如何学习Presto:糙快猛的大数据之路(建立整体框架)_presto学习
赞
踩
这个系列文章用"粗快猛+大模型问答+讲故事"的创新学习方法,让你轻松理解复杂知识!涵盖Hadoop、Spark、MySQL、Flink等大数据所有热门技术栈,每篇万字长文。时间紧?只看开头20%就能有收获!精彩内容太多?收藏慢慢看!点击链接开启你的大数据学习之旅https://blog.csdn.net/u012955829/category_12733281.html

目录
作为一名大数据开发者,学习新技术是我们工作中不可或缺的一部分。今天,我想和大家分享一下如何高效地学习Presto这个强大的分布式SQL查询引擎。我的学习方法可以概括为"糙快猛"——不追求一步到位的完美,而是在实践中不断进步。让我们开始这段Presto学习之旅吧!
什么是Presto?
在深入学习方法之前,我们先简单了解一下Presto:

Presto是一个开源的分布式SQL查询引擎,最初由Facebook开发,用于针对各种数据源进行交互式分析查询。它的主要特点包括:
- 高性能:能够快速处理PB级数据。
- 灵活性:支持多种数据源,包括Hive、Cassandra、关系数据库等。
- 标准SQL:使用ANSI SQL语法,对于熟悉SQL的开发者来说学习曲线较低。
我的Presto学习故事
还记得我刚开始学习Presto的时候,内心充满了忐忑。作为一个从零基础跨行到大数据领域的开发者,面对Presto这样的分布式系统,我曾一度感到力不从心。
有一天,我偶然听到一句话:"学习就应该糙快猛,不要一下子追求完美,在不完美的状态下前行才是最高效的姿势。"这句话给了我极大的启发。我决定改变学习方式,不再纠结于完美理解每个概念,而是直接上手实践。
糙快猛学习法则

- 粗略了解基本概念
首先,我快速浏览了Presto的官方文档,粗略了解了它的架构和基本概念。比如:
- Coordinator: 负责解析语句、生成执行计划和管理Worker节点
- Worker: 负责执行任务和处理数据
- Connector: 连接各种数据源的接口
- 快速搭建环境
与其花大量时间研究如何完美配置Presto集群,我选择使用Docker快速搭建一个单节点的Presto环境:
docker run -p 8080:8080 --name presto prestosql/presto
- 1
这样,我就能在几分钟内拥有一个可以实践的Presto环境。
- 猛练基本查询
有了环境后,我立即开始练习基本的SQL查询。例如:
-- 创建一个简单的内存表
CREATE TABLE memory.default.users (
id BIGINT,
name VARCHAR,
age INTEGER
);
-- 插入一些数据
INSERT INTO memory.default.users VALUES
(1, 'Alice', 30),
(2, 'Bob', 25),
(3, 'Charlie', 35);
-- 执行查询
SELECT * FROM memory.default.users WHERE age > 28;
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
通过这种方式,我快速熟悉了Presto的基本操作,建立了实践的信心。
迭代提升

在"糙快猛"的基础上,我逐步深入学习:
- 连接实际数据源: 尝试连接Hive、MySQL等实际使用的数据源。
- 优化查询性能: 学习使用EXPLAIN分析查询计划,优化大规模数据查询。
- 深入源码: 阅读关键组件的源代码,理解Presto的内部工作机制。
善用AI助手

在当前的技术环境中,我们有了更强大的学习助手——AI大模型。例如,在学习Presto时,我经常使用ChatGPT来:
- 解释复杂概念
- 生成示例代码
- 模拟真实场景的问题解决
这里有一个使用AI助手学习Presto的例子:
Human: 请解释Presto中的动态过滤(Dynamic Filtering)概念,并给出一个简单的使用示例。
AI: Presto的动态过滤是一种查询优化技术,用于减少在分布式连接操作中处理的数据量。它通过在运行时动态创建过滤条件,将这些条件下推到数据源,从而在早期阶段过滤掉不需要的数据。
这里是一个简单的例子:
假设我们有两张表: orders 和 lineitem
SQL查询:
SELECT o.orderkey, o.totalprice, l.quantity
