
- 1Kompas AI用户体验与界面设计对比
- 2计算机毕业设计项目推荐,社区医疗服务小程序 38272(开题答辩+程序定制+全套文案 )上万套实战教程手把手教学JAVA、PHP,node.js,C++、python、大屏
- 3C++ —— 单机软件加入Licence许可权限流程(附详细流程图、详细代码已持续更新..)_c++ license 加密
- 4IntelliJ IDEA 常用快捷键_idea删除整行快捷键设置
- 5什么是开源什么是闭源?以及它们之间的关系_开源与闭源
- 6大数据_Hive_大数据hive
- 72021.8.1头条_signature分析(后续)_头条爬虫signature
- 8(防火墙USG6000V)双向NAT详解_防火墙双向nat配置案例
- 9linux进程间的7种通信方式全解析及代码示例_linux进程间通信
- 10Spring Boot与RabbitMQ:消息队列在微服务中的应用_springboot rabbitmq实际项目中用途
警惕 Python 中少为人知的十个安全陷阱(1)_python编程常见陷阱
赞
踩
def touch_tmp_file(request):
id = request.GET[‘id’]
tmp_file = tempfile.NamedTemporaryFile(prefix=id)
return HttpResponse(f"tmp file: {tmp_file} created!",
content_type=‘text/plain’)
在第 3 行中,用户输入的 id 被当作临时文件的前缀。如果攻击者传入的 id
参数是“/…/var/www/test”,则会创建出这样的临时文件:/var/www/test_zdllj17。粗看起来,这可能是无害的,但它会为攻击者创造出挖掘更复杂的漏洞的基础。
5. 扩展的 Zip Slip
在 Web 应用中,通常需要解压上传后的压缩文件。在 Python 中,很多人都知道 TarFile.extractall 与
TarFile.extract 函数容易受到 Zip Slip 攻击。攻击者通过篡改压缩包中的文件名,使其包含路径遍历(…/)字符,从而发起攻击。
这就是为什么压缩文件应该始终被视为不受信来源的原因。zipfile.extractall 与 zipfile.extract 函数可以对 zip
内容进行清洗,从而防止这类路径遍历漏洞。
但是,这并不意味着在 ZipFile 库中不会出现路径遍历漏洞。下面是一段解压缩文件的代码。
def extract_html(request):
filename = request.FILES[‘filename’]
zf = zipfile.ZipFile(filename.temporary_file_path(), “r”)
for entry in zf.namelist():
if entry.endswith(“.html”):
file_content = zf.read(entry)
with open(entry, “wb”) as fp:
fp.write(file_content)
zf.close()
return HttpResponse(“HTML files extracted!”)
第 3 行代码根据用户上传文件的临时路径,创建出一个 ZipFile 处理器。第 4 - 8 行代码将所有以“.html”结尾的压缩项提取出来。第 4
行中的 zf.namelist 函数会取到 zip 内压缩项的名称。注意,只有 zipfile.extract 与 zipfile.extractall
函数会对压缩项进行清洗,其它任何函数都不会。
在这种情况下,攻击者可以创建一个文件名,例如“…/…/…/var/www/html”,内容随意填。该恶意文件的内容会在第 6 行被读取,并在第 7-8
行写入被攻击者控制的路径。因此,攻击者可以在整个服务器上创建任意的 HTML 文件。
如上所述,压缩包中的文件应该被看作是不受信任的。如果你不使用 zipfile.extractall 或者 zipfile.extract,你就必须对 zip
内文件的名称进行“消毒”,例如使用 os.path.basename。否则,它可能导致严重的安全漏洞,就像在 NLTK Downloader
(CVE-2019-14751)中发现的那样。
6. 不完整的正则表达式匹配
正则表达式(regex)是大多数 Web 程序不可或缺的一部分。我们经常能看到它被自定义的 Web 应用防火墙(WAF,Web Application
Firewalls)用来作输入验证,例如检测恶意字符串。在 Python 中,re.match 和 re.search
之间有着细微的区别,我们将在下面的代码片段中演示。
def is_sql_injection(request):
pattern = re.compile(r".(union)|(select). ")
name_to_test = request.GET[‘name’]
if re.search(pattern, name_to_test):
return True
return False
在第 2 行中,我们定义了一个匹配 union 或者 select 的模式,以检测可能的 SQL
注入。这是一个糟糕的写法,因为你可以轻易地绕过这些黑名单,但我们已经在线上的程序中见过它。在第 4 行中,函数 re.match
使用前面定义好的模式,检查第 3 行中的用户输入内容是否包含这些恶意的值。
然而,与 re.search 函数不同的是,re.match 函数不匹配新行。例如,如果攻击者提交了值 aaaaaa \n union
select,这个输入就匹配不上正则表达式。因此,检查可以被绕过,失去保护作用。
总而言之,我们不建议使用正则表达式黑名单进行任何安全检查。
7. Unicode 清洗器绕过
Unicode 支持用多种形式来表示字符,并将这些字符映射到码点。在 Unicode 标准中,不同的 Unicode
