具有哪些权限?//查询时名字一定要大写
SQL>select* from dba_sys_privs where grantee='DBA';//查询时名字一定要大写
SQL>select* from dba_sys_privs where grantee='CONNECT';
SQL>select * from dba_sys_privs where grantee='RESOURCE';
system和sys是用户,但是可以如是查询:
?如何知道某个用户具有什么角色?
SQL>select * from dba_sys_privs where grantee='SYSTEM';
SQL>select * from dba_sys_privs where grantee='SYS';
SQL>select * from dba_sys_privs where grantee='XIAOQIANG';
具有应用开发人员需要的大部分权限,只要给用于授予connect和resource权限即可。
需要注意的是:resource角色隐含了unlimited tablespace(表空间无限制),查询不出来。
案例:
创建一个用户,然后赋给connect角色:
create user aaa identified bym123;
grant connect to aaa;
DBA角色:具有所有的系统权限,with admin option选项,默认dba用户为sys和system他们可以将任何系统权限授予给其他用户,但是注意DBA不具备启动和关闭数据库。
案例:
创建一个用户,然后赋给DBA角色:
create user jack identified bym123;
grant dba to jack;
②自定义角色
oracle设计者,认为33种预定义角色可能不能满足所有需求,所以可以使用自定义角色。
建立角色(不验证):如果角色是公用的角色,可以采用不验证的方式建立角色(常用):
create role 角色名 not identified;
create role 角色名 identified by 密码;
案例:
请看一个问题:假设有用户123,为了让他们拥有权限:
连接数据库,在scott.emp表上select,insert,update,如果采用直接授权,则需要12次授权。
解决办法:
create role myrole not identified;
grant create session to myrole;
grant select on scott.emp to myrole;
grant insert on scott.emp to myrole;
grant update on scott.emp to myrole;
grant myrole to 123;
分配角色:
grant 角色名 to 用户名 [with admin option];
一般分配角色是由DBA(即sys/system)来完成的,若要求其他用户身份分配角色,则要求用户必须具有grant any role系统权限。
with admin option 授予权限的用户或是角色还可以将该系统权限授予其它的用户
删除角色:
drop role 角色名;(DBA来执行,其他用户要求具有drop any role系统权限)
21.PL/SQL
以下在scott/tiger账号下演示:
pl/sql(procedural language/sql):oracle在标准的sql语言上的扩展,允许使用条件和循环语句。
缺点:移植性不好,无法夸平台
优点:提供应用程序运行性能,模块化设计思想[分页过程,订单过程,转账过程],减少网络带宽,提供安全性
(1)存储过程简单版本
eg:开发一个简单的存储过程,可以完成向某表中添加一条记录:
创建存储过程基本语法:
create procedure 过程名(参数1…)
is
begin
执行语句;
end;
create procedure proc1
is
begin
insertinto emp(empno,ename) values(444,'4444');
end;
调用存储过程基本语法:
1.sqlplus控制台
execute/call 过程名(参数1…);
2.java程序调用 src里面
使用collableStatement接口
返回可能是一个值也可能是一个集合
create procedure proc2(in_empnonumber)
is
begin
deletefrom emp where empno=in_empno;
end;
块(编程):过程(存储过程)、函数、包(包体)、触发器。块是他们的基本编程单元。
|
编写规范
注释:单行注释--
多行注释/*……*/
表示符号的命名规范:块(block)的开发
PL/SQL块由3个部分构成:定义部分、执行部分、例外处理部分declare
/*定义部分--定义常量、变量、游标、复杂数据类型*/
begin
/*执行部分--要执行的pl/sql语句和sql语句*/
exception
/*例外处理部分--处理运行的各种错误*/
end;
相关说明:dbms_output是oracle所提供的包(类似java),该包包含一些过程,put_line就是dbms_output包的一个过程。
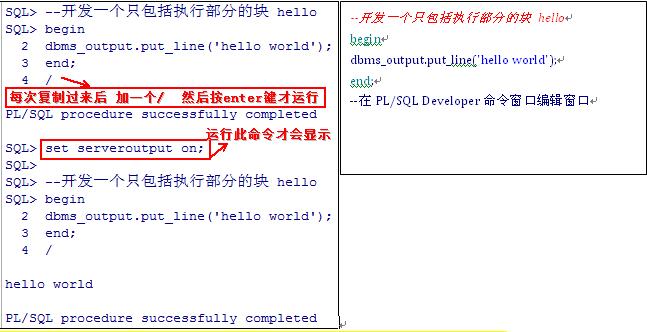
特别说明:在默认情况下,“hello world”不输出,需要setserveroutput on;
- declare
- --定义变量的格式是:变量名称 变量的类型
- --和建表一样
- v_ename varchar2(10);
- begin
- --把指定雇员编号查询得到的姓名值放入v_ename变量中
- select ename into v_ename from emp where empno=&empno;
- dbms_output.put_line('雇员名字是'||v_ename);
- end;
将上面的块改为过程:
- create procedure pro4(in_empno number)
- is
- --declare 这个就不要了 块才需要declare指定
- --定义变量的格式是:变量名称 变量的类型
- --和建表一样
- v_ename varchar2(10);
- begin
- --把指定雇员编号查询得到的姓名值放入v_ename变量中
- select ename into v_ename from emp where empno=in_empno;
- dbms_output.put_line('雇员名字是'||v_ename);
- end;
【特别注意】:
&:表示要接受从控制台输入的变量
||:表示两个字符串拼接
- declare
- v_ename varchar2(10);
- begin
- select ename into v_ename from emp where empno=110;
- dbms_output.put_line('雇员名字是'||v_ename);
- end;
oracle只提示“未找到数据”,不准确,为此,我们加入exception异常处理机制:
- declare
- v_ename varchar2(10);
- begin
- select ename into v_ename from emp where empno=110;
- dbms_output.put_line('雇员名字是'||v_ename);
- exception
- when no_data_found then
- dbms_output.put_line('朋友,你输入的编号有误!');
- end;
对该案例的细节异常说明:

案例:请考虑编写一个过程,可以输入雇员名,新工资,可修改雇员的工资
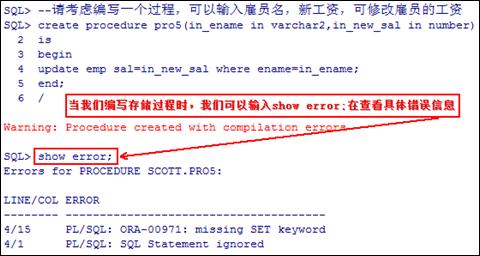
- --请考虑编写一个过程,可以输入雇员名,新工资,可修改雇员的工资
- create or replace procedure pro5(in_ename in varchar2,in_new_sal in number)
- is
- begin
- update emp set sal=in_new_sal where ename=in_ename;
- end;