FROM orders o JOIN lineitem l ON o.orderkey = l.orderkey
WHERE l.quantity > 100
- 1
- 2
- 3
在没有动态过滤的情况下,Presto会先读取整个orders表,然后与lineitem表进行连接。
使用动态过滤后,Presto会:
- 首先扫描lineitem表,找出quantity > 100的orderkey
- 将这些orderkey作为过滤条件应用到orders表的扫描中
- 然后只读取满足条件的orders记录
这样可以显著减少需要处理的数据量,提高查询效率。
要启用动态过滤,可以在Presto配置文件中设置:
dynamic-filtering-enabled=true
- 1
进阶学习策略

在掌握了Presto的基础知识后,是时候采取一些进阶的学习策略了。这里我想分享几个我在学习过程中发现特别有效的方法:
1. 实战项目驱动学习
没有什么比解决实际问题更能促进学习了。我建议你为自己设定一个小项目,比如:
- 使用Presto分析你公司的日志数据
- 构建一个跨多个数据源的报表系统
通过这样的项目,你会遇到各种实际问题,从而深入学习Presto的各种特性。
2. 参与开源社区
Presto有一个活跃的开源社区,参与其中可以极大地促进你的学习:
- 阅读GitHub上的issues和pull requests
- 尝试回答社区中的问题
- 如果可能,提交一些小的bug修复或改进
这不仅能提升你的技术能力,还能建立你在大数据领域的专业网络。
3. 深入理解查询优化
Presto的查询优化是一个深奥但非常重要的话题。我建议你:
- 学习如何读懂和分析EXPLAIN计划
- 理解Presto的成本模型
- 研究常见的查询优化技术,如谓词下推、动态过滤等
这里有一个分析EXPLAIN计划的简单例子:
EXPLAIN (TYPE DISTRIBUTED)
SELECT r.regionkey, n.name, count(*) as count
FROM nation n JOIN region r ON n.regionkey = r.regionkey
GROUP BY r.regionkey, n.name;
- 1
- 2
- 3
- 4
通过分析输出,你可以了解Presto如何分布式地执行这个查询,从而学习如何优化复杂查询。
实际应用案例
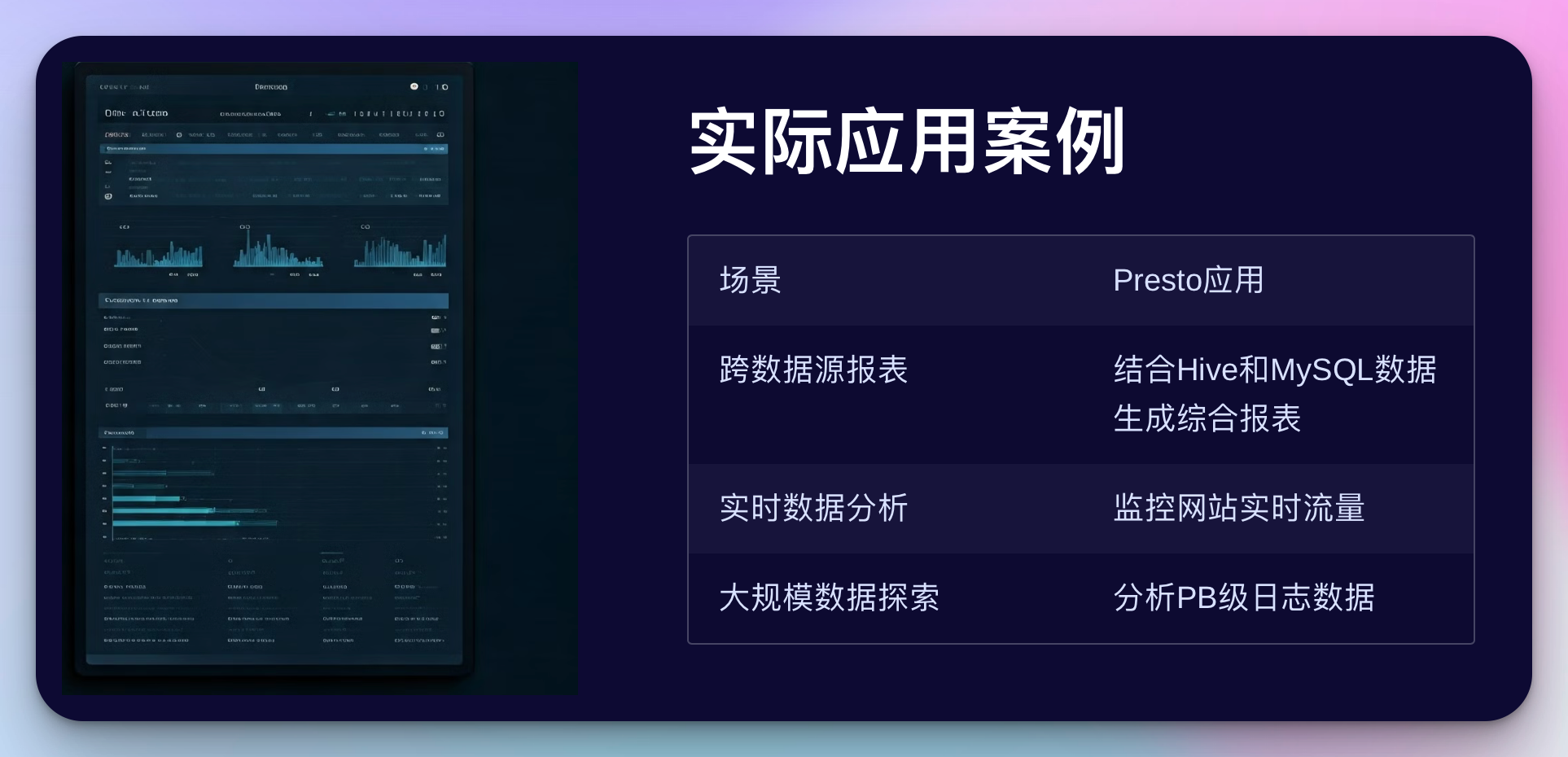
让我们看一个Presto在实际业务中的应用案例,这将帮助你理解Presto如何解决实际问题。
假设你是一家电商公司的大数据开发者,需要分析用户行为和销售数据。你的数据分布在多个系统中:
- 用户行为日志存储在Hive中
- 订单数据在MySQL数据库中
- 产品信息在PostgreSQL中
使用Presto,你可以编写如下查询:
WITH user_behavior AS ( SELECT user_id, count(*) as view_count FROM hive.logs.page_views WHERE date = current_date - interval '1' day GROUP BY user_id ), order_info AS ( SELECT user_id, sum(total_amount) as total_spend FROM mysql.sales.orders WHERE order_date = current_date - interval '1' day GROUP BY user_id ) SELECT u.user_id, p.product_name, u.view_count, o.total_spend FROM user_behavior u JOIN order_info o ON u.user_id = o.user_id JOIN postgresql.inventory.products p ON p.product_id = o.product_id WHERE u.view_count > 10 AND o.total_spend > 1000 ORDER BY o.total_spend DESC LIMIT 100;

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
