
- 1Mongodb中Security介绍
- 2SQL Server定期收缩日志文件详细步骤——基于SQL Server 2012_sql自动收缩日志文件
- 3Parallels Desktop Business Edition 19.4.0.54962中文破解版
- 4庆祝法国队夺冠:用Python放一场烟花秀
- 5【性能】什么是CPU密集型计算、IO密集型计算与多进程、多线程、多协程_cpu密集计算
- 6Linux工具入门:make工具与Makefile文件
- 7MySql数据操作总结_mysql表数据操作实验总结心得
- 8HashMap详解(含动画演示)
- 9使用Oracle创建数据库_oracle数据库创建代码
- 10Spring tool suite4 安装及配置_springtoolsuite4
百度百舸 AIAK-LLM 的大模型训练和推理加速实践_mfu 大模型
赞
踩
本文整理自 4 月 16 日的 2024 百度 Create 大会的公开课分享《百舸 AIAK-LLM:大模型训练和推理加速实践》。
今天要分享的主题是 AI Infra 相关的内容,主要内容分为四部分。
-
首先和大家一起讨论大模型给基础设施带来的挑战。
-
第二部分则是向大家介绍一个大模型训练和推理过程中的关键性能指标 MFU,以及为了提升这个 MFU 业界已经做的一些技术和手段。
-
第三部分则是从百度百舸 AIAK-LLM 实际落地过程中遇到的一些问题出发,通过解决这些问题我们将大模型训练和推理的 MFU 提升到了一个非常好的状态。
-
最后一部分则是从产品维度简单介绍下相关能力和理念。
1 背景需求
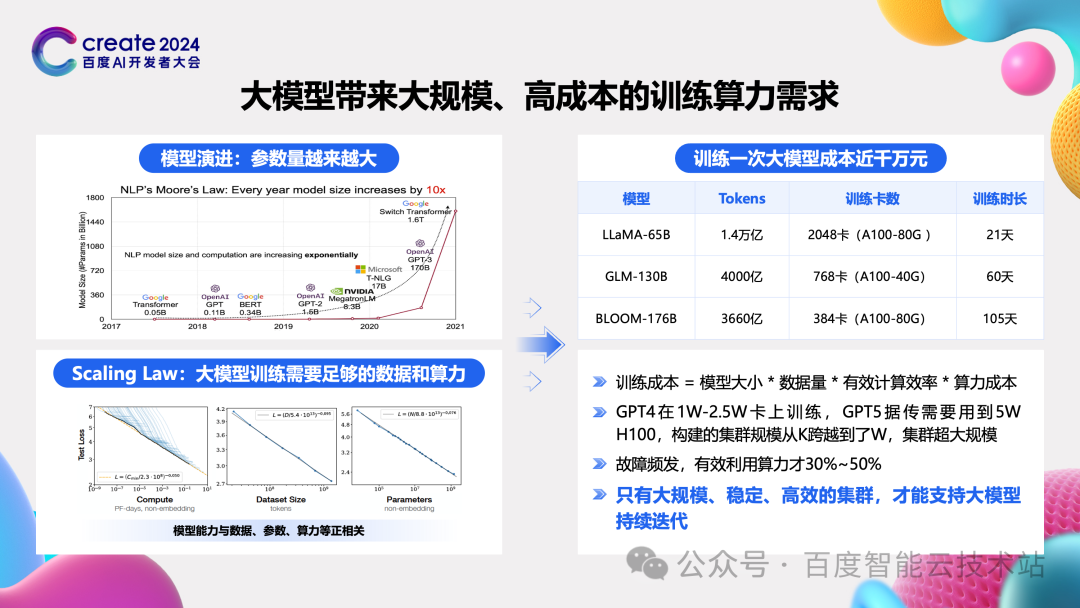
众所周知,大模型是越来越大。我选了一个时间跨度更长的图,可以更好地感受到模型大小在过去这么多年的变化。平均来看模型大小每 1-2 年就会提升一个数量级。据传 OpenAI GPT-5 模型大小将达到惊人的十万亿参数规模。
与大模型配套的则是数据越来越大。为了能更好的激发出大模型的潜能,我们需要成比例的数据来给他注入知识,这样才能产生足够的智能。
大模型乘上大数据,不是加上,是乘上,这必然需要庞大的算力支持。
下图右上角也汇总了一些公开资料的情况。以现在最受欢迎的 Llama 系列为例,第一代的参数规模是 65B,所使用的数据量达到了 1400B,非常大,因此投入了多达 2048 卡的 A100,花了近一个月时间。这显然就带来一个巨大的问题,训练成本。训练成本是和模型大小、数据量、有效计算效率、算力成本呈正相关的。
第二个方面的问题则是规模。GPT-4 传言用了 1W-2.5W 张卡进行训练,GPT-5 则传言至少需要 5W 张 H100,这需要有相应的技术来构建这么大规模的集群。
第三个方面则是去年很多大模型公司都遇到的问题,集群故障频发,有效训练时间才 30%~50%。
因此大模型给基础设施带来的挑战就是需要一个大规模、稳定、高效的 AI 集群,只有这样才能支持大模型持续训练迭代。
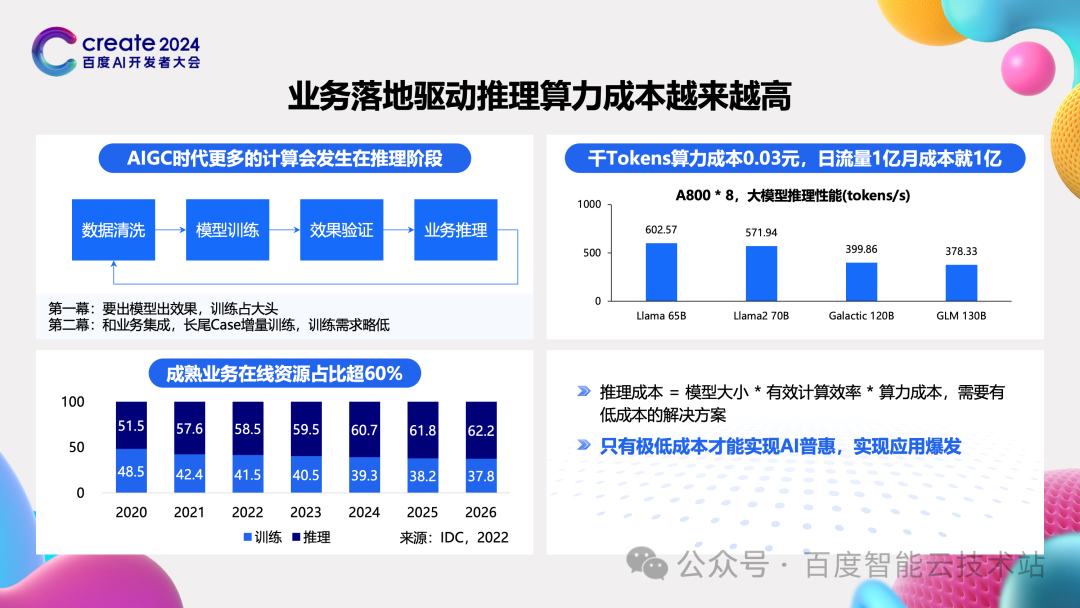
在一个 AI 业务的发展中,出现的第一幕肯定是训练,这涉及到数据清洗、模型设计、模型训练,然后配合一些效果评测,这是大家关注的焦点。