字符有四种归一化方案。程序可以使用这些归一化方法,以独立于人类语言的标准方式来存储数据,例如用户名。
然而,攻击者可以利用这些归一化,这已经导致了 Python 的 urllib 出现漏洞(CVE-2019-9636)。下面的代码片段演示了一个基于 NFKC
归一化的跨站点脚本漏洞(XSS,Cross-Site Scripting)。
import unicodedata
from django.shortcuts import render
from django.utils.html import escape
def render_input(request):
user_input = escape(request.GET[‘p’])
normalized_user_input = unicodedata.normalize(“NFKC”, user_input)
context = {‘my_input’: normalized_user_input}
return render(request, ‘test.html’, context)
在第 6 行中,用户输入的内容被 Django 的 escape 函数处理了,以防止 XSS 漏洞。在第 7 行中,经过清洗的输入被 NFKC
算法归一化,以便在第 8-9 行中通过 test.html 模板正确地渲染。
templates/test.html:
{{ my_input | safe}}
在模板 test.html 中,第 4 行的变量 my_input 被标记为安全的,因为开发人员预期有特殊字符,并且认为该变量已经被 escape
函数清洗了。通过标记关键字 safe, Django 不会再次对变量进行清洗。
但是,由于第 7 行(view.py)的归一化,字符“%EF%B9%A4”会被转换为“<”,“%EF%B9%A5”被转换为“>”。这导致攻击者可以注入任意的
HTML 标记,进而触发 XSS 漏洞。为了防止这个漏洞,就应该在把用户输入做完归一化之后,再进行清洗。
8. Unicode 编码碰撞
前文说过,Unicode 字符会被映射成码点。然而,有许多不同的人类语言,Unicode
试图将它们统一起来。这就意味着不同的字符很有可能拥有相同的“layout”。例如,小写的土耳其语 ı(没有点)的字符是英语中大写的 I。在拉丁字母中,字符
i 也是用大写的 I 表示。在 Unicode 标准中,这两个不同的字符都以大写形式映射到同一个码点。
这种行为是可以被利用的,实际上已经在 Django 中导致了一个严重的漏洞(CVE-2019-19844)。下面的代码是一个重置密码的示例。
from django.core.mail import send_mail
from django.http import HttpResponse
from vuln.models import User
def reset_pw(request):
email = request.GET[‘email’]
result = User.objects.filter(email__exact=email.upper()).first()
if not result:
return HttpResponse(“User not found!”)
send_mail(‘Reset Password’,‘Your new pw: 123456.’, ‘from@example.com’,
[email], fail_silently=False)
return HttpResponse(“Password reset email send!”)
第 6 行代码获取了用户输入的 email,第 7-9 行代码检查这个 email 值,查找是否存在具有该 email 的用户。如果用户存在,则第 10
行代码依据第 6 行中输入的 email 地址,给用户发送邮件。需要指出的是,第 7-9 行中对邮件地址的检查是不区分大小写的,使用了 upper 函数。
至于攻击,我们假设数据库中存在一个邮箱地址为 foo@mix.com 的用户。那么,攻击者可以简单地传入 foo@mıx.com 作为第 6 行中的
email,其中 i 被替换为土耳其语 ı。第 7 行代码将邮箱转换成大写,结果是
FOO@MIX.COM。这意味着找到了一个用户,因此会发送一封重置密码的邮件。
然而,邮件被发送到第 6 行未转换的邮件地址,也就是包含了土耳其语的 ı。换句话说,其他用户的密码被发送到了攻击者控制的邮件地址。为了防止这个漏洞,可以将第
10 行替换成使用数据库中的用户邮箱。即使发生编码冲突,攻击者在这种情况下也得不到任何好处。
9. IP 地址归一化
在 Python < 3.8 中,IP 地址会被 ipaddress 库归一化,因此前缀的零会被删除。这种行为乍一看可能是无害的,但它已经在 Django
中导致了一个高严重性的漏洞(CVE-2021-33571)。攻击者可以利用归一化绕过校验程序,发起服务端请求伪造攻击(SSRF,Server-Side
Request Forgery)。
下面的代码展示了如何绕过这样的校验器。
import requests
import ipaddress
def send_request(request):
ip = request.GET[‘ip’]
try:
if ip in [“127.0.0.1”, “0.0.0.0”]:
return HttpResponse(“Not allowed!”)
ip = str(ipaddress.IPv4Address(ip))
except ipaddress.AddressValueError:
return HttpResponse(“Error at validation!”)
requests.get(‘https://’ + ip)
return HttpResponse(“Request send!”)