这个查询跨越了三个不同的数据源,分析了高活跃度且高消费的用户及其购买的产品。通过Presto,你可以在一个查询中完成这种复杂的跨源数据分析,这在传统的数据处理方式中是很难实现的。
个人经验分享
在我的Presto学习之旅中,我犯过不少错误,也收获了很多经验。以下是一些我想和你分享的个人心得:
-
不要害怕犯错:在学习过程中,我经常写出效率低下的查询。但正是通过分析这些"失败",我学会了如何优化查询。
-
持续学习新特性:Presto在不断发展,新版本经常会引入新的特性和优化。保持对新版本的关注,及时学习新特性,这对提升你的Presto技能至关重要。
-
关注性能调优:在实际项目中,查询性能往往是关键。我建议你深入学习Presto的内存管理、worker调度等底层机制,这将帮助你更好地进行性能调优。
-
多与他人交流:无论是与团队成员讨论,还是参加技术会议,交流都能带来新的见解和灵感。我就是在一次技术分享会上学到了"动态分区裁剪"这个重要概念。
高级主题探索
在掌握了Presto的基础知识和一些进阶技巧后,是时候探索一些更高级的主题了。这些主题可能看起来有些复杂,但别忘了我们的"糙快猛"原则——先大致理解,在实践中逐步深入。
1. 自定义函数(UDF)
Presto允许你创建自定义函数,这在处理特定业务逻辑时非常有用。例如,假设我们需要一个函数来计算两个日期之间的工作日数:
CREATE FUNCTION calculate_working_days(start_date DATE, end_date DATE)
RETURNS INTEGER
LANGUAGE JAVA
AS '
long days = ChronoUnit.DAYS.between(start_date, end_date);
long result = days - 2 * (days / 7);
if (start_date.getDayOfWeek() == DayOfWeek.SUNDAY) result--;
if (end_date.getDayOfWeek() == DayOfWeek.SATURDAY) result--;
return (int) result;
'
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
学习创建和使用UDF可以大大提高你的Presto使用效率。
2. 窗口函数的高级应用
窗口函数是Presto中非常强大的特性。让我们看一个复杂一点的例子,假设我们要分析销售数据,计算每个产品在其类别中的销售排名,以及与前一天相比的销售增长:
SELECT
date,
category,
product,
sales,
RANK() OVER (PARTITION BY date, category ORDER BY sales DESC) as rank_in_category,
sales - LAG(sales, 1, 0) OVER (PARTITION BY product ORDER BY date) as sales_growth
FROM
daily_sales
WHERE
date >= current_date - INTERVAL '30' DAY
ORDER BY
date, category, rank_in_category
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
理解和灵活运用这样的复杂查询,可以帮助你解决很多实际业务问题。
3. 查询优化进阶
在之前,我们简单提到了查询优化。现在让我们深入探讨一些具体的优化技巧:
a) 分区裁剪:确保你的查询条件能够利用表的分区信息。例如:
-- 低效查询
SELECT * FROM large_table WHERE date >= DATE '2023-01-01' AND date < DATE '2023-02-01'
-- 优化后的查询
SELECT * FROM large_table WHERE date_partition = '2023-01'
- 1
- 2
- 3
- 4
- 5
b) 谓词下推:尽可能将过滤条件下推到数据源。Presto通常会自动做这个优化,但了解这个概念可以帮助你写出更高效的查询。
c) 避免笛卡尔积:始终提供正确的连接条件,避免产生大量中间结果。
d) 使用近似函数:对于大规模数据,使用approx_distinct()代替COUNT(DISTINCT)可以显著提升性能。