但是更重要的是第二幕。只有将模型转换成业务,落地成应用,这个模型才有价值,同时在部署落地后又搜集到更多的反馈,特别是长尾 case 和需求,然后再做迭代训练。在这个过程中的训练频度或者力度会显著下降,在这个阶段更多考虑的就是推理对基础设施的需求了。
左下角我引用了 IDC 2022 年的一个报告,说明随着业务成熟的落地,推理会占据 60% 以上的算力。当达到这个阶段 AIGC 时代就会真正到来了。
推理是需求的主体后核心问题是什么呢?和训练相比,在单一任务的规模和稳定性上的要求都会小些,推理的核心问题就是成本了。
在下图右上角,我们用早期的推理性能数据做了一个非常粗略的核算。按照 8 卡来推理一个 65B 以上的模型性能来看,每个 token 的成本可能高达 0.03 元。而一个成熟的业务每日上亿的流量是非常容易的,这样每天的成本都高达一个亿。随着模型规模的扩大,流量的上涨,这个成本只会更高。其中,推理的成本和模型大小,算力的有效利用效率,还有算力本身的成本都成正比。
所以我们需要从这三个维度想办法,降低用户调用大模型的成本。只有这样才能实现 AI 普惠,才会驱动 AIGC 应用的爆发。
把前面的分析总结下,大模型时代 AI 基础设施:
-
需要有超大规模,万卡集群互联是必备的,并且需要能线性扩展,不然很多开销都消耗在了网络上;
-
要超级稳定,各种故障能感知到,具备自愈手段,在软件层面也要为不可避免的不能自愈的故障构建好的容错机制;
-
拥有极致算力的效率,不止是 GPU 卡极致效率,其他更低成本更优秀的 AI 芯片也同样达到极致效率。
只有这样,大模型的训推问题才能解决,才能催化出并支撑起大家构想的 AGI 时代。

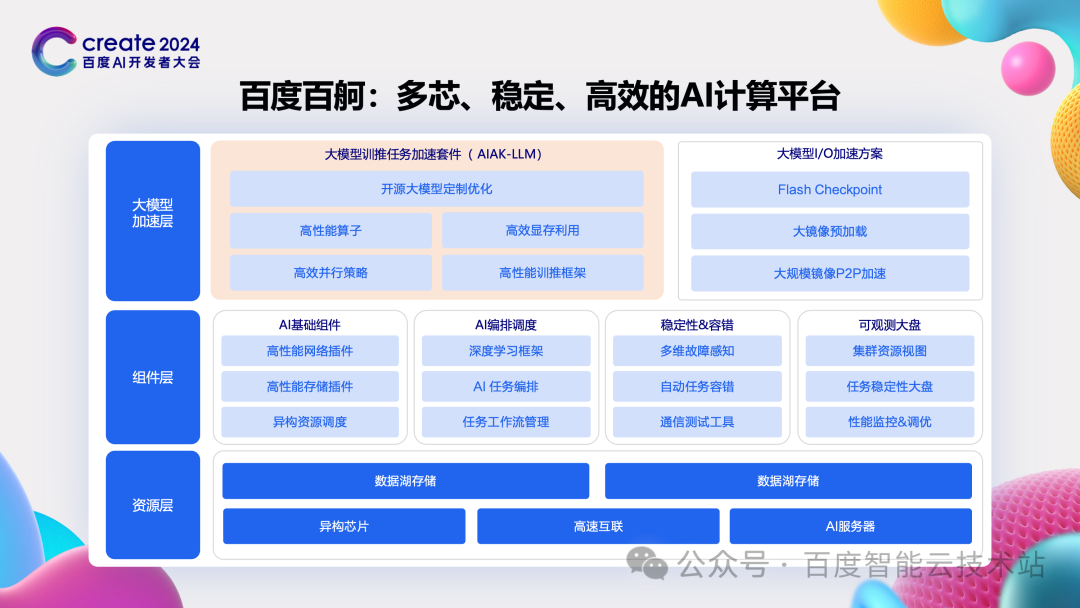
百度是国内最早探索大模型的公司,所以在公司内部,针对前面所说的规模、稳定性、训推成本等问题,很早就有关注到并有了非常多的沉淀。基于过去多年在 AI 方面的沉淀,百度智能云推出了百度百舸·AI 异构计算平台这个产品。到现在已经发展到了 3.0 阶段,全面释放出大模型相关的能力。
百度百舸主要分为三层:
-
最底层是资源层,提供大规模、稳定、成本优异的计算、存储等适合异构计算的基础云产品。
-
中间层是组件层,提供支持大模型训推的各种调度组件、容错组件等,支撑大规模的训练和推理任务,并保持稳定运行。
-
最上层则是大模型加速层,提供了计算、I/O 等丰富的加速能力,帮助大家把算力的效率发挥到极致。
今天主要给大家先分享分享百度百舸的「大模型训推任务加速套件 AIAK-LLM」 的内容。
那么,评估 AIAK-LLM 加速大模型训练和推理性能的关键指标是什么呢?
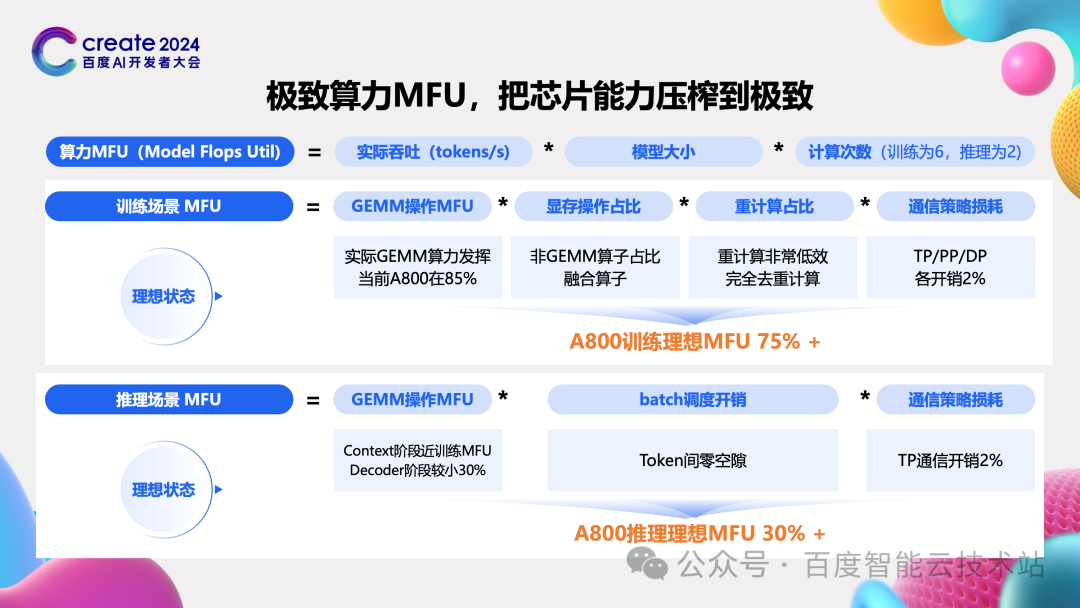
MFU,全称是 Model FLOPS Utilization,这是大模型中做性能分析经常出现的一个指标,是实际业务中 FLOPS 的数值与芯片标称 FLOPS 的比值。比如在 A800 上的吞吐换算出来的 FLOPS 是 100T,而 A800 的标称 FLOPS 数是 315T,那么他的 MFU 就是 100 除以 315,也就是 32%。
在介绍完 MFU 这个指标的定义后,我们再看看大模型训练和推理任务中,理想的 MFU 值是个什么样子。这里给了一个粗略的逻辑,我们以 GEMM 计算的 MFU 为 base。这个是假设芯片只做 GEMM 计算能达到的 MFU。