(3)函数
eg:开发一个简单的存储过程,可以完成向某表中添加一条记录:- 创建函数基本语法:
- create function 函数名(参数1…)
- return 数据类型
- is
- 定义变量;
- begin
- 执行语句;
- end;
- 案例:编写一个函数,可以接受用户名并返回该用户的年薪
- create or replace function fun1(in_v_ename varchar2)
- return number--这里不要分号
- is
- --定义一个变量来接受年薪
- v_annual_sal number;
- begin
- select sal+nvl(comm,0)*13 into v_annual_sal from emp
- where ename=in_v_ename;
- return v_annual_sal;
- end;
- sqlplus调用:select fun1('KING') from dual;
(4)包
使用包可以更好的管理 自己写的函数、过程
①包的规范只包含了过程和函数的说明,没有具体实现代码。
- 创建包基本语法:
- createor replace package 包名
- is
- --声明过程
- function 过程名(参数1…) return 返回类型;
- --声明过程
- procedure 函数名(参数1…) return 返回类型;
- end;
- create or replace package mypackage1
- is
- --声明一个过程
- procedure pro5(v_in_ename varchar2,v_in_newsal number);
- --声明一个函数
- function fun1(v_in_ename varchar2) return number;
- end;
②包体用于实现包规范中的过程和函数。之前首先得建立包规范
- 创建包体基本语法:
- create or replace package body 包名
- is
- --实现过程
- function 过程名(参数1…) return 返回类型
- is
- --定义变量
- begin
- --执行语句
- end;
- --实现函数
- procedure 函数名(参数1…) return 返回类型
- is
- --定义变量
- begin
- --执行语句
- end;
- end;
- create or replace package body mypackage1
- is
- --实现一个过程
- procedure pro5(v_in_ename varchar2,v_in_newsal number)
- is
- v_empno varchar2(32);
- begin
- select empno into v_empno from emp where ename=v_in_ename;
- update emp set sal=v_in_newsal where ename=v_in_ename;
- exception
- when no_data_found then
- dbms_output.put_line('朋友,你输入的编号有误!');
- end;
-
- --实现一个函数
- function fun1(v_in_ename varchar2) return number
- is
- --定义一个变量来接受年薪
- v_annual_sal number;
- begin
- select sal+nvl(comm,0)*13 into v_annual_sal from emp
- where ename=v_in_ename;
- return v_annual_sal;
- end;
-
- end;
在PL/SQLDeveloper下,用账号scott/tiger登录后
New—>Command Window—>然后在Edit窗口复制
上面命令,按F8运行,然后按/和Enter,后,出现
编译错误,请运行show error
运行:
execmypackage1.pro5('KING',12);
selectscott.mypackage1.fun1('KING') from dual;
最后总结:先声明包规范,再进行创建包体。
(5)触发器
触发器就是隐含的执行的存储过程,类似监听事件。定义触发器时要指定触发的事件和操作。
不是由程序员/DBA来显示调用,而是因为某个操作引发执行的。
常用触发器事件:insert/update/delete,实际就是一个PL/SQL块。
【提出问题】
①当用户登录时,自动记录该用户名字,登录时间,ip…
②当用户在星期天对某张表进行delete时,我们提示不能这样操作
③当用户删除某条记录的时候,自动将该记录保存到另外一张表去
【解决办法】触发器
触发器的分类
DM(数据操作语言,关于表中数据操作)L触发器:
DDL(数据定义语言,关于表的操作)触发器:
系统触发器(与胸相关的触发器,比如用户登录退出,关闭启动数据库)

procedure raise_application_error(error_number_inin number,error_msg_invarchar2);
error_number_in[自定义] 从-20000到-20999之间,这样就不会与oracle的任何错误代码发生冲突。
error_msg_in[自定义]不能超过2K,否则截取2K。
- --②当用户在星期天对某张表进行delete时,我们提示不能这样操作
- create or replace trigger tri1
- before delete on scott.emp
- begin
- if to_char(sysdate,'day') in ('星期五','星期六') then
- dbms_output.put_line('对不起,休息日不能删除员工');
- raise_application_error(-20001,'对不起,休息日不能删除员工');
- end if;
- end;
使用条件谓词case…when和insert等词:
- --②当用户在星期天对某张表进行delete时,我们提示不能这样操作
- create or replace trigger tri1
- before insert or update or delete on scott.emp
- begin--更加精准的告诉你正在做什么
- case
- when inserting then
- dbms_output.put_line('请不要添加');
- raise_application_error(-20001,'请不要添加');
- when updating then
- dbms_output.put_line('请不要修改');
- raise_application_error(-20002,'请不要修改');
- when deleting then
- dbms_output.put_line('请不要删除');
- raise_application_error(-20003,'请不要删除');
- end case;
- end
使用:old和:new
【提出问题】当触发器被触发时,要使用被插入、更新或删除的记录中的列值,有时要使用操作前、后列值
:old:修饰符访问操作完成后列的值
:new:修饰符访问操作完成前列的值
| 特性 | insert | update | delete |
| old | null | 有效 | 有效 |
| new | 有效 | 有效 | null |
案例:
①在修改emp表雇员薪水时,显示雇员工资修改前和修改后的值
②如何确保修改员工工工资不能低于原有工资
- create or replace trigger tri4
- before update on scott.emp
- for each row--这个一定要 是行级 不是表级
- begin
- if :new.sal<:old.sal then
- dbms_output.put_line('工资不能低于原来工资');
- raise_application_error(-2005,'工资不能低于原来工资');
- else