第 5 行代码获取用户传入的一个 IP 地址,第 7 行代码使用一个黑名单来检查该 IP 是否为本地地址,以防止可能的 SSRF
漏洞。这份黑名单并不完整,仅作为示例。
第 9 行代码检查该 IP 是否为 IPv4 地址,同时将 IP 归一化。在完成验证后,第 12 行代码会对该 IP 发起实际的请求。
但是,攻击者可以传入 127.0.001 这样的 IP 地址,在第 7 行的黑名单列表中找不到。然后,第 9 行代码使用
ipaddress.IPv4Address 将 IP 归一化为 127.0.0.1。因此,攻击者就能够绕过 SSRF 校验器,并向本地网络地址发送请求。
10. URL 查询参数解析
在 Python < 3.7 中,urllib.parse.parse_qsl 函数允许使用“;”和“&”字符作为 URL
的查询变量的分隔符。有趣的是“;”字符不能被其它语言识别为分隔符。
在下面的例子中,我们将展示为什么这种行为会导致漏洞。假设我们正在运行一个基础设施,其中前端是一个 PHP 程序,后端则是一个 Python 程序。
攻击者向 PHP 前端发送以下的 GET 请求:
GET https://victim.com/?a=1;b=2 PHP 前端只识别出一个查询参数“a”,其内容为“1;b=2”。PHP