经过我们实测在 A800 上可以达到 80% ~ 85% 左右。一个好的训推系统,他能发挥的终极极限就在这了。但实际情况,在训练和推理过程中还会遇到其他非 GEMM 算子的计算、各种通信、任务调度等,这些都会对模型最后的 MFU 有影响,是一个相乘的关系。
这样我们就粗略地预估出在一个中等规模下,训练和推理在 A800 上的理想 MFU 分别是 75%+ 和 30%+。虽然这不是一个非常严谨的逻辑,但是给非常好的指引,我们需要穷尽所有方法,使得训练和推理的 MFU 接近这个值,或者刷新认知超越这个值。
2 业界训推技术
介绍完背景需求,以及我们做训推加速的终究目标。我们再一起简单看看社区做出的贡献以及 MFU 可以达到的状态。
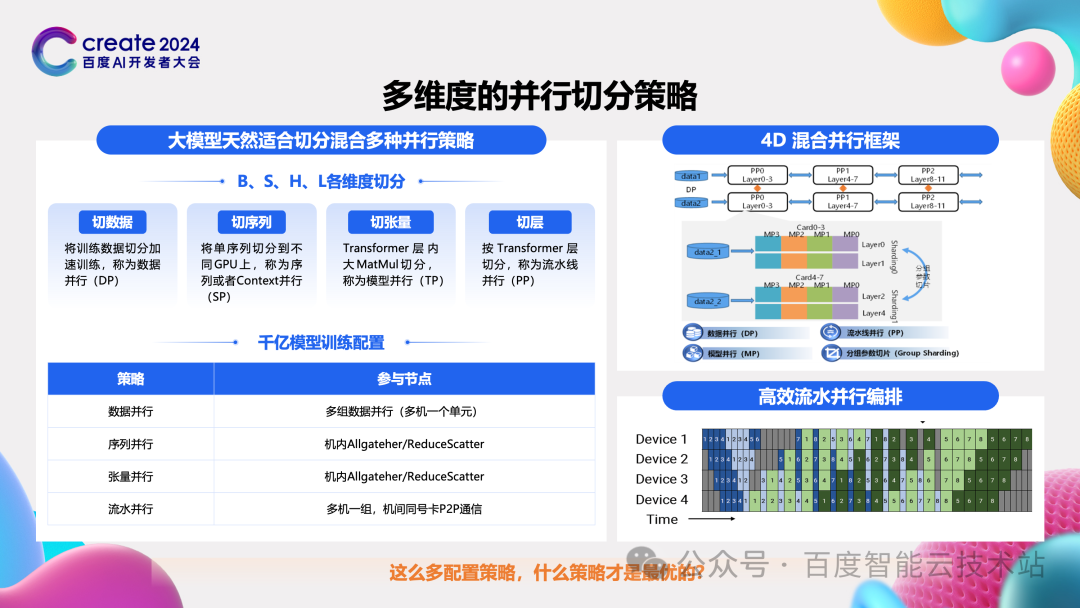
第一个是多维度的并行切分策略。为了能放下大模型,处理大数据,业界首先想到的就是做各种分布式的切分。
当前业界的分布式切分非常完备。我们这里做个简单的总结。这里没有按照切分策略的发展逻辑来组织,而是从大模型中典型的计算维度来看。无论是训练还是推理,大模型的计算围绕着 BSHL 这四个维度,接下来依次介绍下:
-
首先 B 也就是 BatchSize,它切的是数据。我们把所有数据切分成很多份,然后不同的芯片组来处理一份数据,这个就是数据并行。
-
第二个维度是 S,也就是一条条处理的数据,也称为序列。他可能很长 4K、8K、32K 甚至更长,将他们切分到不同芯片上进行计算就是序列切分。
-
第三个维度是 H,也就是我们所说的 HiddenSize。他代表了模型的宽度,将他横着来一刀切成两块,也就是我们经常说的张量并行。
-
最后就是 L,是模型的层数代表模型的深度。将不同的层切分开来也就组成了流水并行。
在这四个维度切分上,张量并行和流水线并行还会演化出更丰富的方法。其中张量并行,传统的方式是按照一维来进行切分。针对不同的情况、不同的芯片,业界又发展出了 2D,3D 等更高级的切分策略,简单来看就是可以把张量切成更小的大小。另一个是流水线并行,除了普通的流水组成外,也衍生出了 1F1B、interleved PP、zero bubble 等更细粒度的方案,每个方案都非常精妙。
在有这么多切分策略后,现在遇到的更大的问题是什么呢?这些策略该如何组合,怎样才能利用这些切分策略实现最好的性能?后面会给大家介绍下百度百舸的方案。
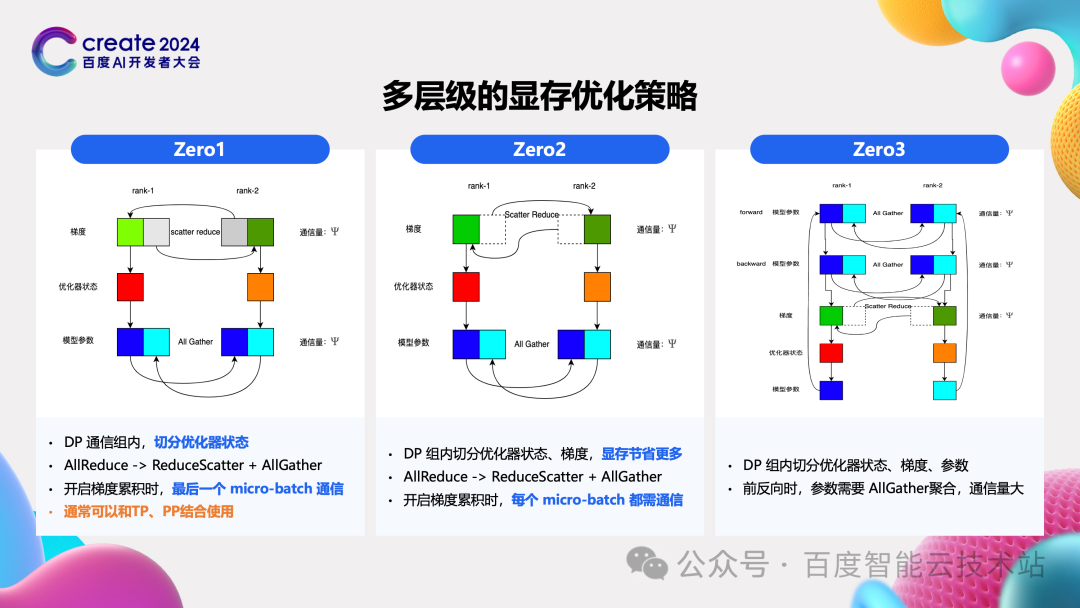
第二个研究方向是多层次的显存优化策略。他不是从计算维度,而是从显存占用维度来进行切分。
在大模型训练过程中,显存占用主要有三部分,首先是模型参数、然后是优化器、最后是反向计算的梯度,这就是一个完整的模型状态。在不同的数据并行分组中最终是要保持一致的。
那么显存优化策略,想到的就是在不同的数据并行中,不用存完整的这些信息,因为可以从别的分组中拿到。这就衍生出了被称为 zero1/2/3 的不同的显存优化策略。
由于在计算之前需要从其他数据分组中获得优化器,或者梯度,或者参数的分片,这就会引入大量 Allreduce 操作,所以 zero 的开销是非常大的。所以如何在节省显存容量和减少通信量之间达到平衡,是合理的利用 zero 策略的关键。
我们现在发现 zero1 的效用是最高的,配合前面提到的 TP 或者 PP。这样节省了显存,引入的通信量又是在可接受的范围内的。在显存优化中还有一个策略就是 recompute,简单来说就是丢弃掉前向计算中的一些激活值,在反向计算中需要这些激活值,重新计算一遍即可。在我们实际应用中发现,重计算是比较糟糕的一些策略,后面的 case 中也有介绍。