4. Presto的内存管理
理解Presto如何管理内存对于调优大规模查询至关重要。以下是一些关键概念:
-
内存池:Presto使用不同的内存池来管理查询执行。了解
general、reserved和system池的作用可以帮助你更好地配置Presto。 -
内存不足处理:当查询使用的内存超过限制时,Presto会如何处理?了解这一点可以帮助你设计更可靠的查询。
实战案例:构建实时数据仪表板
让我们通过一个实际的项目案例来整合我们学到的知识。假设我们要为一个大型电商平台构建一个实时的销售数据仪表板。
-
数据源设置:
- 实时订单数据存储在Kafka中
- 历史订单数据存储在Hive中
- 产品和用户信息存储在MySQL中
-
Presto配置:
- 设置Kafka连接器以读取实时数据
- 配置Hive和MySQL连接器
-
查询设计:
WITH real_time_orders AS ( SELECT product_id, COUNT(*) as order_count, SUM(amount) as total_amount FROM kafka.sales.orders WHERE event_time >= current_timestamp - INTERVAL '5' MINUTE GROUP BY product_id ), historical_summary AS ( SELECT product_id, AVG(daily_order_count) as avg_daily_orders, AVG(daily_total_amount) as avg_daily_amount FROM hive.sales.daily_summary WHERE date >= current_date - INTERVAL '30' DAY GROUP BY product_id ) SELECT r.product_id, p.product_name, p.category, r.order_count as real_time_orders, r.total_amount as real_time_amount, h.avg_daily_orders, h.avg_daily_amount, (r.order_count / h.avg_daily_orders) as order_ratio, (r.total_amount / h.avg_daily_amount) as amount_ratio FROM real_time_orders r JOIN historical_summary h ON r.product_id = h.product_id JOIN mysql.products.info p ON r.product_id = p.id ORDER BY r.total_amount DESC LIMIT 100
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
这个查询综合了我们前面学到的多个概念:
- 使用CTE进行复杂查询结构化
- 跨多个数据源的查询
- 时间窗口计算
- 聚合和连接操作
-
性能优化:
- 使用适当的分区策略(例如,Hive表按日期分区)
- 为MySQL表的连接键创建适当的索引
- 监控查询性能,必要时使用EXPLAIN进行分析和优化
-
部署和监控:
- 将查询嵌入到你的应用程序或BI工具中
- 设置Presto的监控,关注查询延迟、内存使用等指标
通过这个实战案例,你不仅能够将学到的Presto知识付诸实践,还能解决实际的业务问题,这正是"糙快猛"学习方法的精髓所在。
持续学习与成长
学习Presto是一个持续的过程。技术在不断发展,Presto也在不断推出新的特性。以下是一些保持学习的建议:
-
关注Presto的官方博客和发布说明:这是了解新特性和改进的最佳途径。
-
参与Presto社区:订阅邮件列表,参与讨论,这能让你始终保持在技术前沿。
-
实验新特性:当Presto发布新版本时,尝试在测试环境中使用新特性,评估它们如何能够帮助你解决实际问题。
-
分享你的经验:写博客、做技术分享。教是最好的学!
-
关注相关技术:Presto不是孤立的。了解诸如Spark、Flink等其他大数据技术,可以帮助你更全面地理解Presto在整个生态系统中的位置。
Presto的高级特性与优化

