
- 1华硕主板安装win11 开启TPM_enable firmware tpm
- 2【编译原理文法概述】
- 3怎么给共享电脑设置密码_电脑共享密码怎么设置
- 4uniapp 荣耀手机 没有检测到设备 运行到Android手机 真机运行_uniapp真机运行检测不到设备
- 5要入坑Python,你居然不懂啥是conda,venv, pyenv ,virtualenv???_conda pyenv
- 6macOS:无法打开“xxx”,因为无法确定(验证)开发者身份_mac无法打开软件,因为无法验证开发者
- 7Unity XR Interaction Toolkit(VR、AR交互工具包)记录安装到开发的流程,以及遇到的常见问题(一)!_unity xr interaction toolkit waspressedthisframe
- 8服务器离线安装rabbitmq 以及版本关系 各个依赖下载_rabbltmq3.7.15导入依赖版本应该是多少
- 9makefile中的宏_makefile包含宏
- 10基于Android Studio实现蓝牙组网_androidstudio蓝牙开发
SDXL1.0大模型安装与使用_sdxl1.0版懒人包如何使用
赞
踩

个人网站:
前言
使用 Stable Diffusion XL,您可以使用较短的提示创建描述性图像,并在图像中生成文字。该模型在图像生成功能方面取得了重大进步,提供了增强的图像合成和面部生成功能,从而产生令人惊叹的视觉效果和逼真的美感。(但是,可能是后续的事)
- 更高水平的照片级写实能力
- 图像合成和人脸生成
- 使用较短的提示来创建描述性图像
- 生成清晰文本的能力更强