介绍完大模型训练的策略后,我们再来看看大模型推理的策略。去年整个社区的技术发展也非常迅速。
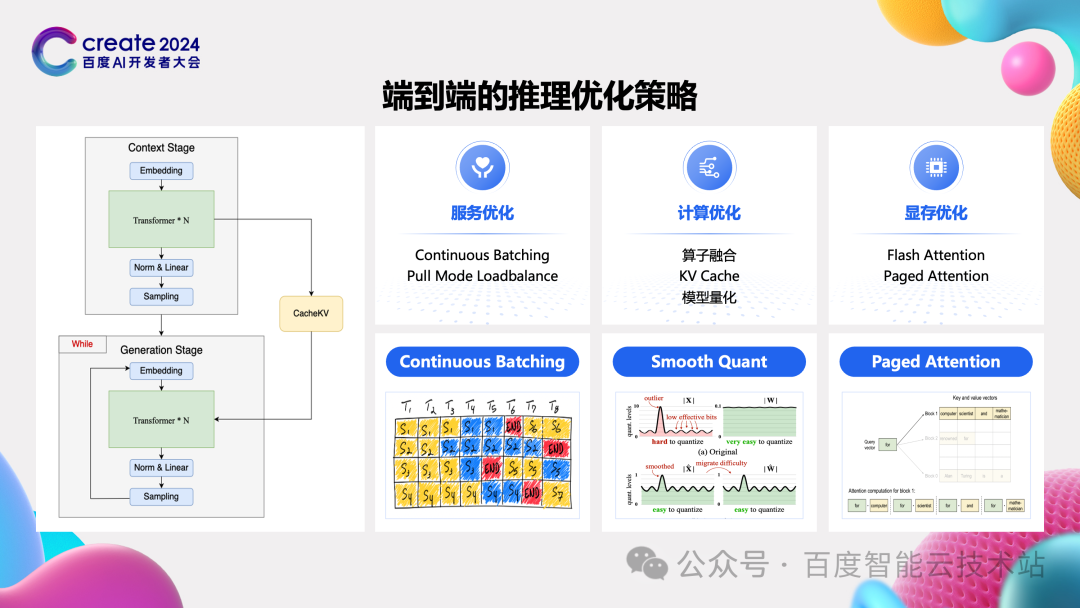
大模型推理遇到的重要问题又有哪些呢?我们总结了下,主要有三个方面的问题:
-
第一个方面的问题是输出长度不一的问题。传统的推理服务为了提高资源的利用效率,会做打 batch 的操作,就是把很多请求合并到一块进行处理,这样资源的效率就高了。刚开始大模型推理也是直接复用传统推理服务的 batch 策略,但很快发现了问题。输出长度不一样就会导致很多请求处理完后还需要等待最长的那个请求处理完,导致了大量的时间和资源浪费。这也就是 continus batching 要解决的问题,配合 pull mode 的方式,在有请求执行完毕后,就从请求队列中拉一个新的请求,重新 batching 上,保证持续有满 batch 的请求在处理。
-
第二个方面的问题则是计算效率。如左边这个图所示,大模型推理的逻辑就是根据前面的所有 token 来预估下一个 token,整个计算过程就是计算所有 token 的 qkv 向量,进而做 attention 计算。普通的逻辑就是每次都把前面所有的 token 拿来计算,这个时候我们发现前面 token 的 kv 向量已经计算过了。一个典型的优化策略就是缓存住每个 token 的 kv 向量,在计算 attention 时将新生成的 token 的 kv 向量和之前缓存的 kv 向量 concat 起来,进而做后面的计算,这样就节省了大量的计算时间,这就是 KV Cache。
-
第三个方面优化显存占用,早期的推理服务所处理的输入输出是比较规整的,所以会预先分配每个请求所需要的显存空间。但生成式 AI 输入输出长度都相差非常大,提前分配固定的显存空间就带来了非常大的浪费。借鉴操作系统动态管理内存的思路,业界普遍采用 PagedAttention 的优化。和传统算法不同,PagedAttention 将每个序列的 KV Cache 划分成块,每个块包含固定数量的 KV 向量,在显存管理上则通过逻辑块和物理块的映射关系,实现了每个序列的 KV Cache 块不连续存放。
这样就增加了非常大的灵活性,我们可以应对不同的输入长度和不同的输出长度,动态来申请新的块存储新的 KV Cache,而在计算层面则通过逻辑块与物理块的映射关系找到序列所有的 KV Cache 进行计算。这样就极大减少了静态分配显存带来的浪费。
针对这三个问题业界都有了非常好的解决方案,现在比较受欢迎的就是 vLLM,上面列出来的这些功能都做了很好的实现。
如刚才介绍,社区的技术非常多,关键问题都解决了,现在可以达到的算力 MFU 是个什么样子呢?
我们去年做了大量的测试,32 卡、256 卡……我们发现训练的 MFU 普遍能达到 60% 左右,推理的 MFU 达到 10% 左右。这和我们前面粗略预估的 MFU 目标还有非常大的空间,这也是百度百舸的「大模型训推任务加速套件 AIAK-LLM」 期望去解决的问题。
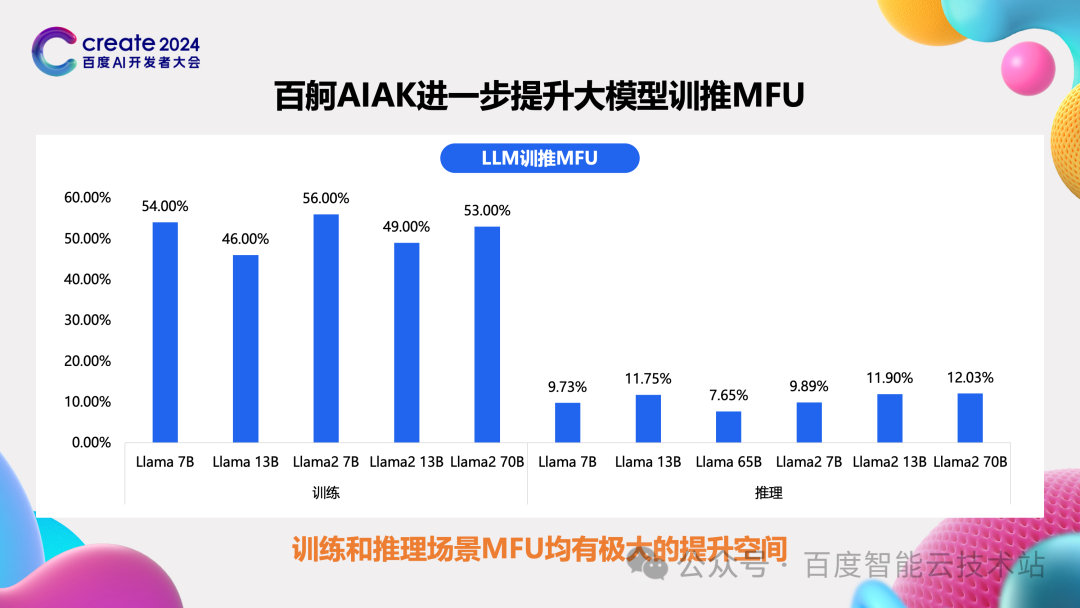
3 百度百舸 AIAK 核心优化
3.1 训练优化
所以接下来,我们从一些实际 case 出发给大家分享下 AIAK-LLM 中的一些核心技术。