在掌握了Presto的基础知识和一些进阶技巧后,让我们深入探讨一些更高级的特性和优化技巧。记住,即使是复杂的主题,我们也要保持"糙快猛"的学习态度——先理解核心概念,然后在实践中逐步掌握细节。
1. 动态过滤(Dynamic Filtering)
动态过滤是Presto的一个强大特性,它可以显著提高某些类型查询的性能。让我们通过一个例子来理解它:
SELECT customer.name, orders.order_date
FROM customer
JOIN orders ON customer.id = orders.customer_id
WHERE orders.total_price > 1000
- 1
- 2
- 3
- 4
在没有动态过滤的情况下,Presto会先扫描整个customer表,然后再与orders表进行连接。但有了动态过滤,Presto会:
- 首先扫描orders表,找出total_price > 1000的customer_id
- 使用这些customer_id作为过滤条件来扫描customer表
这样可以大大减少需要处理的数据量。要启用动态过滤,你需要在配置文件中设置:
dynamic-filtering-enabled=true
- 1
2. 查询优化器(Cost-Based Optimizer)
Presto的成本优化器(CBO)是一个复杂但强大的特性。它使用统计信息来选择最优的查询执行计划。要充分利用CBO,你需要:
- 确保你的表有最新的统计信息
- 理解并使用EXPLAIN ANALYZE来查看查询计划
例如,你可以这样分析一个查询:
EXPLAIN ANALYZE
SELECT r.regionkey, n.name, count(*) as count
FROM nation n JOIN region r ON n.regionkey = r.regionkey
GROUP BY r.regionkey, n.name;
- 1
- 2
- 3
- 4
这会显示查询的执行计划,包括每个操作的估计成本和实际执行时间。通过分析这些信息,你可以找出查询的瓶颈并进行优化。
3. 分布式联接优化
在处理大规模数据时,联接操作往往是性能瓶颈。Presto提供了几种分布式联接策略:
- 广播联接(Broadcast Join)
- 分区联接(Partitioned Join)
- 带缓存的广播联接(Cached Broadcast Join)
理解这些策略并知道何时使用它们可以大大提高查询性能。例如,当一个表很小时,使用广播联接通常是个好选择:
SELECT /*+ BROADCAST(small_table) */ *
FROM large_table l
JOIN small_table s ON l.id = s.id
- 1
- 2
- 3
这个提示告诉Presto将small_table广播到所有节点,从而避免了数据重分布的开销。
Presto的扩展性与集成
Presto的一大优势是其强大的扩展性和与其他系统的集成能力。让我们探讨一下如何利用这些特性。
1. 自定义连接器
虽然Presto已经提供了许多内置连接器,但有时你可能需要连接到一个特殊的数据源。这时,你可以考虑开发自定义连接器。以下是开发自定义连接器的基本步骤:
- 实现SPI接口(如ConnectorFactory, Connector, ConnectorSplit等)
- 实现数据读取逻辑
- 打包并部署你的连接器
例如,假设你要为一个自定义的NoSQL数据库创建连接器,你可能需要实现如下接口:
public class MyNoSQLConnector implements Connector {
@Override
public ConnectorTransactionHandle beginTransaction(IsolationLevel isolationLevel, boolean readOnly) {
// Implementation
}
@Override
public ConnectorMetadata getMetadata(ConnectorTransactionHandle transaction) {
// Implementation
}
// Other methods...
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
2. 与Spark生态系统的集成