- dbms_output.put_line('原来工资是'||:old.sal||'现在工资'||:new.sal);
- end if;
- end;
案例:
编写一个触发器,保证当用户删除一张表(emp)记录的时候,自动把删除的记录备份到另外一张表(emp_bak)
- --1.实现建立一张备份表
- create table SCOTT.emp_bak
- ( "EMPNO" NUMBER(4,0),
- "ENAME" VARCHAR2(10),
- "JOB" VARCHAR2(9),
- "MGR" NUMBER(4,0),
- "HIREDATE" DATE,
- "SAL" NUMBER(7,2),
- "COMM" NUMBER(7,2),
- "DEPTNO" NUMBER(2,0)
- );
- --2.建立触发器
- create or replace trigger tri5
- before delete on scott.emp
- for each row--这个一定要 是行级 不是表级
- begin
- --执行语句
- insert into emp_bak values(:old.empno,
- :old.ename,:old.job,:old.mgr,
- :old.hiredate,:old.sal,:old.comm,:old.deptno);
- end;
这里我们设计的时候,可以保存一个还原点:
savepoint a; --创建保存点
DELETE FROMstudent;
rollback to a; --恢复到保存点
一个有经验的DBA,在确保完成无误的情况下要定期创建还原点。
DROP TABLE student; --删除表的结构和数据;
delete fromstudent WHERExh = 'A001'; --删除一条记录;
truncate TABLE student; --删除表中的所有记录,表结构还在,不写日志,无法找回删除的记录,速度快。
见p
案例:
编写一个触发器,如何控制员工薪水不能低于原来工资,同时也不能高出原来工资的20%,使用约束显然无法实现该规则。
- create or replace trigger tri6
- before update on scott.emp
- for each row--这个一定要 是行级 不是表级
- begin
- --执行语句
- if :new.sal<:old.sal || :new.sal>:old.sal*1.2 then
- dbms_output.put_line('工资范围不对!');
- --阻止执行
- raise_application_error(-20010,'工资范围不对');
- end if;
- end;
系统触发器
(由DBA创建系统触发器) 一般由系统管理员来完成
系统时间指基于Oracle事件(startup,startdown等)所建立的触发器,通过使用系统事件触发器,提供了跟踪系统或数据库变化的机制。下面这个5个属性可以直接返回值,直接使用
ora_client_ip_address//返回客户端的ip
ora_database_name//返回数据库名
ora_login_user//返回登录用户名
ora_sysevent//返回触发器的系统事件名
ora_des_encrypted_password//返回用户des(md5)加密后的密码
- 基本语法:
- create [or replace] trigger触发器名
- {before | after}
- {logon|logoff}
- on database
- begin
- --触发器内容
- end;
案例:
记录用户的登录和退出事件,我们可以建立登录和退出触发器,为了记录用户名称,事件,ip地址,我们首先建立一张信息表。
- --完成登录(logon)和退出(logoff)的系统触发器
- --1.创建一张表,来保存用户登录信息
- create table log_table(
- username varchar2(20),
- logon_time date,
- logoff_time date,
- address varchar2(20));
- --2.创建触发器
- --登录触发器
- create or replace trigger tri8
- after logon on database--登录后就记录
- begin
- insert into log_table(username,logon_time,address)
- values(ora_login_user,sysdate,ora_client_ip_address);
- end;
- --退出触发器
- create or replace trigger tri9
- before logoff on database--退出前就记录
- begin
- insert into log_table(username,logoff_time,address)
- values(ora_login_user,sysdate,ora_client_ip_address);
- end;
DDL触发器
(对表定义删除的相关信息记录 需要DBA创建) 一般由系统管理员来完成
- 基本语法:
- create [or replace] trigger触发器名
- {before | after} ddl
- on 方案名.schema
- begin
- --触发器内容
- end;
【最后强调】
在oracle中,DML语句需要手动提交
DDL语句(创建触发器、表、过程)自动提交
当oracle退出时,会自动提交DML语句
案例:
- --编写一个触发器,编写某一个用户进行的ddl操作
- --1.创建一张表,来保存用户登录信息
- create table ddl_record(
- event varchar2(64),
- username varchar2(64),
- ddl_time);
- --2.创建触发器
- create or replace trigger tri9
- after ddl on scott.schema
- begin
- insert into ddl_record values(ora_sysevent,ora_login_user,sysdate);
- end;
管理触发器
禁止触发器:让触发器临时失效
alter trigger 触发器名 disable;
激活触发器:
alter trigger 触发器名 enable;
禁止或激活触发表的所有触发器:
alter table emp disable alltrigger;
alter table emp enable alltrigger;
删除触发器:
drop trigger 触发器名;
PL/SQL语法数据类型
①标量类型(scalar)
名称 [constant] 数据类型 [not null] [:=初始值]
constant:指定常量,需要指定它的初始值,且其值是不能改变的
e.g:
定义一个变长字符串 v_enamevarchar2(10)
定义一个小数 范围-9999.99-9999.99 v_sal number(6,2);
定义一个小数并给一个初始值5.4 v_salnumber(6,2):=5.4 := 是pl/sql的赋值号
定义一个日期类型的数据 v_hiredate date;
定义一个布尔变量,不能为空初始值为false v_valid Boolean:=false
案例:以输入员工号,显示雇员姓名、工资、个人所得税(税率为0.03)
- create or replace procedure pro2(v_in_empno in number) is
- --定义变量
- v_tax_rate number(3,2):=0.03;
- v_sal number;
- v_ename varchar2(32);
- v_tax number;
- begin
- select ename,sal into v_ename,v_sal from emp
- where empno=v_in_empno;
- --计算个人所得税
- v_tax:=v_sal*v_tax_rate;
- dbms_output.put_line(v_ename||'工资='||v_sal||'个人所得税:'||v_tax);