首先看训练。前面也介绍了开源方案在一些好的情况下能达到的 MFU,这两者之间有比较大的差距。
图中展示了一个典型 case,左边是训练过程中的 trace 图。从这个图中我们可以看出,还是有非常多的时间不是在进行密集的计算,因此我们将每个阶段的影响进行的细化,主要看到这四个方面的问题。
-
第一个方面的问题是 TP 占据的时间较长,占到了近 10%,和我们前面预估中用到的 2% 甚至零开销差距较大。
-
第二个方面的问题也是我们前面介绍显存优化的时候提到的,由于显存不足开启了重计算,占据了多达 25% 的时间,
-
第三个方面的问题则是一个常见问题,elementwise 算子的开销。这个问题最直接,一般都会想到去做算子融合。前两个问题就需要做专门的研究,产出一些相关的策略。
-
第四个方面的问题则是如何为训练任务找到最优的并行参数。
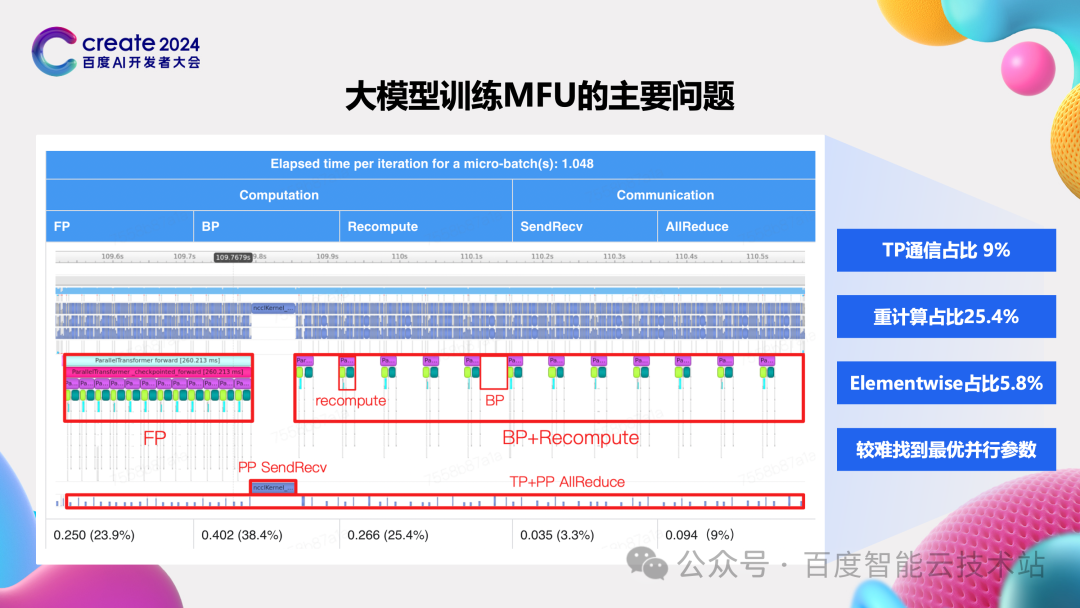
首先第一个问题 TP 通信占据时间长的问题。
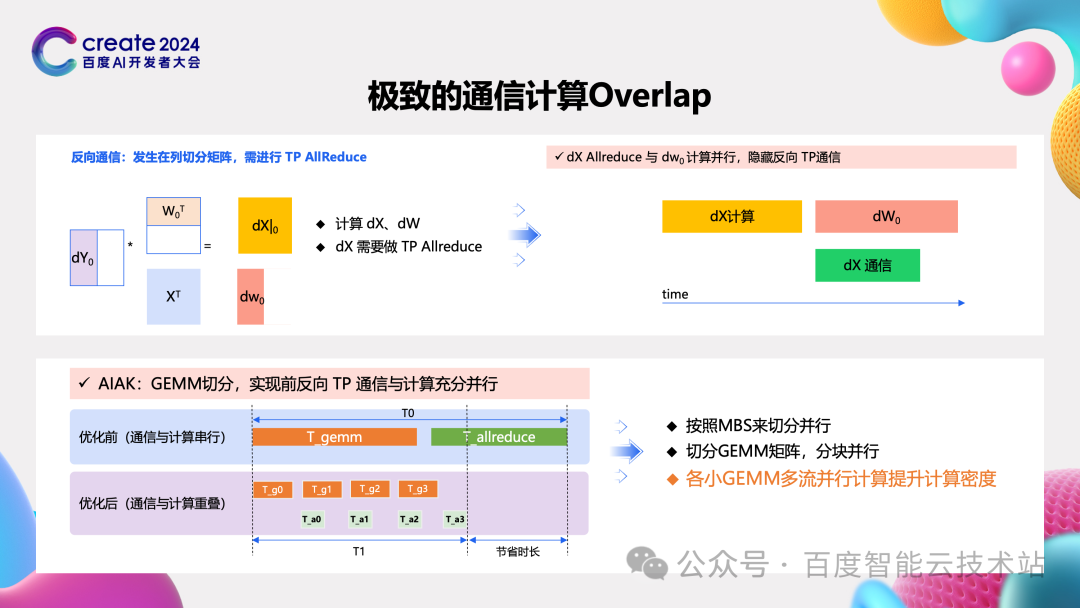
在大模型训练过程中,其实不只是 TP 切分,在 DP 切分中也是这样一个执行范式,就是一个很大 GEMM 后面跟着同步的通信。由于这个通信是同步的,所以 GPU 的计算是暂停的。针对这个问题想到的最直接的方法就是将计算与通信做重叠。
针对 TP 通信,我们尝试了两种方法:
-
主要针对反向计算的过程。因为反向计算涉及到针对于输入和参数这两个维度计算梯度。所以我们将计算输入的梯度和计算参数的梯度分解开。当计算完输入的梯度之后,就立即发起相关的通信。这样的话,计算参数的梯度和这个通信就可以重叠起来。针对 GEMM 加通信这种执行范式,我们又进一步的去思考:是否像可以切分 TP 那样,把 GEMM 进一步切分成很多小块,计算一块通信一块,计算一块通信一块,这样后面的计算自然就可以重叠前面的通信了。
-
再进一步观察,我们切小了这些 GEMM 操作之后,其实会引入一个新问题。这个 GEMM 操作的计算密度太低了,MFU 反而不一定是能够得到一个很大的提升。所以我们又开始去尝试,去将几个小的 GEMM 操作并行的去执行。执行完后就发起相关的通信,这样没有通信的时候并行的执行计算 MFU 会比较高,有通信的时候,通信和 GEMM 重叠,通信也被隐藏住了。
经过以上优化,我们在 256 卡这种规模进行测试,TP 通行时间的占比仅仅只有 2% 了。
第二个问题针对重计算的问题。
在一些小规模的情况下,即使做了 zero 相关的优化,显存还是不够,这个时候就会去做重计算,丢弃前向计算过程中的激活值节省显存,在反向计算过程中需要相应的激活值则重新计算一遍。
现有的重计算有 full(uniform)、full(block)、selective 三种,我们在调优某个国内模型的时候发现这三种策略还是不能很好的平衡计算的浪费和显存的节省。因此我们构建了一个融合的模式,通过参数可以指定部分层采用 full(block)策略,部分层采用 selective 策略,再通过测试可以找到一个更好的平衡点,从而获得性能上的提升。

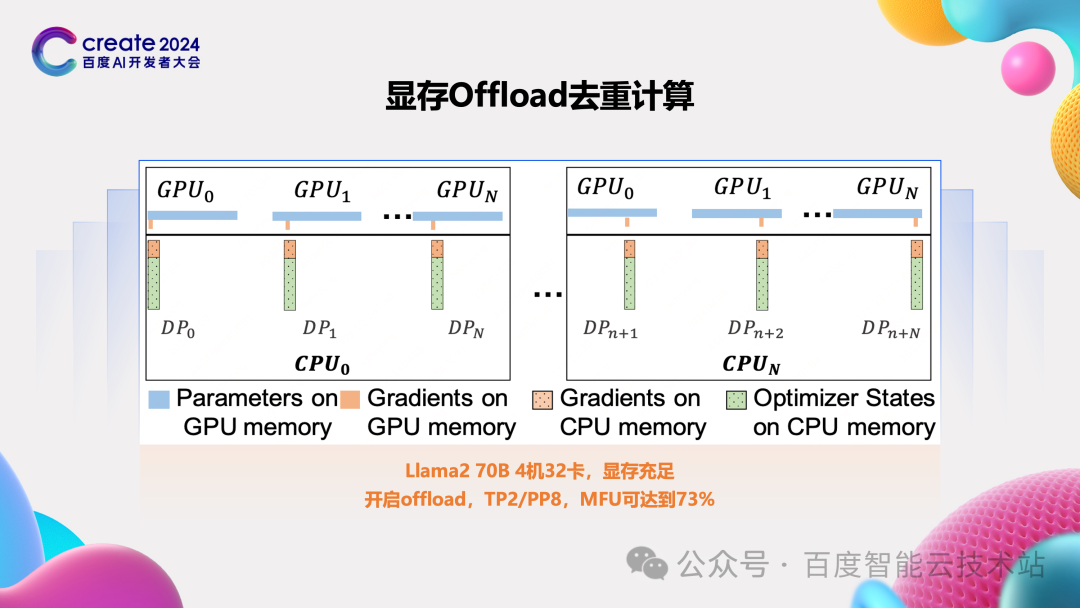
除了 Hybrid Recompute 策略,我们还针对 zero 的一个延伸能力 zero-offload 做了深入研究并在百度百舸的 AIAK-LLM 中做了实现。