很多组织同时使用Presto和Spark。理解如何集成这两个系统可以让你充分利用它们各自的优势。例如:
-
使用Presto查询Spark生成的数据:
SELECT * FROM hive.spark_generated_table WHERE date = '2023-07-25'- 1
-
在Spark中使用Presto作为数据源:
val df = spark.read .format("jdbc") .option("url", "jdbc:presto://localhost:8080") .option("dbtable", "hive.default.my_table") .load()- 1
- 2
- 3
- 4
- 5
性能调优与故障排除
在实际工作中,你可能会遇到各种性能问题和错误。以下是一些常见问题及其解决方法:
1. 内存管理问题
如果你经常遇到"Query exceeded per-node user memory limit"错误,你可以:
- 增加每个查询的内存限制:
query.max-memory-per-node=1GB
- 1
-
使用
EXPLAIN ANALYZE查看查询的内存使用情况,找出内存密集型操作。 -
考虑重写查询,例如使用窗口函数代替自连接。
2. 数据倾斜
数据倾斜可能导致某些任务执行时间过长。解决方法包括:
-
使用合适的分区键
-
在join操作中使用倾斜键处理:
SELECT /*+ SHUFFLE_REPLICATE_NL(s) */ * FROM large_skewed_table l JOIN small_table s ON l.skewed_key = s.id- 1
- 2
- 3
-
在聚合操作中使用两阶段聚合:
WITH pre_aggregated AS ( SELECT key, COUNT(*) as count FROM large_table GROUP BY key ) SELECT key, SUM(count) FROM pre_aggregated GROUP BY key- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
未来趋势与持续学习
Presto技术栈在不断发展,了解未来趋势对于保持技术领先很重要。以下是一些值得关注的方向:
-
Presto对机器学习的支持:随着机器学习在大数据领域的应用越来越广泛,Presto也在增强对ML工作负载的支持。
-
实时分析能力的增强:Presto正在不断优化其实时查询能力,未来可能会看到更多针对流数据的功能。
-
云原生集成:随着云计算的普及,Presto在云环境中的部署和优化将成为重要话题。
-
联邦查询能力的增强:随着数据源的多样化,Presto在跨多个异构数据源的查询能力上可能会有更多改进。
要跟上这些趋势,你可以:
- 定期查看Presto官方博客和GitHub仓库
- 参加相关的技术会议和网络研讨会
- 在实际项目中尝试新特性,并与社区分享你的经验
Presto在实际工作中的应用场景
学习Presto的理论知识固然重要,但将其应用到实际工作中才是我们的最终目标。让我们探讨一些Presto在实际工作中的常见应用场景,以及如何利用Presto来解决这些场景中的问题。
1. 跨数据源的报表生成
在大型企业中,数据通常分散在多个系统中。例如,交易数据可能存储在Hive中,而客户信息可能存在MySQL数据库中。Presto的强大之处在于它可以无缝地查询这些不同的数据源。
WITH transaction_summary AS ( SELECT customer_id, COUNT(*) as transaction_count, SUM(amount) as total_spend FROM hive.transactions.sales WHERE transaction_date >= DATE '2023-01-01' GROUP BY customer_id ) SELECT c.customer_name, c.customer_segment, t.transaction_count, t.total_spend, t.total_spend / t.transaction_count as avg_transaction_value FROM transaction_summary t JOIN mysql.crm.customer_info c ON t.customer_id = c.id ORDER BY t.total_spend DESC LIMIT 100