- end;
- sqlplus调用:exec pro2(7839);
为了让v_ename类型更加灵活,我们使用%type v_ename emp.ename%type;
让我们在PL/SQL编程中,让变量类型和大小与表的列的大小和类型一致。
②复合类型(composite)
- PL/SQL记录
- 类似与高级语言中的结构体,但当引用pl/sql记录成员时,必须要加记录变量作为前缀。
- 基本语法:
- type 自定义的pl/sql记录名 is record(
- 变量名 变量类型,
- 变量名 变量类型
- )
- //使用自定义的pl/sql记录名
- 变量名 自定义的pl/sql记录名;
案例:请编写一个过程,该过程可以接受一个用户编号,并显示该用户名字,薪水,工作岗位
- create or replace procedure pro3(v_in_empno in number)is
- --定义一个记录数据类型
- type emp_record is record(
- v_ename emp.ename%type,
- v_sal emp.sal%type,
- v_job emp.job%type
- );
- --定义一个变量,其类型是emp_record
- v_emp_record emp_record;
- begin
- select ename,sal,job into v_emp_record from emp
- where empno=v_in_empno;
- dbms_output.put_line('名字'||v_emp_record.v_ename||'薪水'||v_emp_record.v_sal||'岗位'||v_emp_record.v_job);
- end;
- sqlplus调用:exec pro3(7902);
PL/SQL表
相当于java中的数组
基本语法:
type 自定义的pl/sql数据类型istableof emp.sal%type index by binary_integer;
定义一个这样变量
//使用自定义的pl/sql记录名
变量名 自定义的pl/sql记录名;
- declare
- type hao_table_type is table of emp.ename%type index by binary_integer;
- --定义一个变量:sp_table:类型
- hao_table hao_table_type;
- begin
- select ename into hao_table(-1) from emp where empno=7788;
- dbms_output.put_line('员工'||hao_table(-1));
- end;
- --说明 hao_table_type 是pl/sql类型
- -------emp.ename%type 指定了表的类型和长度
- -------sp_table为pl/sql表变量
- -------hao_table(0)则表示下标为0的元素 pl/sql下标都可以为负数
③参照类型(游标)(reference)
游标变量:通过游标,我们可以取得返回结果集(往往是select结果)的任何一行数据,从而提供共享的效率

- --②在①基础上,若某个员工的工资低于200元,就增加100元
- create or replace procedure pro1(v_in_deptno number) is
- --先定义一个游标变量类型 一个变量类型可以定义多个变量
- type emp_cursor is ref cursor;
- --定义1个游标变量
- v_emp_cursor emp_cursor;
- --定义2个变量
- v_ename emp.ename%type;
- v_sal emp.sal%type;
- v_empno emp.empno%type;
- begin--两个空格
- --执行语句
- --打开游标
- open v_emp_cursor for select ename,sal,empno from emp
- where deptno=v_in_deptno;
- --取出游标指向的每行数据,用循环语句
- loop
- fetch v_emp_cursor into v_ename,v_sal,v_empno;--这句 导致游标往下移
- --判断当前游标是否达到最后
- exit when v_emp_cursor%notfound;
- --输出 输出在判断之后,先判断,否则重复输出(最后一行)
- dbms_output.put_line('用户名'||v_ename||' 薪水'||v_sal);
- ----------------------------更改地方-----------------------------
- if v_sal<200 then
- update emp set sal=sal+100 where empno=v_empno;
- end if;
- end loop;
- --关闭游标[完后一定要关闭游标]
- close v_emp_cursor;
- end;
(6)PL/SQL进阶控制结构
①条件分支语句
pl/sql中提供了三种条件分支语句:if——then if——then——else if——then——elsif——else
案例:编写一个过程,输入一个雇员,如果该雇员的补助不是0就在原来基础上增加100,如果补助为0就把补助设为200,空的话就设为150.
- create or replace procedure pro6(v_in_ename varchar2) is
- v_comm emp.comm%type;
- begin
- --查询补助
- select comm into v_comm from emp where ename=v_in_ename;
- --if v_comm is null
- if v_comm<>0 then--这里把comm空值也加进去了
- update emp set comm=comm+100 where ename=v_in_ename;
- else
- update emp set comm=200 where ename=v_in_ename;
- end if;
- end;
②循环语句loop|while|for
见PL/SQL语法数据类型--参照类型案例,可以进行循环插入记录利用存储过程
基本语法:
loop
--执行语句;
exit when 条件表达式;
--执行语句;
end loop;
基本语法:
while 条件表达式loop
--执行语句;
end loop;
基本语法:
begin
for iin reverse 1..10 loop
insert into users values(i,);
end loop;
end;--我们看到控制变量i隐形增加
【最终完结】
1)在is……begin间不能对变量赋值,如果要重新赋值,则需要在begin……end间。
2)PL/SQL中,不能对输入参数的值,重新赋值。
②goto|null
goto语句用于跳转到特定标号去执行语句,最好不要用。
null语句不会执行任何操作,只是提高代码可读性。
- declare
- i number:=1;
- begin
- <<start_loop>>
- loop
- dbms_output.put_line('输出i='||i);
- if i=12 then
- goto end_loop;
- end if;
- i:=i+1;
- if i=10 then
- goto start_loop;
- end if;
- end loop;
- <<end_loop>>
- dbms_output.put_line('循环结束');
- end;
- declare
- v_sal emp.sal%type;
- v_ename emp.ename%type;
- begin
- select ename,sal into v_ename,v_sal
- from emp
- where empno=&no;
- if v_sal<3000 then
- update emp set comm=sal*0.1
- where ename=v_ename;