zero-offload 核心的原理,和我们前面介绍的 zero1/2/3 这些策略不一样,他将优化器、参数或者梯度给 offload 到 CPU 的内存中,当需要的时候则发起 Host To Device 的操作,将相应数据拉到 HBM 中进行计算。
我们测试了 Host To Device 的带宽后发现,如果只是 offload 优化器,带来的时间开销是比重计算要小很多的,所以我们做了一个优化,通过 zero offload 去掉了很多场景的重计算。
这还没完,我们进一步思考,在显存充足的情况下,我们通过 zero-offload 节省了显存,那这些显存是否可以给 TP/PP 这些切分策略或者 MBS 这些参数提供空间,比如更小的 TP 或者更大的 MBS。经过实测,部分场景还真符合咱们这个预估。
比如 Llama2 70B 4 机 32 卡这个场景,显存充足,本来最优 TP 策略是 TP4,但是开启 offload 后,TP2/PP8 可以获得一个更好的性能,MFU 可达到 73%。
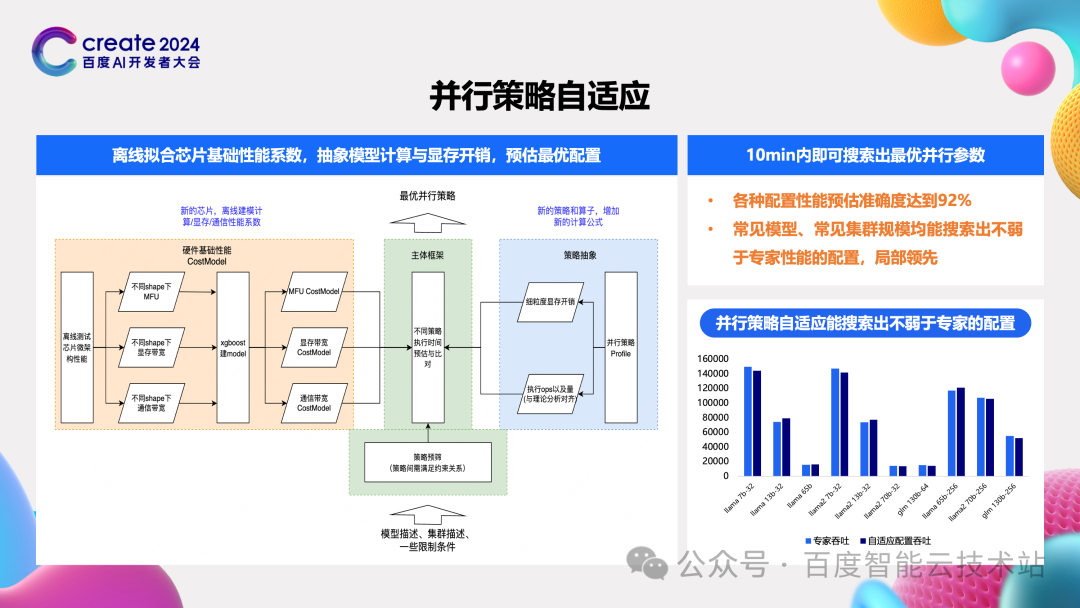
在大模型训练过程中,我们做的第三个方面的探索就是针对前面反复提到的,并行策略这么多,怎样配置才能获得最好的性能呢?
百度百舸给出的方案就是通过一套自适应的方法来预估出最优配置。核心思路就是三点:
-
第一点对于一个确定的切分策略,从理论上是能计算出每块卡上所分配的数据和参数的,这样我们就能很好的计算出每块卡上的计算量和所需显存容量。
-
第二点呢对于每个硬件,是可以通过离线测试来构建它的计算、显存访问、通信的性能模型。
-
第三给定一个模型和一个集群,我们是能穷举出所有可能的并行策略的。结合前面两点,我们预估出每种并行策略下的计算量以及芯片所对应的性能,那么每种并行策略,我们都能预估出他的执行时间,自然而然就可以选择出最优配置了。
在这个思路下,我们实现了并行策略自适应的工具。由于是纯理论计算并且每个配置是独立的,因此可以多进程并行计算,这样 10 min 内就可预估出最优配置了。我们将这个最优配置和专家配置相比,在大多数模型和集群规模下,均获得了不差于专家甚至好于专家的性能。
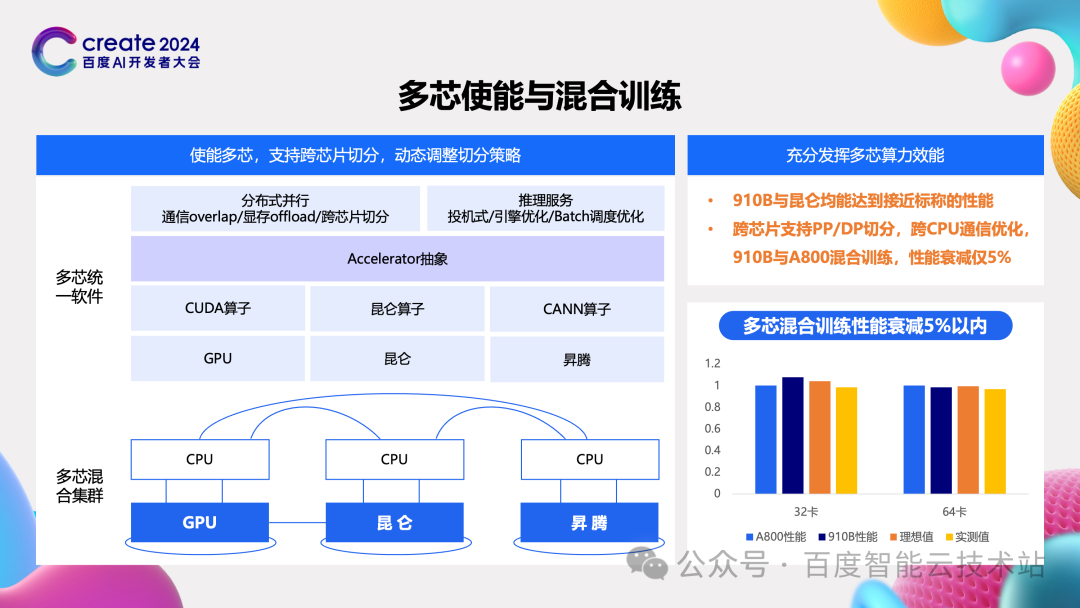
在我们的集群中不止有 GPU,还有昆仑、昇腾等多样化的算力,怎样将这些算力也都充分利用起来,是我们训练加速需要解决的一个问题。
这个问题我们分为两个层次:
-
第一个层次就是将多样算力单独使用起来,并且能让这些芯片算力的 MFU 提升到一个非常高的状态。根据前面理想 MFU 的估算公式可以看出,这里面有两个问题,第一个问题是芯片的计算效率要能做起来,第二个问题是策略的开销要能控制住。为了解决这两个问题呢,我们的加速套件通过 accelerator 抽象做了一个拆分,在 accelerator 抽象以下是各种芯片的算子,这里和芯片厂商合作优化计算的效率,在 accelerator 抽象之上则是多芯统一的并行策略和工具,这样就能对齐 GPU 上的策略,然后再配合芯片上独有的策略,我们把昇腾、昆仑的 MFU 也优化到了非常好的状态。
-
多芯算力使能第二个方面的问题就是混合训练。我们现在在做模型训练的时候,都是使用单一的芯片来进行的,出于成本和供应原因,很多时候就很难构建出足够规模的集群,如果能将所有算力都用于训练将是一个非常有价值的技术。但是多芯使能会遇到三个方面的问题:
-
第一个方面就是在集群中不同芯片算力不一样,需要实现非常灵活的 PP 或者 DP 切分来平衡计算任务。
-
第二个方面则是不同芯片最优的 TP 切分策略是不一样,比如昇腾最优切分是 TP=8,而 A800 最优切分是 TP=4,因此实现一个混合的 TP 切分策略才能充分发挥各自芯片的能力。
-
最后也是一个非常难的问题,当前不同芯片的通信库是不能直接互通的。特别是华为昇腾,在和昇腾芯片通信过程中必须经过 CPU,需要实现高效的跨 CPU 通信能力。
只有在解决这三个方面的问题后,再搜索出最优的策略组合,在小规模 32 卡、64 卡,甚至百卡千卡规模下,多种芯片混合训练的效率衰减控制在 5% 以内。
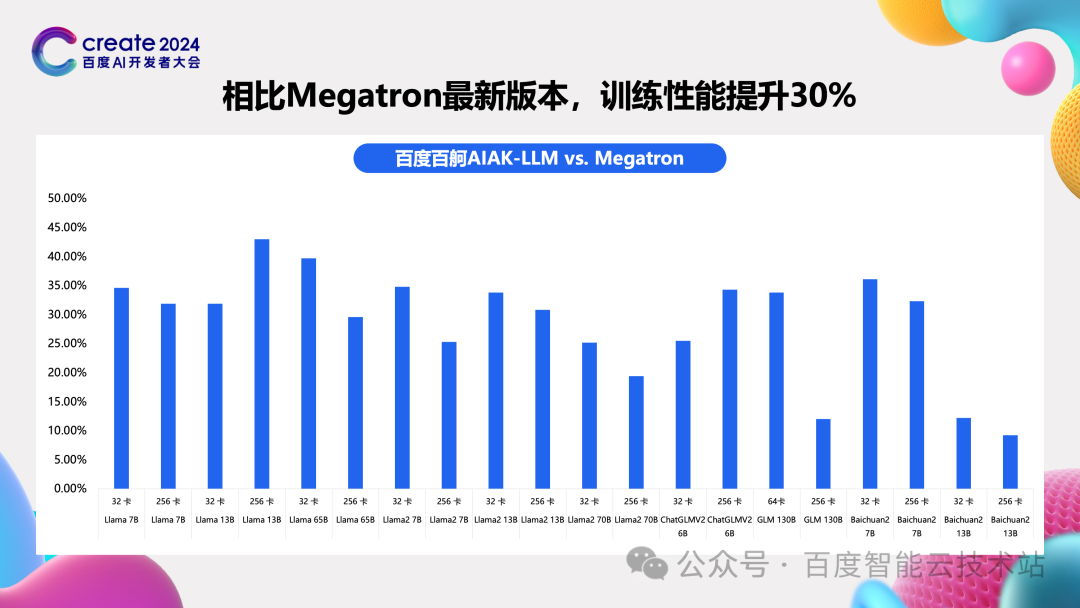
在社区的基础上,我们以理想 MFU 为牵引,采用我们刚才这个 case 的分析方法和手段,使得各种模型,各种规模下性能都有了比较明显的提升,平均来看提升了 30% 以上。
3.2 推理优化
介绍完训练加速,我们再来看看推理加速。
这里也放了一个典型 case 的性能 trace 图,我们看到推理过程中显著存在两个方面的问题。第一个问题是 token 间的空隙非常大,甚至可能达到 50%,第二个问题就是图中黄色部分的计算 MFU 不高。因此我们就围绕着这两个方面来进行优化。
首先说 token 间。我们从一个执行流来看,推理做完前向计算后,在计算下一个 token 前还有非常非常多的步骤需要做。这包括 sample、check stop 这些扫尾操作,也包括 to text,to client 这些返回内容的操作,还包括 scheduler 等下一个 token 相关的操作。这么多操作步骤在当前的一些方案中都是串行执行的,自然就引入了大量的 token 间等待时间或者说是 token 间空隙。
我们解决这个问题的核心思路有三点:
-
第一点把一些操作放到 GPU 上来执行,比如 sample 计算。
-
第二点就是极致的并行化。这包括 to text 与后面一些阶段的并行,同时 to client 我们采用多进程的模型实现并行化。
-
第三点则是用 C++ 重构 scheduler 的模式。现在像 check stop 这种操作都是和 sequence 数目正相关的,因此我们重新设计了 slot 的逻辑,让这种操作都可以并行的去执行,进而消除或减少了相应的等待时间。
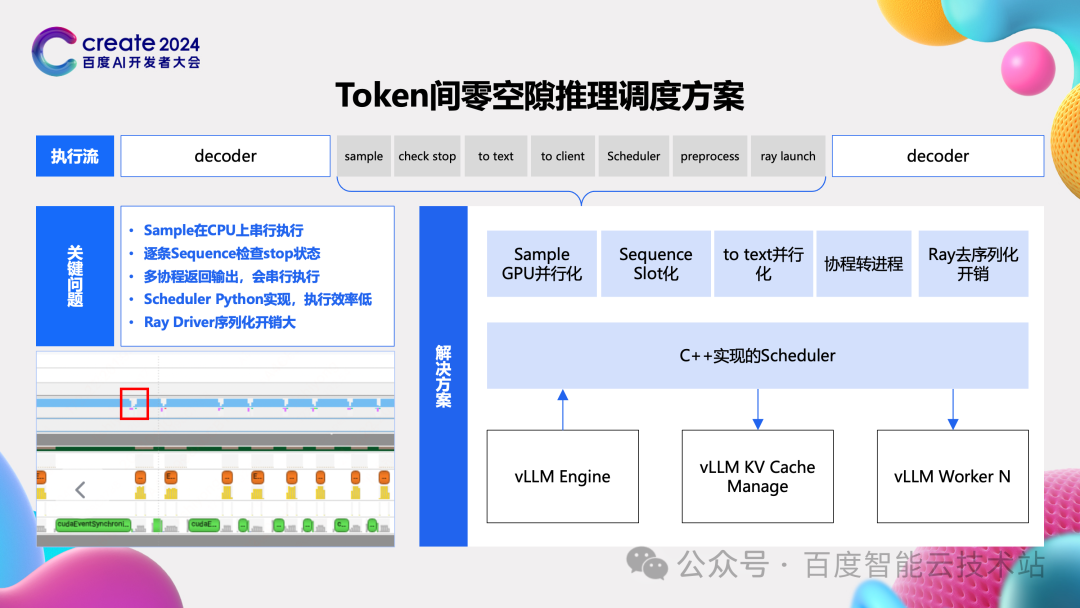
第二个方面的问题则是推理过程中 GEMM 的效率问题。
我们通过细粒度的 profile 分析发现,影响推理阶段 GEMM MFU 的因素主要就是因为 decoder 阶段的输入较小,导致 GEMM 计算中的 m 较小,从而 MFU 较小。
业界一个比较好的尝试就是通过大小模型结合来缓解这个问题。具体的原理是先通过一个用相同数据集训练好的小模型来生成多个位置的 token,然后再经过原始的大模型并发的进行各 token 的计算,来选择每个位置正确的 token(不正确的会丢弃掉),decoder 阶段的 MFU 会有比较大的提升,这样在一次计算中即可产出多个位置的 token。小模型产生的 token 准确度越高,大模型采纳的 token 越多,由于不正确而丢弃掉 token 所对应的计算浪费越少,最后整体效率会有比较大的提升。根据我们实测,特别是在低延迟场景,效率可提升近 60%。
