
热门标签
热门文章
- 1xilinxFPGA-SPI协议详解(基于verilog)_xilinx spi 文档
- 2MySQL的配置方法以及数据库配置常见错误及其解决方法_数据库中没有表配置数据怎么办
- 3数据库_MySQL: mysql数据类型的用法介绍_mysql数据类型与使用
- 4Pulling is not possible because you have unmerged files. hint: Fix them up in the work tree
- 5第一篇博客------自我介绍_如何介绍自己的博客
- 6字符串匹配(BF,KMP,BM)_int match(const char*p
- 7如何理解python包的离线安装?_gitpython 离线安装
- 82017年度人工智能事件大盘点
- 9MySQL【部署 03】8.0.25离线部署(下载+安装+配置)Failed dependencies 问题处理及8.0配置参数说明_numactl离线安装
- 10数据库系统概论(第五版)创建Student、Course、SC表的步骤_数据库中有三张表,分别为student,course,sc
当前位置: article > 正文
python 读取pcap文件,并根据筛选条件,读取udp包数据_python 读pcap
作者:正经夜光杯 | 2024-08-01 00:20:06
赞
踩
python 读pcap
要读取一个PCAP文件并根据筛选条件(例如,仅提取UDP包)处理其中的数据,可以使用Python的scapy库。以下是一个简单的示例,演示如何做到这一点:
首先,确保你已经安装了scapy。如果尚未安装,可以通过pip安装:
bash
pip install scapy然后,你可以使用以下代码来读取PCAP文件,并筛选出所有UDP包:
python
- from scapy.all import *
-
- def read_and_filter_pcap(pcap_file, protocol="UDP"):
- """
- 读取PCAP文件并根据协议筛选数据包。
-
- :param pcap_file: PCAP文件路径
- :param protocol: 筛选的协议,默认为UDP
- """
- packets = rdpcap(pcap_file) # 读取PCAP文件中的所有数据包
- filtered_packets = [pkt for pkt in packets if protocol in pkt] # 根据协议筛选数据包
-
- for packet in filtered_packets:
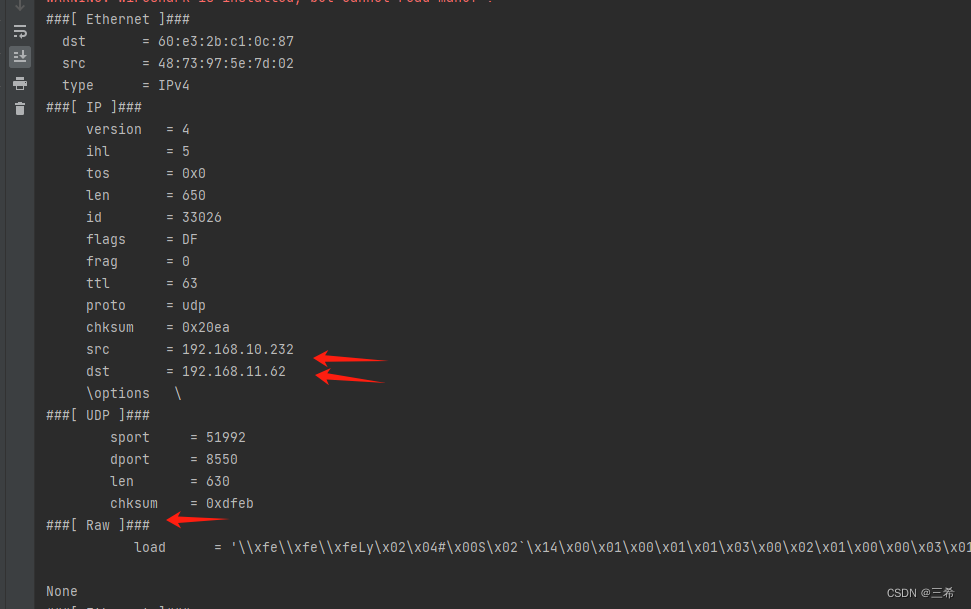
- print(packet.show()) # 显示每个符合条件的数据包详情
- # 或者直接访问UDP层的数据,例如:
- # udp_data = packet[UDP].payload
- # print(udp_data)
-
- print(f"Total {len(filtered_packets)} {protocol} packets found.")
-
- if __name__ == "__main__":
- pcap_file_path = "filtered_udp.pcap" # 你的PCAP文件路径
- read_and_filter_pcap(pcap_file_path)

这段代码定义了一个read_and_filter_pcap函数,它接受一个PCAP文件路径和一个协议名称作为参数,默认筛选UDP协议的数据包。函数首先使用rdpcap函数读取PCAP文件中的所有数据包,然后通过列表推导式筛选出指定协议的数据包,并打印出每个包的详细信息。如果你想进一步处理每个UDP包的数据(例如提取负载),可以根据需要修改打印部分的代码。
请将pcap_file_path变量替换为你实际的PCAP文件路径。
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/正经夜光杯/article/detail/911442
推荐阅读
- b站视频下载 ...
赞
踩
相关标签