- else null;
- end if;
- end;
(7)PL/SQL进阶分页过程
【注意事项】
oracle存储过程没有返回值,它的所有返回值都是通过out参数来替代的
若返回是结果集,就不必须用package关于存储过程java调用的程序 详细请见src/oracle_itcast
(8)PL/SQL进阶例外
- 基本语法:
- begin
- --执行语句
- exception
- when 例外名称 then
- --执行语句
- when 例外名称 then
- --执行语句;
- when others then
- --其他
- end;
- --编写一个过程,输入雇员编号,显示雇员姓名,若编号不存在就会有异常
- create or replace procedure pro10(v_in_empno in number) is
- v_ename emp.ename%type;
- begin
- select ename into v_ename from emp where empno=v_in_empno;
- dbms_output.put_line('名字是'||v_ename);
- Exception
- when no_data_found then
- dbms_output.put_line('朋友!你输入的编号不存在');
- when others then
- dbms_output.put_line('不明错误');
- end;
- 记得:set serveroutput on;
常见的几种例外:
| 例外情况名称 | 错误代码 | 描述 |
| no_data_found | ora-01403 | 对于select叙述没有传回任何值 |
| too_many_rows | ora_01427 | 只允许传回一笔记录的select叙述结果却多余一笔 |
| invalid_cursor | ora-01001 | 使用非法的光标操作 |
| value_error | ora-06502 | 出现数值、数据形态转换、截取字符串或强制性的错误 |
| invalid_number | ora-01722 | 字符串到数值的转换失败 |
| zero_divide | ora-01476 | 被零除 |
| dup_val_on_index | ora-00001 | 视图向具有唯一键值的索引中插入一个重复键值 |
| case_not_found | ora-06592 | 没有case条件匹配 |
| cursor_not_open | ora-06511 | 游标没有打开 |
(9)视图
oracle的又一种数据对象,虚拟表,视图的主要用处是简化操作,提高安全,满足不同用户查询需求,视图不是一个真正存在的物理表。它是根据别的表动态生成的。
基本语法:
创建视图:
createview 视图名 as select 语句[withread only];
创建或修改视图:
create or replace view 视图名 asselect 语句[with read only];
删除视图:
drop view视图名;
需要DBA给scott授予创建视图权限:grantcreate view to scott;
视图与表的区别:
1.表需占磁盘空间视图不需
2.视图不能添加索引
3.使用视图可简化复杂查询
4.视图有利于提供安全性
with read only可以进行只读
22.数据库管理+表的逻辑备份与恢复
数据库管理员
每个oracle数据库应该至少有一个数据库管理员(dba),对于一个小的数据库,一个dba就够了,但是对于一个大的数据库可能需要多个dba分担不同的管理职责。那么一个数据库管理员的主要工作是什么呢:
职责
1.安装和升级oracle数据库
2.建库,表空间,表,视图,索引…
3.制定并实施备份和恢复计划
4.数据库权限管理,调优,故障排除
5.对于高级dba,要求能参与项目开发,会编写sql语句、存储过程、触发器、规则、约束、包
管理数据库的用户主要是sys和system
(sys好像是董事长,system好像是总经理,董事长比总经理大,但是通常是总经理干事)
在前面我们已经提到这两个用户,区别主要是:
1.最重要的区别,存储的数据的重要性不同
sys:所有oracle的数据字典的基表和视图都存放在sys用户中,这些基表和视图对于oracle的运行是至关重要的,由数据库自己维护,任何用户都不能手动更改。sys用户拥有dba,sysdba,sysoper角色或权限,是oracle权限最高的用户。
system:用于存放次一级的内部数据,如oracle的一些特性或工具的管理信息。system用户拥有dba,sysdba角色或系统权限。
sysdba角色可以建数据库,sysoper不能建数据库
2. 其次的区别,权限的不同。
sys用户必须以as sysdba或as sysoper形式登录。不能以normal方式登录数据库
system如果正常登录,它其实就是一个普通的dba用户,但是如果以as sysdba登录,其结果实际上它是作为sys用户登录的,从登录信息里面我们可以看出来。
sysdba和sysoper权限区别图,看图:

sysdba>sysoper>dba
可以看到:只要是sysoper拥有的权限,sysdba都有;蓝色是它们区别的地方。(它们的最大区别是:sysdba可以创建数据库,sysoper不可以创建数据库)
dba权限的用户
dba用户是指具有dba角色的数据库用户。特权用户可以执行启动实例,关闭实例等特殊操作,而dba用户只有在启动数据库后才能执行各种管理工作。(相当于说dba连startup和shutdown这两个权限都没有)
两个主要的用户,三个重要权限,他们的区别和联系,大家要弄清楚
管理初始化参数
管理初始化参数(调优的一个重要知识点,凭什么可以对数据库进行调优呢?是因为它可以对数据库的一些参数进行修改修正)
初始化参数用于设置实例或是数据库的特征。oracle9i提供了200多个初始化参数,并且每个初始化参数都有默认值。
显示初始化参数
(1) show parameter命令
如何修改参数
需要说明的如果你希望修改这些初始化的参数,可以到文件D:\oracle\admin\myoral\pfile\init.ora文件中去修改比如要修改实例的名字
数据库(表)的逻辑备份与恢复
介绍
逻辑备份是指使用工具export将数据对象的结构和数据导出到文件的过程,逻辑恢复是指当数据库对象被误操作而损坏后使用工具import利用备份的文件把数据对象导入到数据库的过程。
物理备份即可在数据库open的状态下进行也可在关闭数据库后进行,但是逻辑备份和恢复只能在open的状态下进行。
导出
导出具体的分为:导出表,导出方案,导出数据库三种方式。
导出使用exp命令来完成的,该命令常用的选项有:
userid: 用于指定执行导出操作的用户名,口令,连接字符串
tables: 用于指定执行导出操作的表
owner: 用于指定执行导出操作的方案
full=y: 用于指定执行导出操作的数据库
inctype: 用于指定执行导出操作的增量类型
rows: 用于指定执行导出操作是否要导出表中的数据
file: 用于指定导出文件名
导出表
1.导出自己的表
expuserid=scott/tiger@myoral tables=(emp,dept) file=d:\e1.dmp
2.导出其它方案的表
如果用户要导出其它方案的表,则需要dba的权限或是exp_full_database的权限,比如system就可以导出scott的表
E:\oracle\ora92\bin>expuserid=system/manager@myoral tables=(scott.emp) file=d:\e2.emp
特别说明:在导入和导出的时候,要到oracle目录的bin目录下。
3. 导出表的结构
exp userid=scott/tiger@accptables=(emp) file=d:\e3.dmp rows=n
4. 使用直接导出方式
exp userid=scott/tiger@accptables=(emp) file=d:\e4.dmp direct=y
这种方式比默认的常规方式速度要快,当数据量大时,可以考虑使用这样的方法。
这时需要数据库的字符集要与客户端字符集完全一致,否则会报错...