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
这个查询结合了存储在Hive中的交易数据和MySQL中的客户信息,生成了一个综合报表。
2. 实时数据分析
Presto的低延迟特性使它非常适合进行实时数据分析。例如,我们可以使用Presto来监控网站的实时流量:
SELECT
url_path,
COUNT(*) as view_count,
COUNT(DISTINCT user_id) as unique_visitors,
AVG(response_time) as avg_response_time
FROM
kafka.website_logs.page_views
WHERE
event_time >= CURRENT_TIMESTAMP - INTERVAL '5' MINUTE
GROUP BY
url_path
ORDER BY
view_count DESC
LIMIT 10
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
这个查询可以实时显示过去5分钟内网站各页面的访问情况。
3. 大规模数据探索
当面对PB级别的数据时,Presto的分布式查询能力就显得尤为重要。例如,我们可以使用Presto来分析大规模的日志数据:
WITH daily_stats AS ( SELECT DATE(timestamp) as date, COUNT(*) as total_logs, COUNT(DISTINCT user_id) as unique_users, SUM(CASE WHEN status_code >= 500 THEN 1 ELSE 0 END) as error_count FROM hive.logs.application_logs WHERE timestamp >= DATE '2023-01-01' GROUP BY DATE(timestamp) ) SELECT date, total_logs, unique_users, error_count, (error_count * 100.0 / total_logs) as error_rate FROM daily_stats ORDER BY date
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
这个查询可以快速分析大量的日志数据,提取出每天的关键指标。
Presto最佳实践
在使用Presto的过程中,我们总结了一些最佳实践,可以帮助你更高效地使用Presto:
1. 合理使用分区
对于大表,合理的分区策略可以显著提高查询性能:
CREATE TABLE hive.sales.transactions (
transaction_id BIGINT,
customer_id BIGINT,
product_id BIGINT,
amount DECIMAL(10, 2),
transaction_date DATE
)
WITH (
format = 'ORC',
partitioned_by = ARRAY['transaction_date']
)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
在查询时,确保使用分区列作为过滤条件:
SELECT *
FROM hive.sales.transactions
WHERE transaction_date >= DATE '2023-07-01'
AND transaction_date < DATE '2023-08-01'
- 1
- 2
- 3
- 4
2. 使用近似函数
当处理大规模数据时,使用近似函数可以大大提高查询速度,同时保持结果的准确性在可接受范围内:
-- 使用精确的COUNT(DISTINCT)
SELECT COUNT(DISTINCT user_id) FROM web_logs
-- 使用近似函数
SELECT approx_distinct(user_id) FROM web_logs
- 1
- 2
- 3
- 4
- 5
3. 合理设置资源限制
为了防止单个查询占用过多资源,可以在会话级别设置资源限制:
SET SESSION query_max_execution_time = '30m';