- 丰富的视觉效果和令人惊叹的美学

一、模型下载使用(简单体验)
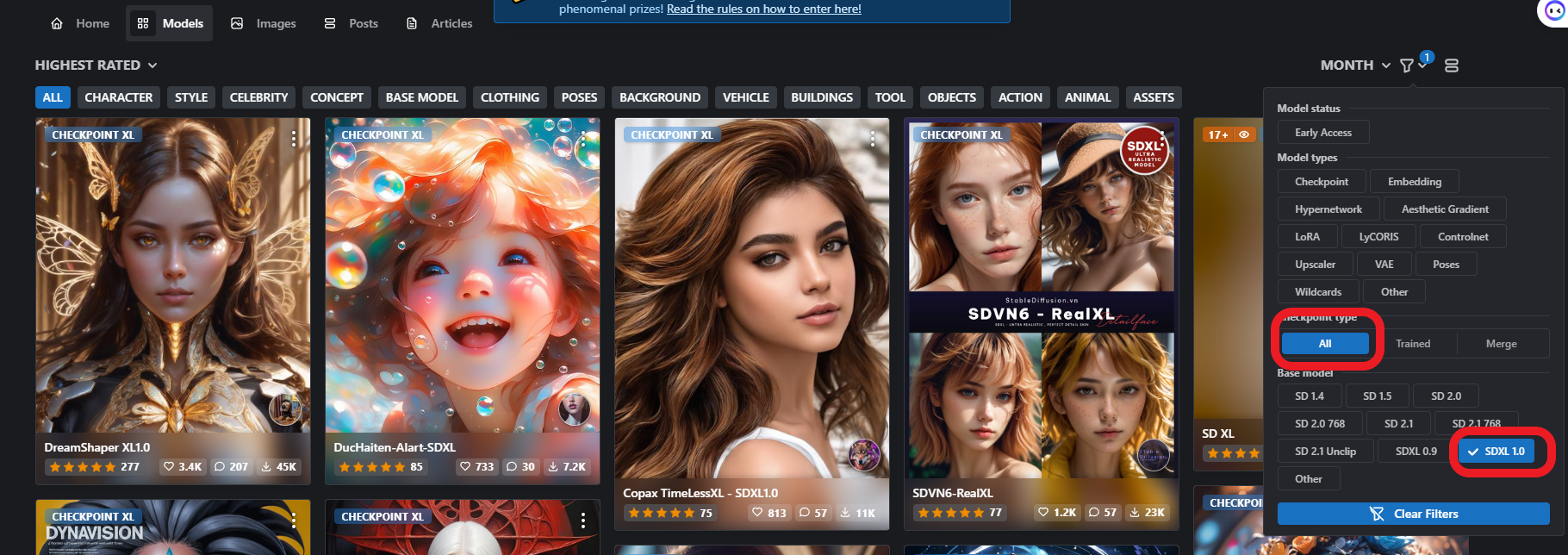
模型选择SDXL 1.0,现在已经有了一些SDXL 1.0的大模型,LORA等等模型了,选一个大模型
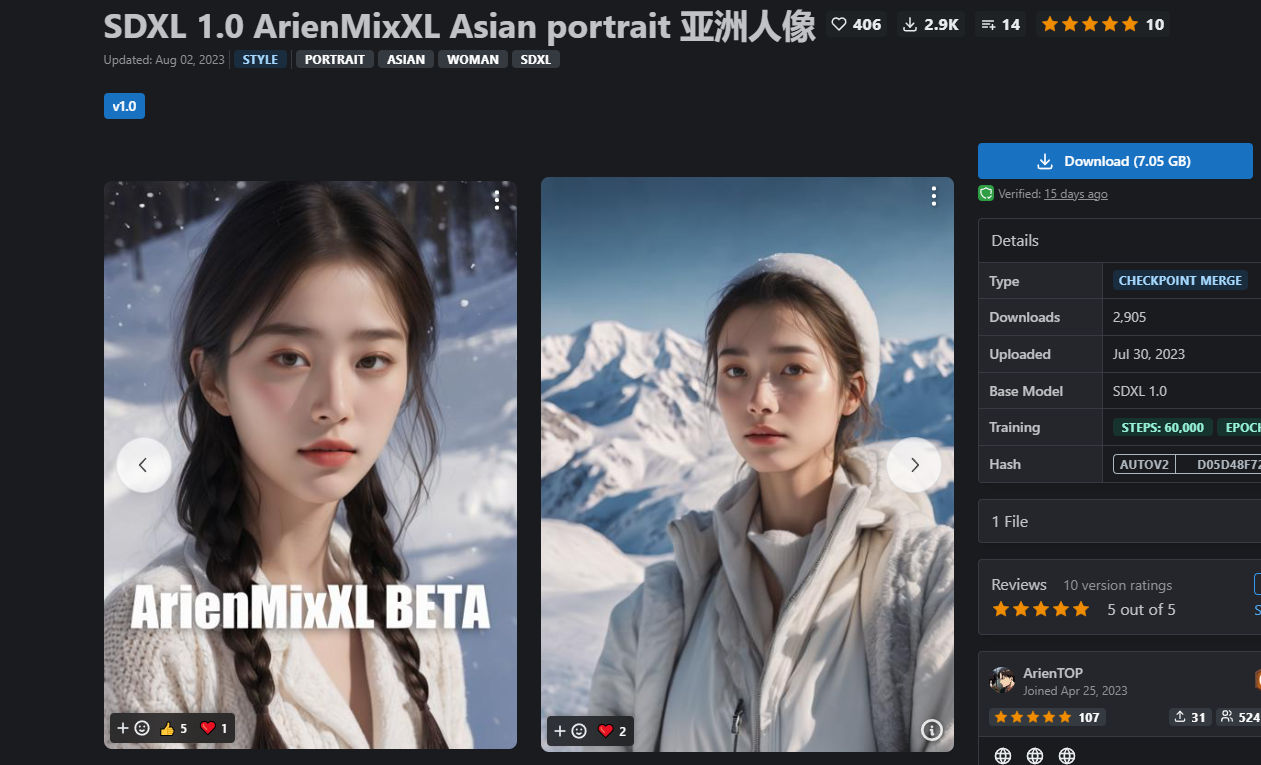
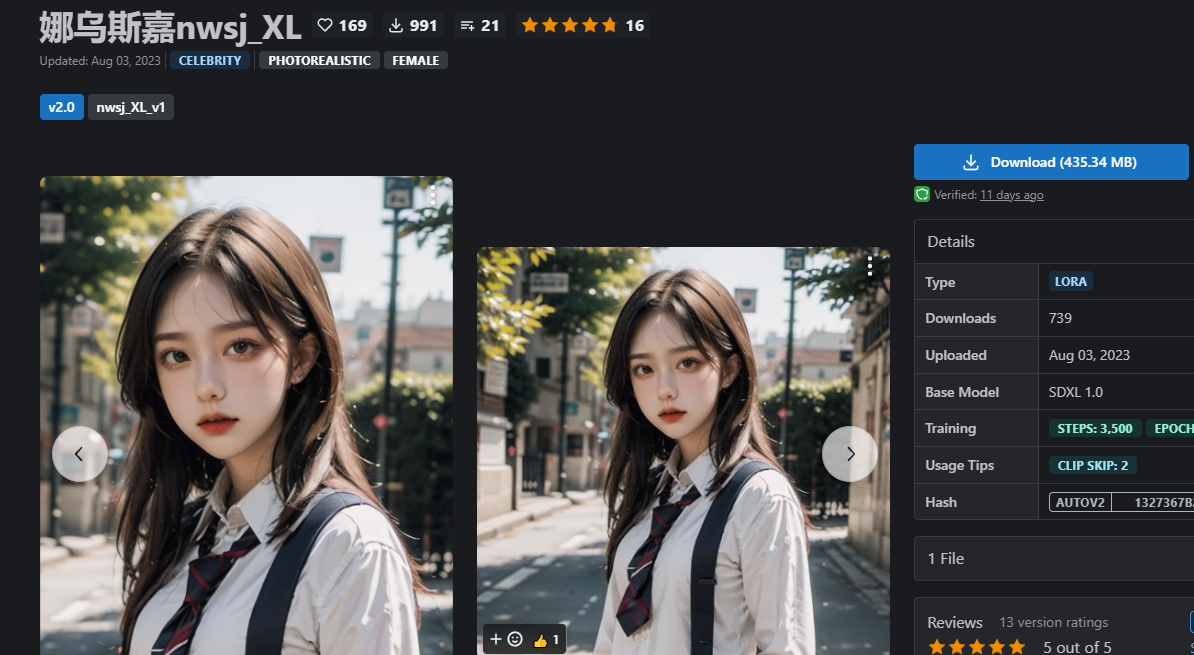
再选一个lora
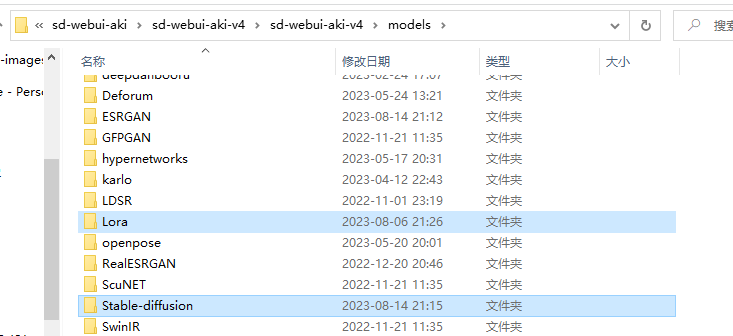
还是和原来一样放入到models目录下的stable diffusion和lora目录中
启动器更新最新版本就不用多说了,显存优化选择8GB以上,不行往下调,改成4GB
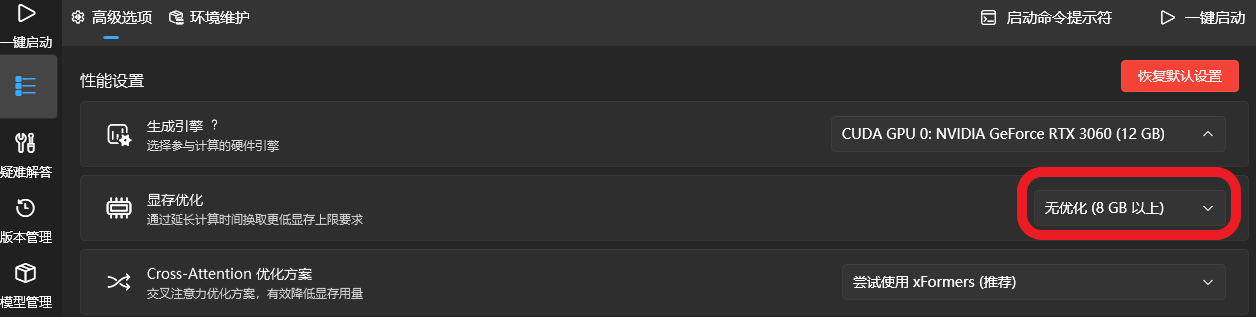