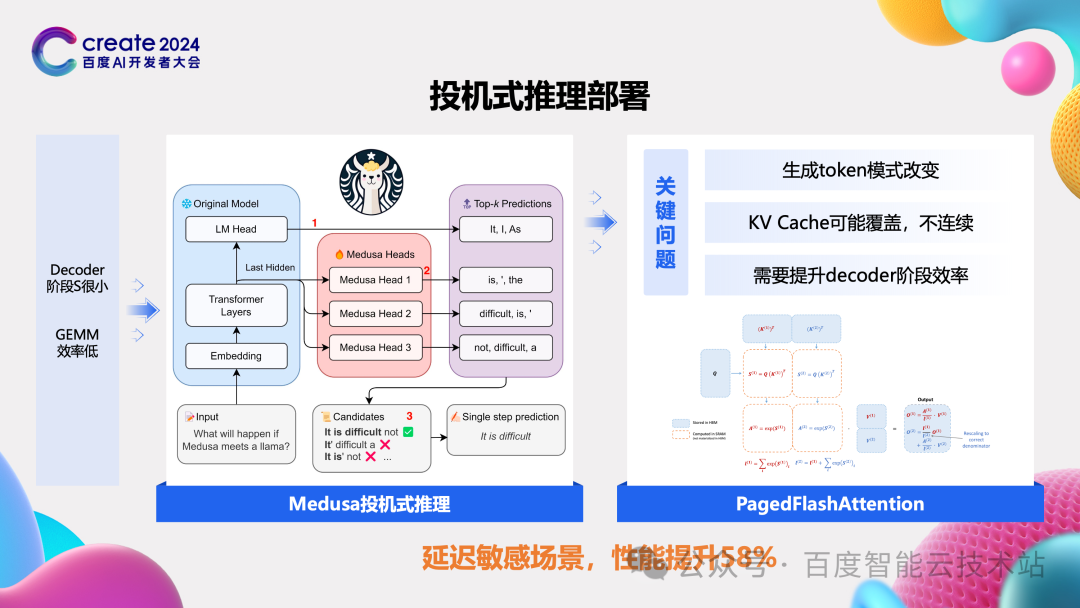
除了前面介绍的这两个非常重的功能外,为了能让开源模型高效的推理。我们还解决了大量功能和准确性上的问题。
这里列出了几个点:
-
第一个问题是精度方面的,也是我们遇到的最大的一个问题,sample 的精度,我们针对 greedy 等策略做了大量的测试,fix 了一些计算逻辑,最后保证各种 sample 策略下精度都是 OK 的。
-
第二个是一个非常有意思的功能。在当前的 vLLM 中输入是按照 2D 来组织的,不同长度的 sequence 需要 padding 成相同的长度,这样就引入了大量无效的 padding 位的计算。一个好的解决思路就是 sequence 展开拼接,也就是 1D 的组织方式,消除对齐所需要的 padding 操作,经过我们的实测啊可以提升 10~20% 的吞吐。
-
此外,为了能让推理服务能部署到客户的生产环境中,我们还实现了 extention 的扩展操作,这样当你需要修改 tokenization、preprocess、postprocess 都不需要修改引擎主体,而是通过 extention 的方式注入进去,极大提升了推理产品的易用性。
总之推理加速是比训练加速来说更细致的工作。

通过这些细致的工作,我们将大多数模型的推理性能提升了 60% 以上。考虑到投机式推理使用的场景,性能则会更高。
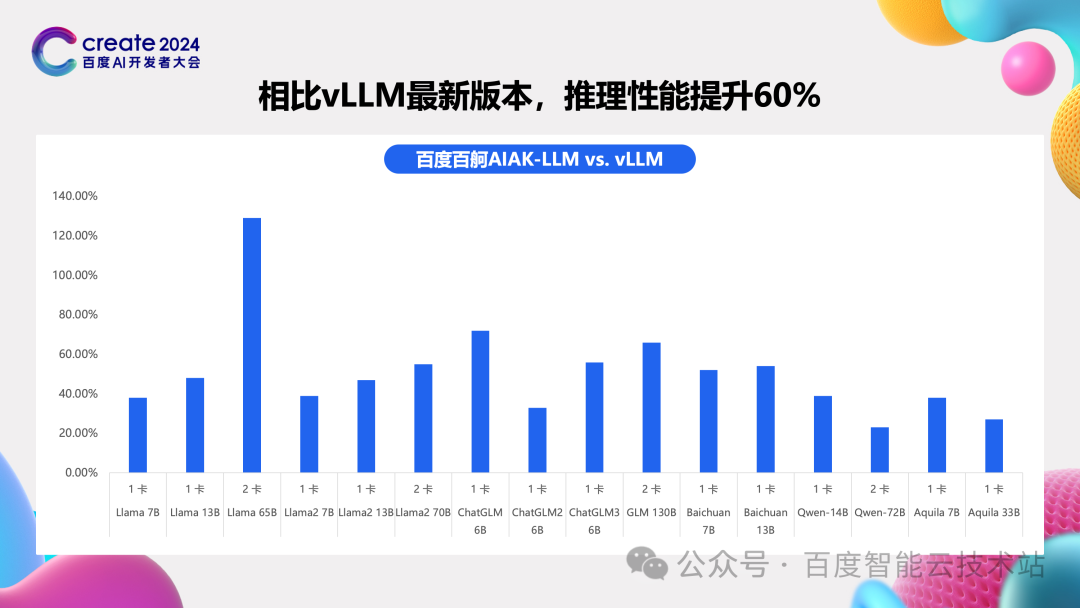
4 产品介绍
前面的内容,我们用两个 case 串了一些我们觉得非常有意思的思考和优化。我们还有很多问题还在研究并持续提升我们训推的性能。
为了能让这些持续的研究成果被客户使用起来,我们在百度百舸的功能上做了很多工作。当前大家做模型研发都离不开一个社区 Hugging Face,大家的模型是从 Hugging Face 来的,早期的代码也是 Hugging Face 的,我们这种专有的加速工具对于早期客户来说往往遇到切换成本高的问题。我们做了两个方面的产品工作:
第一个方面将 AIAK-LLM 对接到 Hugging Face 的生态中,这样早期客户可以少量修改就将自己 Hugging Face 代码对接到 AIAK-LLM 上,或者通过分层交付的库对接到自己的框架中,快速评估相关性能收益。与 Hugging Face 相比,能获得比前面所说的 30%、60% 更大的性能提升。
第二个方面的产品工作就是正在完善三个辅助工具,checkpoint 转换工作能实现各种模型 checkpoint 的互转,一条命令即可。精度对齐工具能将 AIAK-LLM 上的计算值和 Hugging Face 上的计算值清晰地展示出来,并标记出计算值有差异的地方,再针对性分析。性能分析工具更好地展示各个阶段时间开销,便于客户进一步优化。
通过 Hugging Face 对接,完善的辅助工具,再加上百度百舸原生适配好的 20 多个模型,我们期望能做到客户开箱即用,快速对比、使能和二次开发自己的产品。
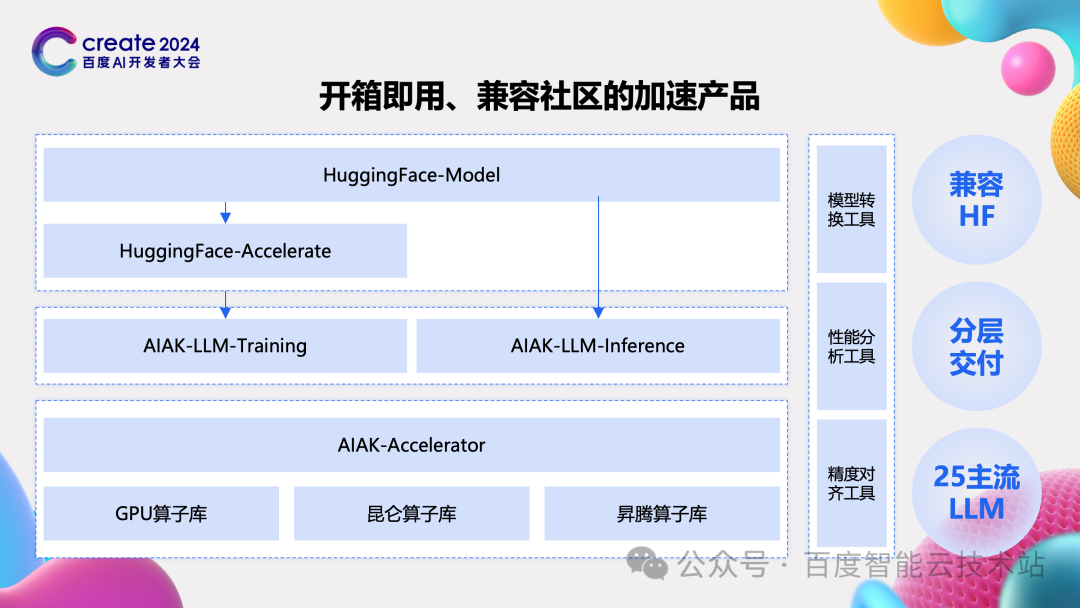
今天要分享的主要内容就是这些了,最后衷心希望通过百度百舸的「大模型训推任务加速套件 AIAK-LLM」,能让客户在百度智能云上买到的每一分算力都物尽其用,物超所值,谢谢大家。
——————END——————
推荐阅读