SET SESSION query_max_memory = '100GB';
- 1
- 2
4. 使用EXPLAIN分析查询计划
在执行复杂查询之前,使用EXPLAIN来分析查询计划可以帮助你找出潜在的性能问题:
EXPLAIN ANALYZE
SELECT customer_id, SUM(amount)
FROM hive.sales.transactions
WHERE transaction_date >= DATE '2023-01-01'
GROUP BY customer_id
- 1
- 2
- 3
- 4
- 5
常见陷阱和解决方法

在使用Presto的过程中,你可能会遇到一些常见的问题。以下是一些典型的陷阱和相应的解决方法:
1. OOM(Out of Memory)错误
问题:执行大查询时遇到OOM错误。
解决方法:
- 增加查询的内存限制
- 优化查询,减少内存使用
- 考虑使用近似函数
- 对于很大的结果集,考虑使用分页查询
2. 查询超时
问题:长时间运行的查询被系统终止。
解决方法:
- 增加查询超时时间
- 优化查询,减少数据扫描量
- 考虑将大查询拆分成多个小查询
3. 数据一致性问题
问题:查询结果与预期不符。
解决方法:
- 检查数据源的一致性
- 确保使用了正确的连接条件
- 注意不同数据源之间的时区差异
4. 性能突然下降
问题:之前运行良好的查询突然变慢。
解决方法:
- 检查数据量是否显著增加
- 查看集群资源使用情况
- 重新收集表统计信息
- 检查是否有其他大查询正在运行
高级优化技巧
对于那些已经熟练使用Presto的开发者,这里有一些高级优化技巧可以进一步提升查询性能:
1. 使用物化视图
对于经常执行的复杂查询,可以考虑创建物化视图:
CREATE MATERIALIZED VIEW daily_sales_summary AS
SELECT
DATE(transaction_date) as date,
product_id,
SUM(amount) as total_sales,
COUNT(*) as transaction_count
FROM
hive.sales.transactions
GROUP BY
DATE(transaction_date), product_id
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
2. 优化JOIN顺序
Presto的查询优化器通常能选择最优的JOIN顺序,但在某些复杂情况下,手动指定JOIN顺序可能会有帮助:
SELECT /*+ JOIN_REORDER(a, b, c) */ *
FROM a JOIN b ON a.id = b.id JOIN c ON b.id = c.id
- 1
- 2
3. 使用窗口函数优化复杂查询
窗口函数可以帮助优化一些复杂的分析查询:
SELECT
customer_id,
transaction_date,
amount,
SUM(amount) OVER (
PARTITION BY customer_id
ORDER BY transaction_date
ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW
) as cumulative_spend
FROM
hive.sales.transactions
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
结语

Presto是一个强大而复杂的工具,掌握它需要时间和实践。但正如我们的"糙快猛"学习方法所强调的,关键是要开始行动,在实践中学习和成长。
从基本的SQL查询到复杂的性能优化,从简单的数据分析到跨源的大规模数据处理,Presto为我们提供了强大的能力来应对各种数据挑战。
记住,每个专家都是从新手开始的。在你的Presto学习之旅中,不要害怕犯错,因为每个错误都是一次学习的机会。保持好奇心,勇于尝试新的查询和优化技术,并且要经常与社区交流,分享你的经验和问题。
最后,希望这篇文章能够成为你学习和使用Presto的有用指南。无论你是刚开始接触Presto,还是想要提升自己的技能,我相信这里的内容都能给你一些启发。记住,学习是一个持续的过程,让我们一起在Presto的世界里不断探索,不断成长!
祝你在Presto的学习和使用过程中收获满满,早日成为大数据领域的专家!
思维导图