启动,选择SDXL模型,VAE看模型是否提示需要下载,不需要说明融入大模型了,VAE选择none
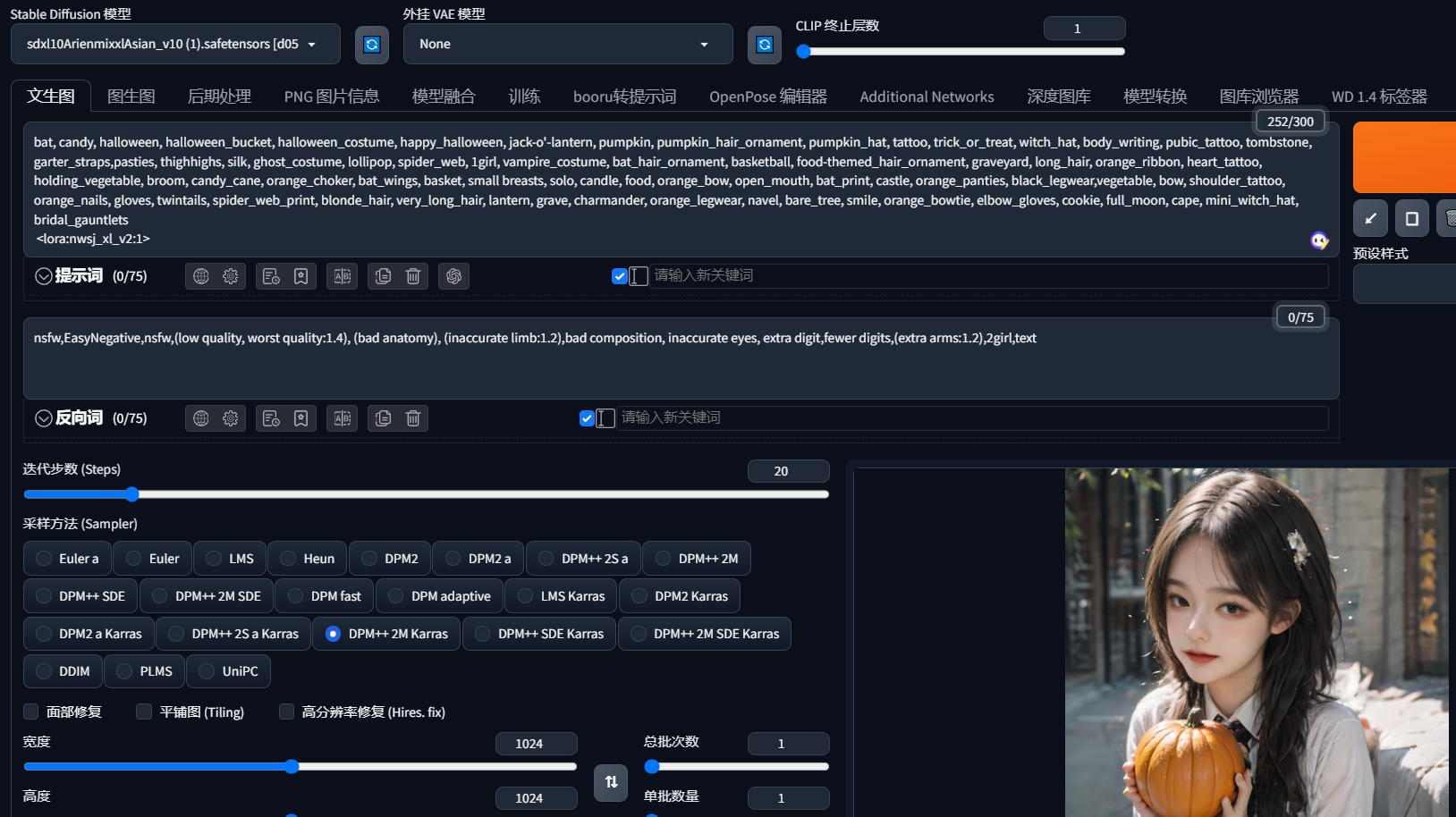
不能选择高分辨率放大,没错,图生图也不行,上面只是简单演示一下,下面介绍具体用法
二、模型下载使用(繁琐版)
https://huggingface.co/stabilityai/stable-diffusion-xl-base-1.0
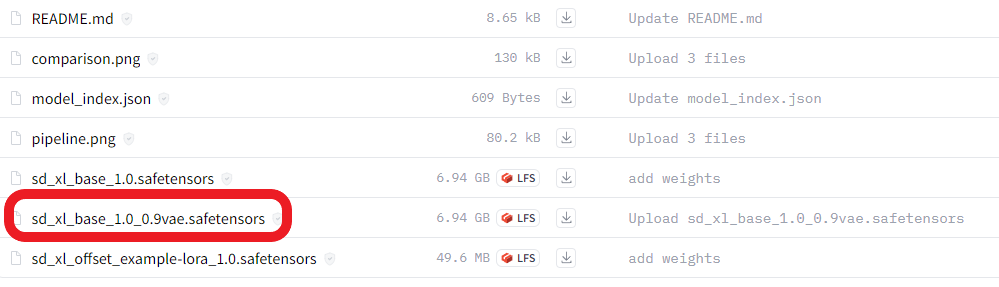
https://huggingface.co/stabilityai/stable-diffusion-xl-refiner-1.0/tree/main
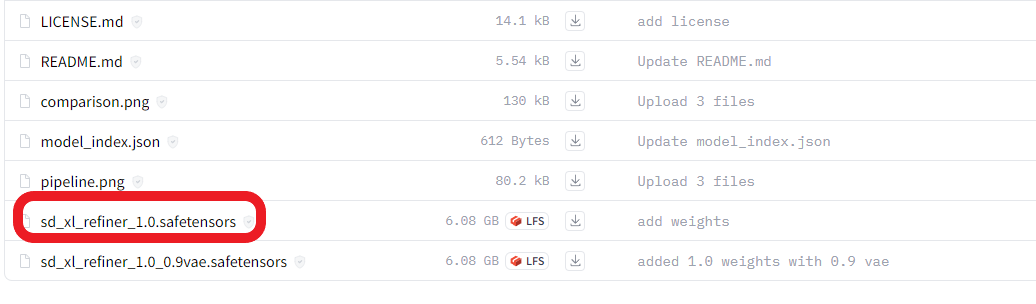