不把“;”字符作为查询参数的分隔符。现在,前端会将攻击者的请求直接转发给内部的 Python 程序:
GET https://internal.backend/?a=1;b=2
自我介绍一下,小编13年上海交大毕业,曾经在小公司待过,也去过华为、OPPO等大厂,18年进入阿里一直到现在。
深知大多数网络安全工程师,想要提升技能,往往是自己摸索成长,但自己不成体系的自学效果低效又漫长,而且极易碰到天花板技术停滞不前!
因此收集整理了一份《2024年网络安全全套学习资料》,初衷也很简单,就是希望能够帮助到想自学提升又不知道该从何学起的朋友。
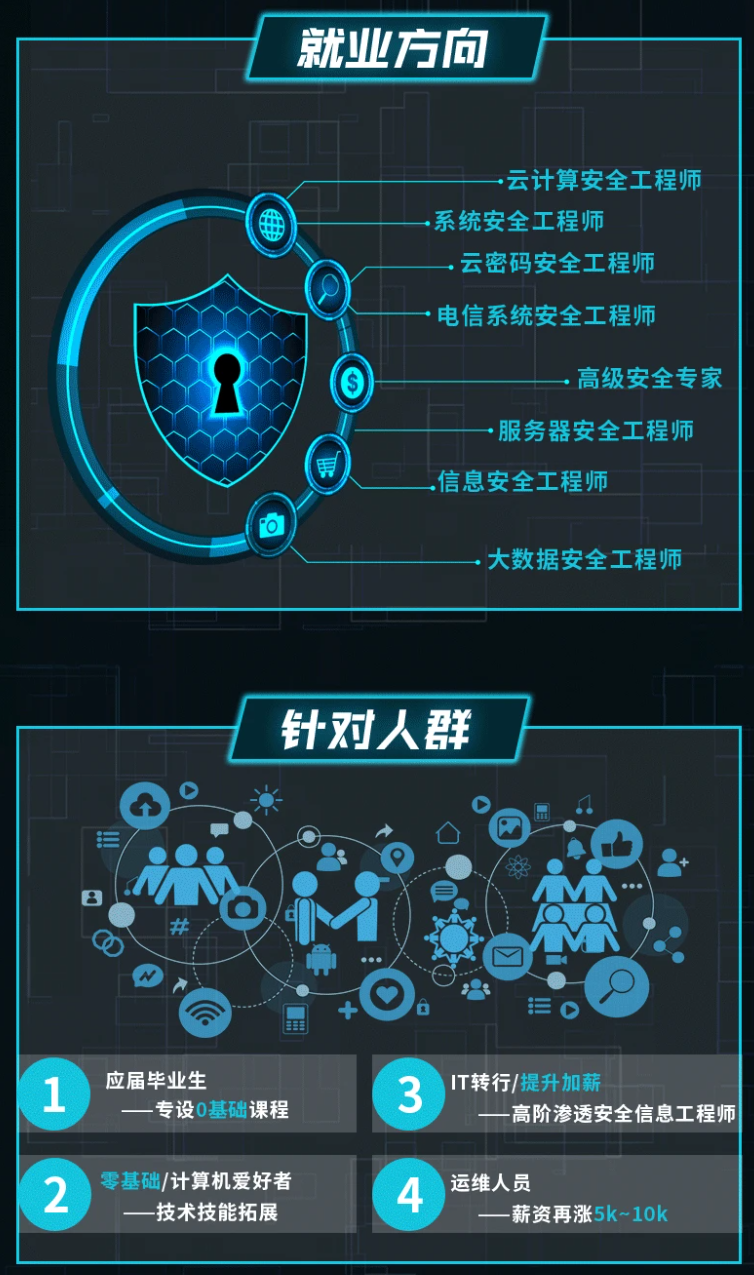
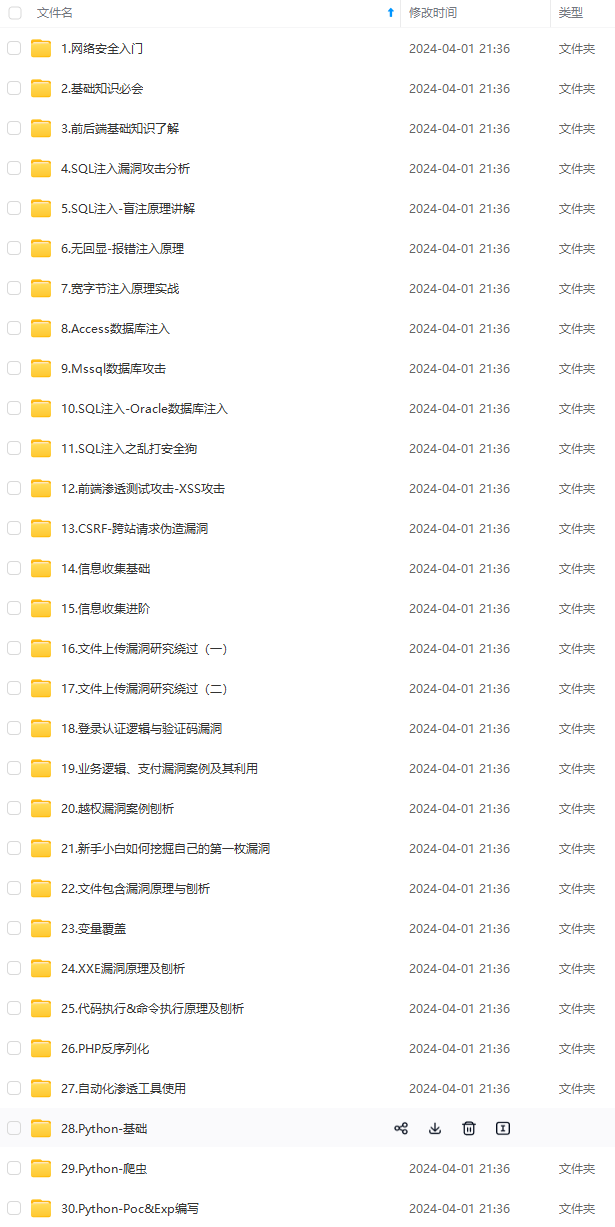
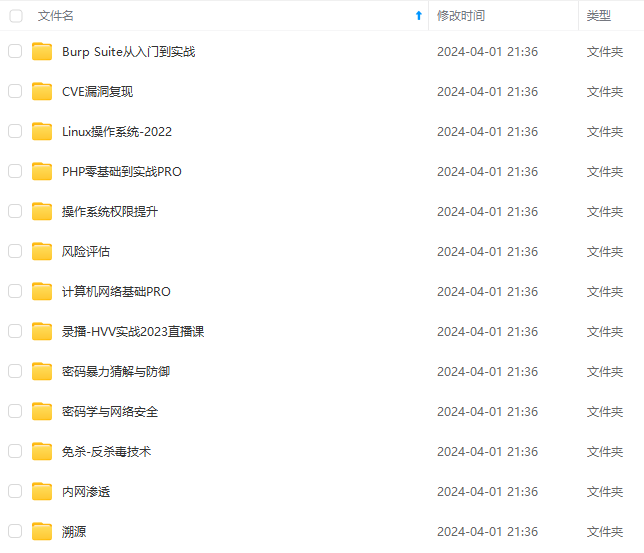
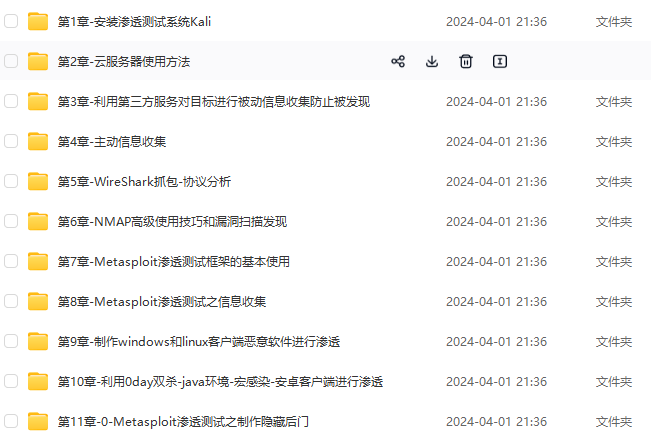
既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,基本涵盖了95%以上网络安全知识点,真正体系化!