导出方案
导出方案是指使用export工具导出一个方案或是多个方案中的所有对象(表,索引,约束...)和数据。并存放到文件中。
1. 导出自己的方案
exp userid=scott/tiger@myorclowner=scott file=d:\scott.dmp
2. 导出其它方案
如果用户要导出其它方案,则需要dba的权限或是exp_full_database的权限,比如system用户就可以导出任何方案
expuserid=system/manager@myorcl owner=(system,scott) file=d:\system.dmp
导出数据库
导出数据库是指利用export导出所有数据库中的对象及数据,要求该用户具有dba的权限或者是exp_full_database权限
增量备份(好处是第一次备份后,第二次备份就快很多了)
expuserid=system/manager@myorcl full=y inctype=complete file=d:\all.dmp
导入
导入就是使用工具import将文件中的对象和数据导入到数据库中,但是导入要使用的文件必须是export所导出的文件。与导出相似,导入也分为导入表,导入方案,导入数据库三种方式。
imp常用的选项有
userid: 用于指定执行导入操作的用户名,口令,连接字符串
tables: 用于指定执行导入操作的表
formuser: 用于指定源用户
touser: 用于指定目标用户
file: 用于指定导入文件名
full=y: 用于指定执行导入整个文件
inctype: 用于指定执行导入操作的增量类型
rows: 指定是否要导入表行(数据)
ignore: 如果表存在,则只导入数据
导入表
1. 导入自己的表
impuserid=scott/tiger@myorcl tables=(emp) file=d:\xx.dmp
2. 导入表到其它用户
要求该用户具有dba的权限,或是imp_full_database
impuserid=system/tiger@myorcl tables=(emp) file=d:\xx.dmp touser=scott
3. 导入表的结构
只导入表的结构而不导入数据
impuserid=scott/tiger@myorcl tables=(emp) file=d:\xx.dmp rows=n
4. 导入数据
如果对象(如比表)已经存在可以只导入表的数据
impuserid=scott/tiger@myorcl tables=(emp) file=d:\xx.dmp ignore=y
导入方案
导入方案是指使用import工具将文件中的对象和数据导入到一个或是多个方案中。如果要导入其它方案,要求该用户具有dba的权限,或者imp_full_database
1. 导入自身的方案
impuserid=scott/tiger file=d:\xxx.dmp
2. 导入其它方案
要求该用户具有dba的权限
impuserid=system/manager file=d:\xxx.dmp fromuser=system touser=scott
导入数据库n
在默认情况下,当导入数据库时,会导入所有对象结构和数据,案例如下:
impuserid=system/manager full=y file=d:\xxx.dmp
23.数据字典和动态性能视图
数据字典是oracle数据库中最重要的组成部分,它提供了数据库的一些系统信息。
动态性能视图记载了例程启动后的相关信息。
数据字典
数据字典记录了数据库的系统信息,它是只读表和视图的集合,数据字典的所有者为sys用户。
用户只能在数据字典上执行查询操作(select语句),而其维护和修改是由系统自动完成的。
这里我们谈谈数据字典的组成:数据字典包括数据字典基表和数据字典视图,其中基表存储数据库的基本信息,普通用户不能直接访问数据字典的基表。数据字典视图是基于数据字典基表所建立的视图,普通用户可以通过查询数据字典视图取得系统信息。数据字典视图主要包括user_xxx,all_xxx,dba_xxx三种类型。
user_tables;
用于显示当前用户所拥有的所有表,它只返回用户所对应方案的所有表
比如:selecttable_name from user_tables;
all_tables;
用于显示当前用户可以访问的所有表,它不仅会返回当前用户方案的所有表,还会返回当前用户可以访问的其它方案的表:
比如:selecttable_name from all_tables;
dba_tables;
它会显示所有方案拥有的数据库表。但是查询这种数据库字典视图,要求用户必须是dba角色或是有select any table系统权限。
例如:当用system用户查询数据字典视图dba_tables时,会返回system,sys,scott...方案所对应的数据库表。
用户名,权限,角色
在建立用户时,oracle会把用户的信息存放到数据字典中,当给用户授予权限或是角色时,oracle会将权限和角色的信息存放到数据字典。
通过查询dba_users可以显示所有数据库用户的详细信息;
通过查询数据字典视图dba_sys_privs,可以显示用户所具有的系统权限;
通过查询数据字典视图dba_tab_privs,可以显示用户具有的对象权限;
通过查询数据字典dba_col_privs可以显示用户具有的列权限;
通过查询数据库字典视图dba_role_privs可以显示用户所具有的角色。
这里给大家再讲讲角色和权限的关系。
例如:要查看scott具有的角色,可查询dba_role_privs;
SQL> select *from dba_role_privs where grantee='SCOTT';
//查询orale中所有的系统权限,一般是dba
select * fromsystem_privilege_map order by name;
//查询oracle中所有对象权限,一般是dba
select distinctprivilege from dba_tab_privs;
//查询oracle中所有的角色,一般是dba
select * fromdba_roles;
//查询数据库的表空间
selecttablespace_name from dba_tablespaces;
问题1:如何查询一个角色包括的权限?
a.一个角色包含的系统权限
select * from dba_sys_privs where grantee='角色名'
另外也可以这样查看:
select * from role_sys_privs where role='角色名'
b.一个角色包含的对象权限
select * from dba_tab_privs where grantee='角色名'
问题2:oracle究竟有多少种角色?
SQL> select *from dba_roles;
问题3:如何查看某个用户,具有什么样的角色?
select * fromdba_role_privs where grantee='用户名'
显示当前用户可以访问的所有数据字典视图。n
select * from dictwhere comments like '%grant%';
显示当前数据库的全称n
select * fromglobal_name;
其它说明
数据字典记录有oracle数据库的所有系统信息。通过查询数据字典可以取得以下系统信息:比如
1.对象定义情况
2.对象占用空间大小
3.列信息
4.约束信息
...