先下载SDXL 1.0base和refiner两个模型(vae修复),放到大模型目录下,生图时VAE选择none,

对比以前的模型数值翻倍了,参数量随之增加,使用了两个clip模型,以往是先把图像经过编码器变成64x64放入潜空间中,现在128x128,出图的尺寸也翻倍了,所以现在的SDXL 1.0都是基于1024x1024训练的,生图尽量不要尺寸小于这个,对于显卡的要求也越来越高了,得有个16G估计才能舒服的玩耍了,8G以下基本弄不了。
运行流程为先使用base模型在文生图生成图像,发送到图生图,然后在图生图切换为refiner模型,在执行一般,反正是比以前繁琐,效果可能也一般,但是前景大,等那些模型爱好者重新基于SDXL炼制一遍,出图效果肯定比今天好的多,而且各方面也会优化,不用像现在这样切换来切换去。不过可以体验一下,等SDXL起来了再加入。
如果出现精度错误,记得把Unet精度关闭半精度优化,可能SDXL不支持半精度。
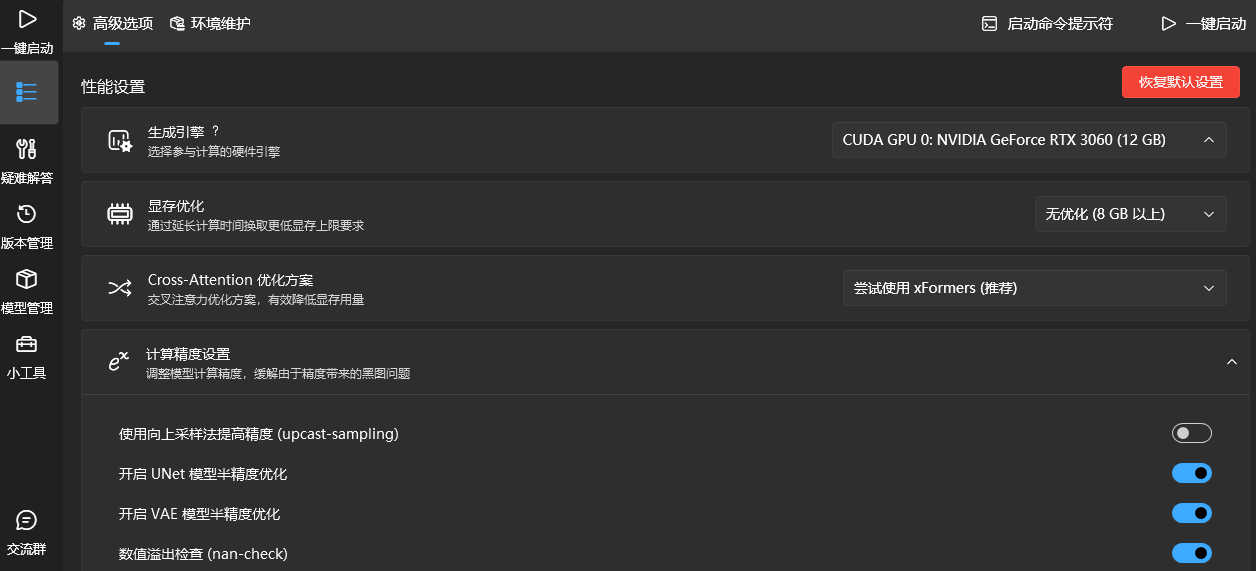
三、ComfyUI
https://github.com/comfyanonymous/ComfyUI
此 UI 将允许您使用基于图形/节点/流程图的界面设计和执行高级稳定扩散管道。它集合webui启动器文生图和图生图的功能,可以理解为之前是在webui上操作,现在在流程图里操作,虽然复杂点,但是生成速度各方面也优化了。而且适用于SD 1.0, 2.0,XL
安装直接在启动器搜索安装就行,重启
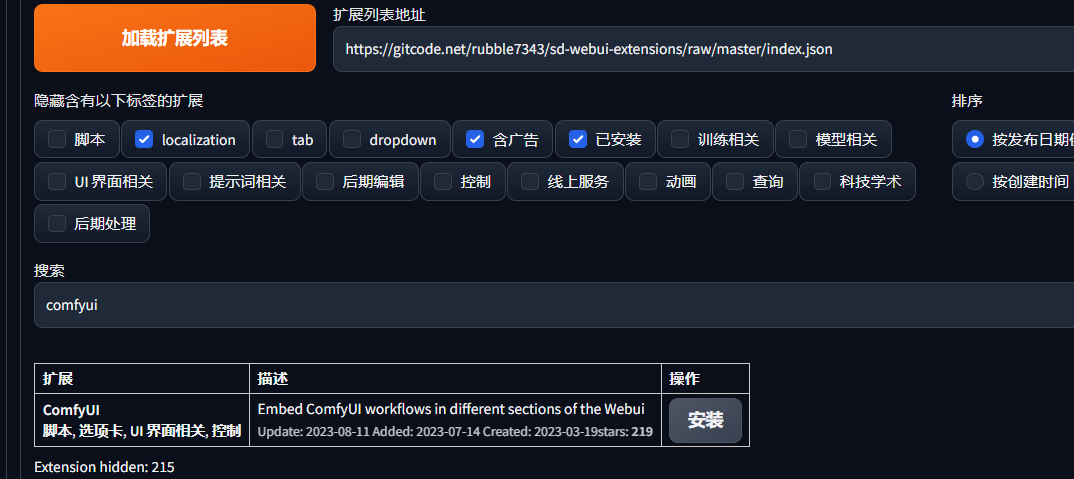