由于文件比较大,这里只是将部分目录大纲截图出来,每个节点里面都包含大厂面经、学习笔记、源码讲义、实战项目、讲解视频,并且后续会持续更新
如果你觉得这些内容对你有帮助,可以添加VX:vip204888 (备注网络安全获取)

本人从事网路安全工作12年,曾在2个大厂工作过,安全服务、售后服务、售前、攻防比赛、安全讲师、销售经理等职位都做过,对这个行业了解比较全面。
最近遍览了各种网络安全类的文章,内容参差不齐,其中不伐有大佬倾力教学,也有各种不良机构浑水摸鱼,在收到几条私信,发现大家对一套完整的系统的网络安全从学习路线到学习资料,甚至是工具有着不小的需求。
最后,我将这部分内容融会贯通成了一套282G的网络安全资料包,所有类目条理清晰,知识点层层递进,需要的小伙伴可以点击下方小卡片领取哦!下面就开始进入正题,如何从一个萌新一步一步进入网络安全行业。
学习路线图
其中最为瞩目也是最为基础的就是网络安全学习路线图,这里我给大家分享一份打磨了3个月,已经更新到4.0版本的网络安全学习路线图。
相比起繁琐的文字,还是生动的视频教程更加适合零基础的同学们学习,这里也是整理了一份与上述学习路线一一对应的网络安全视频教程。
网络安全工具箱
当然,当你入门之后,仅仅是视频教程已经不能满足你的需求了,你肯定需要学习各种工具的使用以及大量的实战项目,这里也分享一份我自己整理的网络安全入门工具以及使用教程和实战。
项目实战
最后就是项目实战,这里带来的是SRC资料 &HW资料,毕竟实战是检验真理的唯一标准嘛~

面试题
归根结底,我们的最终目的都是为了就业,所以这份结合了多位朋友的亲身经验打磨的面试题合集你绝对不能错过!
一个人可以走的很快,但一群人才能走的更远。不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎扫码加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!

68bb227d8f959.jpeg)
项目实战
最后就是项目实战,这里带来的是SRC资料 &HW资料,毕竟实战是检验真理的唯一标准嘛~

面试题
归根结底,我们的最终目的都是为了就业,所以这份结合了多位朋友的亲身经验打磨的面试题合集你绝对不能错过!
一个人可以走的很快,但一群人才能走的更远。不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎扫码加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
[外链图片转存中…(img-jH8BBTEZ-1712924996595)]
学习网络安全技术的方法无非三种:
第一种是报网络安全专业,现在叫网络空间安全专业,主要专业课程:程序设计、计算机组成原理原理、数据结构、操作系统原理、数据库系统、 计算机网络、人工智能、自然语言处理、社会计算、网络安全法律法规、网络安全、内容安全、数字取证、机器学习,多媒体技术,信息检索、舆情分析等。
第二种是自学,就是在网上找资源、找教程,或者是想办法认识一-些大佬,抱紧大腿,不过这种方法很耗时间,而且学习没有规划,可能很长一段时间感觉自己没有进步,容易劝退。
如果你对网络安全入门感兴趣,那么你需要的话可以点击这里
Copyright © 2003-2013 www.wpsshop.cn 版权所有,并保留所有权利。