但是因为这些个信息,可以通过pl/sqldeveloper工具查询得到,所以这里我就飘过。
动态性能视图
动态性能视图用于记录当前例程的活动信息,当启动oracle server时,系统会建立动态性能视图;当停止oracle server时,系统会删除动态性能视图。oracle的所有动态性能视图都是以v_$开始的,并且oracle为每个动态性能视图都提供了相应的同义词,并且其同义词是以V$开始的,例如v_$datafile的同义词为v$datafile;动态性能视图的所有者为sys,一般情况下,由dba或是特权用户来查询动态性能视图。
因为这个在实际中用的较少,所以飞过。
24.oracle的卸载
一般的应用程序,安装后,可以通过uninstall工具来卸载,但是oracle没有,oracle卸载步骤如下:
1.先停止oracle的所有服务
2.使用Oracle universal installer(OUI)来完成初步卸载(该工具不会把oracle注册表信息清除,所以会把我们后续安装oracle或升级oracle带来麻烦)
3.到注册表中删除oracle的注册信息(regedit命令),删除下面内容:
①HKEY_LOCAL_MACHINE—>Software—>Oracle 删除此键
②HKEY_LOCAL_MACHINE—>System—> CurrentControlSet—>Services删除Services键下所有以oracle为首的键
③HKEY_LOCAL_MACHINE—>System—> CurrentControlSet—>Services—>Eventlog—>Application删除此键下的所有以oracle为首的键
④HKEY_CLASSES_ROOT删除此键下的所有以Ora、Oracle、EnumOra为前缀的键
⑤HKEY_CURRENT_USER—>Software—>Microsoft—>Windows—>CurrentVersion—>Explorer—>MenuOrder—>StartMenu—>Programs删除此键下的所有以Oracle为首的键
⑥HKEY_LOCAL_MACHINE—>Software—>ODBC—>ODBCINST.INI注册键,删除Microsoft ODBC FORORACLE注册表键以外的所有有Oracle字样的键值。
⑦HKEY_LOCAL_MACHINE—>System—>CurrentControlSet—>Services删除以Oracle或OraWeb为前缀的键
4.删除环境变量CLASSPATH,PATH中含有Oracle字样的值
5.最后再文件系统内删除ORACLE相关的文件及目录,删除系统盘符:\Program Files\Oracle目录;删除ORCLE_BASE目录
我无法删除D:\oracle目录,重新启动机器之后才删除
在默认情况下,oracle卸载并不会删除你的数据库文件,所以你手动删除出现错误,如果删除出现错误,则重启后再删除
25.尚学堂SQL简单讲解
descemp 描述表信息
desc dept
desc salgrade
select ename,sal*12 as 年薪 from emp;
数据库中两个单引号来替代一个单引号
selectename || 'adfa''s' from emp;
||连接字符串
selectdistinct deptno,job from emp;
lower函数
chr(65) accii码转换成字符
ascii(A) 字符转换成accii码
round(23.54) 四舍五入
round(23.236,2)四舍五入到小数点后面2位
round(23.236,-1) 四舍五入到十位数
在oracle中先将scott账户解锁,然后使用scott账户可以看到emp表
Oracle常用函数
(1)trunc(for date)
这里注意 to_date date是日期值 所以转换后是不含有时间
TRUNC(for date)TRUNC函数为指定元素而截去的日期值。
其具体的语法格式如下: TRUNC(date[,fmt])
其中:date一个日期值,fmt日期格式,该日期将由指定的元素格式所截去。忽略它则由最近的日期截去
下面是该函数的使用情况:(mi minute 分钟的意思)
select trunc(to_date('2012-03-2323:59:59','yyyy-mm-dd hh24:mi:ss')) from dual
系统定义表,只有一笔记录.可以用来返回函数值.select user from dual;返回当前用户.dual为了完善语义,因为没有from oracle中是报错的
-- return date : 2012-3-23
trunc(sysdate,'yyyy') --返回当年第一天.
trunc(sysdate,'mm') --返回当月第一天.
trunc(sysdate,'d') --返回当前星期的第一天(如2012-07-11所在星期的第一天是2012-07-08)
(2)trunc(number)
TRUNC函数返回处理后的数值,其工作机制与ROUND函数极为类似,只是该函数不对指定小数前或后的部分做相应舍入选择处理,而统统截去。
其具体的语法格式如下TRUNC(number[,decimals])
其中:number待做截取处理的数值,decimals指明需保留小数点后面的位数。可选项,忽略它则截去所有的小数部分
下面是该函数的使用情况:
TRUNC(89.985,2)=89.98
TRUNC(89.985)=89
TRUNC(89.985,-1)=80
注意:第二个参数可以为负数,表示为小数点左边指定位数后面的部分截去,即均以0记。与取整类似,比如参数为1即取整到十分位,如果是-1,则是取整到十位,以此类推;如果所设置的参数为负数,且负数的位数大于整数的字节数的话,则返回为0。如:TRUNC(89.985,-3)=0.
(3)to_char
把日期或数字转换为字符串;to_date是把字符串转换为数据库中得日期类型
使用TO_CHAR函数处理数字:TO_CHAR(number, '格式');TO_CHAR(salary,’$99,999.99’);
使用TO_CHAR函数处理日期: TO_CHAR(date,’格式’);
(4)to_date
使用TO_DATE函数将字符转换为日期:TO_DATE(char[, '格式'])
e.g selectto_date('2011-11-5 4:39:57','yyyy-mm-dd hh24:mi ss') as col from dual
(5)to_number
使用TO_NUMBER函数将字符转换为数字:TO_NUMBER(char[, '格式'])
各种格式:
| 数字格式格式 | 日期格式 |
| 9代表一个数字 0强制显示0 $放置一个$符 L放置一个浮动 本地货币符 .显示小数点 ,显示千位指示符
| 格式控制描述 YYYY、YYY、YY分别代表4位、3位、2位的数字年,YEAR年的拼写 MM数字月,MONTH月的全拼,MON月的缩写 DD数字日,DAY星期的全拼,DY星期的缩写,AM表示上午或者下午 HH24、HH12 12小时制或24小时制,MI分钟,SS秒钟 SP数字的拼写,TH数字的序数词 “特殊字符”假如特殊字符 HH24:MI:SS AM 15:43:20 PM DD “OF” MONTH 12 OF OCTOBER DDSPTH fourteenth Date的格式 ’18-5月-84’ |
(6)instr
INSTR方法的格式为:INSTR(源字符串,目标字符串,起始位置,匹配序号)
查询是否匹配目标字符串
例如:INSTR('CORPORATE FLOOR','OR', 3, 2)中,源字符串为'CORPORATE FLOOR',目标字符串为'OR',起始位置为3,取第2个匹配项的位置。
默认查找顺序为从左到右。当起始位置为负数的时候,从右边开始查找。
所以SELECT INSTR('CORPORATE FLOOR', 'OR', -1, 1) "Instring" FROM DUAL的显示结果是:14
别名Instring
(7)substr
取得字符串中指定起始位置和长度的字符串substr( string, start_position, [ length ] )