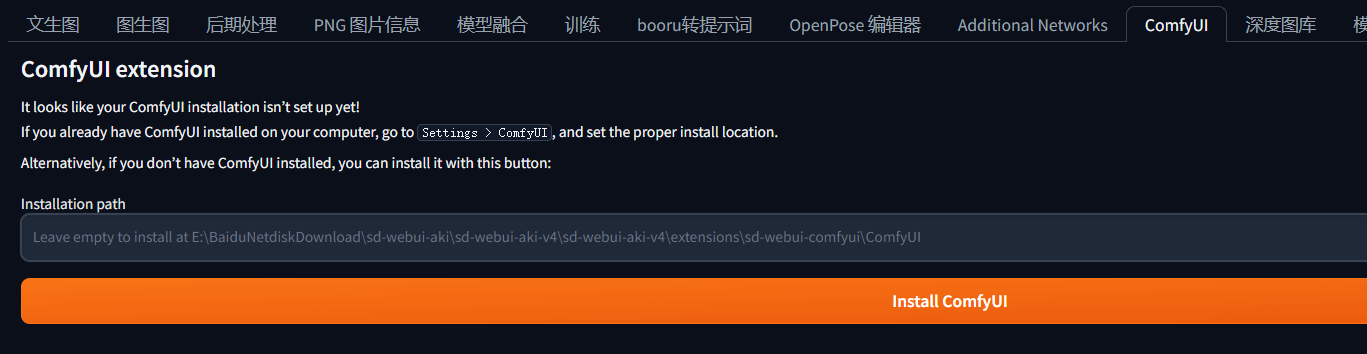
然后点击它,默认安装地址(插件扩展地址),或者自己填写安装地址,点击安装,重启
这就是简化流程图,使用方法最好自己探索下,我会放模版的,直接加载就行不用担心。
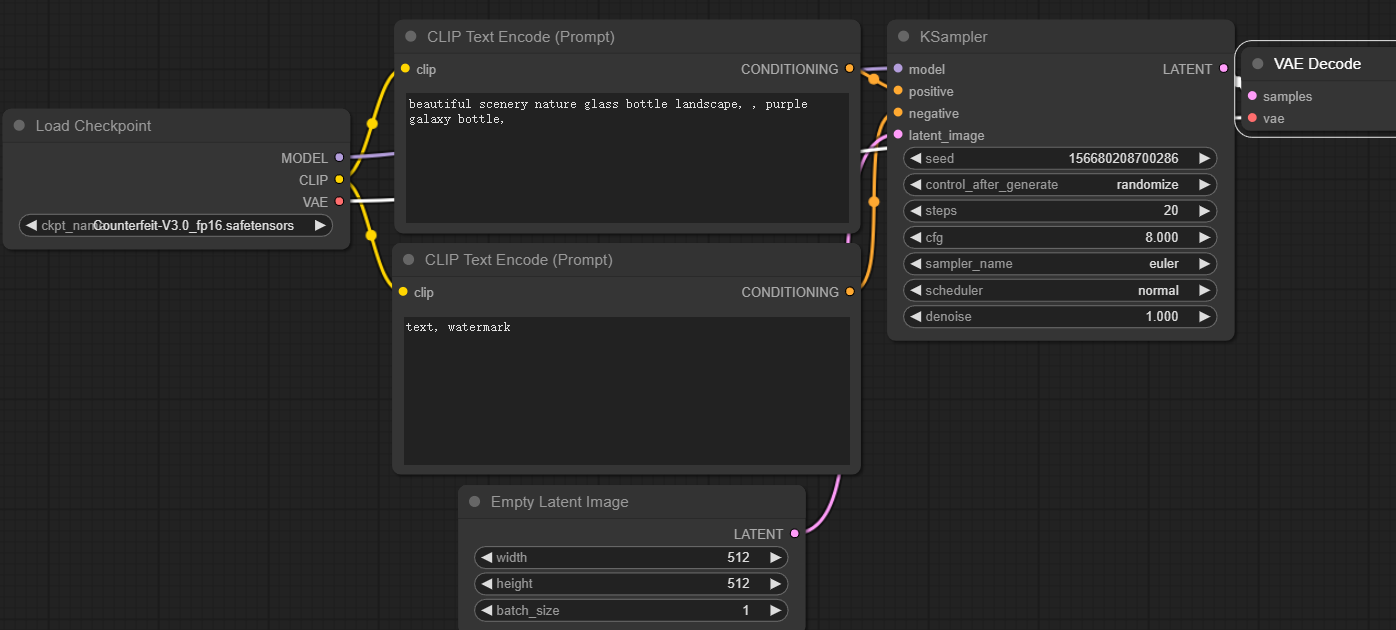
简单介绍使用流程,把你文生图和图生图的流程过一遍,安装流程搭建,譬如建立group,选择大模型,vae,clip,然后是采样器等等,按照顺序搭建,看看我给的模版学学别人怎么搭建的。不学也没事,反正一个模版通用了。workflow下载,解压load就行。
反正体验下来就是卡,不管是内存还是显存都在极限边缘疯狂试探,我的是12G显存,16G内存,感觉内存条需要再加一个8G应该没问题,显存的话16G估计没问题,只能期待模型的优化了,毕竟才刚起步。