如:
substr('This is a test', 6,2) return 'is'
substr('This is a test',6) return 'is a test'
substr('TechOnTheNet', -3,3) return 'Net'
substr('TechOnTheNet', -6,3) return 'The'select substr('Thisisatest', -4, 2) valuefrom dual
举个例子更容易区分这两个函数:
(8)trim
Oracle中的trim函数是用来删除给定字符串或者给定数字中的头部或者尾部的给定字符。
trim函数具有如下的形式trim([leading/trailing/both][匹配字符串或数值][from][需要被处理的字符串或数值])这里如果
① 指明了leading表示从删除头部匹配的字符串
② 如果指明了trailing表示从删除尾部匹配的字符串
③ 如果指明了both,或者不指明任何位置,则两端都将被删除
④如果不指明任何匹配字符串或数值则认为是空格,即删除前面或者后面的空格。
trim函数返回的类型是varchar2下面是一些例子:
| 各种情况 | 例子 | 结果 |
| 指明leading表示从删除头部匹配的字符串 | select trim(leading '1' from '12321Tech11') from dual; | 2321Tech11 |
| 指明trailing表示从删除尾部匹配的字符串 | select trim(trailing '1' from '12321Tech11') from dual; | 12321Tech |
| 如果指明了both,或者不指明任何位置,则两端都将被删除 | select trim(‘中’from‘中秋八月中‘) as诗from dual; select trim(both '1' from '12321Tech 111') from dual;
| 秋八月 2321Tech |
| 如果不指明任何匹配字符串或数值则认为是空格,即删除前面或者后面的空格 | select trim(' tech ') as诗from dual; select trim(' ' from ' tech ') as诗from dual; select trim(0 from 7500) from dual; | tech tech 75 |
LTRIM, RTRIM 不但可以去掉空格,还可以去掉指定字符, 如LTRIM(',aaaa',',')
ltrim rtrim
(9)translate
语法:TRANSLATE(char, from, to)
用法:返回将出现在from中的每个字符替换为to中的相应字符以后的字符串。
若from比to字符串长,那么在from中比to中多出的字符将会被删除。
三个参数中有一个是空,返回值也将是空值。
举例:SQL> select translate('abcdefga','abc','wo')返回值from dual;
返回值------- wodefgw
分析:该语句要将'abcdefga'中的'abc'转换为'wo',
由于'abc'中'a'对应'wo'中的'w',故将'abcdefga'中的'a'全部转换成'w';
而'abc'中'b'对应'wo'中的'o',故将'abcdefga'中的'b'全部转换成'o';
而'abc'中的'c'在'wo'中没有与之对应的字符,故将'abcdefga'中的'c'全部删除;
简单说来,就是将from中的字符转换为to中与之位置对应的字符,若to中找不到与之对应的字符,返回值中的该字符将会被删除。
在实际的业务中,可以用来删除一些异常数据,比如表a中的一个字段t_no表示电话号码,而电话号码本身应该是一个由数字组成的字符串,
为了删除那些含有非数字的异常数据,就用到了translate函数:
SQL> delete from a, where length(translate(trim(a.t_no),'0123456789' ||a.t_no, '0123456789'))<> length(trim(a.t_no));
(10)replace
语法:REPLACE(char, search_string,replacement_string)
用法:将char中的字符串search_string全部转换为字符串replacement_string,没有匹配的字符串就都不变。
举例:
SQL> select REPLACE('fgsgswsgs', 'fk' ,'j')from dual;返回值from dual;
结果是fgsgswsgs
SQL>select REPLACE('fgsgswsgs', 'sg' ,'eeerrrttt')返回值from dual;
结果是fgeeerrrtttsweeerrrttts
分析:第一个例子中由于'fgsgswsgs'中没有与'fk'匹配的字符串,故返回值仍然是'fgsgswsgs';
第二个例子中将'fgsgswsgs'中的字符串'sg'全部转换为'eeerrrttt'。
总结:综上所述,replace与translate都是替代函数,只不过replace针对的是字符串,而translate针对的是单个字符。
(11)decode()
DECODE函数,它将输入数值与函数中的参数列表相比较,根据输入值返回一个对应值。函数的参数列表是由若干数值及其对应结果值组成的若干序偶形式。当然,如果未能与任何一个实参序偶匹配成功,则函数也有默认的返回值。
区别于SQL的其它函数,DECODE函数还能识别和操作空值。
语法:DECODE(control_value,value1,result1[,value2,result2…][,default_result]);
试图处理的数值。DECODE函数将该数值与后面的一系列的偶序相比较,以决定返回值。
value1 是一组成序偶的数值。如果输入数值与之匹配成功,则相应的结果将被返回。对应一个空的返回值,可以使用关键字NULL于之对应。
result1 是一组成序偶的结果值。
default_result 未能与任何一个值匹配时,函数返回的默认值。
例如:
select decode(x,1,'x is 1',2,'xis 2','others') from dual
当x等于1时,则返回‘x is 1’。
当x等于2时,则返回‘x is 2’。
否则,返回others’。
需要,比较2个值的时候,可以配合sign()函数一起使用。
SELECT DECODE( SIGN(5-6), 1 'Is Positive',-1, 'Is Nagative', 'Is Zero')from dual;
同样,也可以用CASE实现:
SELECT CASE SIGN(5-6)
WHEN 1 THEN 'Is Positive'
WHEN-1 THEN 'Is Nagative'
ELSE'Is Zero' END
FROM DUAL
此外,还可以在Order by中使用Decode。
例如:表subject,有subject_name列。要求按照:语、数、外的顺序进行排序。这时,就可以非常轻松的使用Decode完成要求了。
select * fromsubject order by decode(subject_name, '语文',1, '数学',2, '外语',3)
(12)nvl
nvl( ) 函数(类似于SQLSERVER的isnull)
语法: 1. NVL(eExpression1,eExpression2)
参数: 1. eExpression1,eExpression2
如果eExpression1的计算结果为null值,则NVL( )返回eExpression2。
如果eExpression1的计算结果不是null值,则返回eExpression1。
eExpression1和eExpression2可以是任意一种数据类型。
如果eExpression1与eExpression2的结果皆为null值,则NVL( )返回.NULL.。
1. select nvl(a.name,'空得') as namefrom student a join school b on a.ID=b.ID

