
热门标签
热门文章
- 1JDK的安装配置与Eclipse的安装(win10)_jdk20适用于哪个版本的eclipse
- 2自动驾驶全栈学习路线汇总!十三个主流方向都在这里了~
- 3接口测试-面试题_接口测试面试题
- 4服务器数据恢复—Raid5阵列热备盘上线过程中断导致阵列崩溃的数据恢复案例
- 5NISP,CISP考试费用与含金量_nisp申请cisp花多少钱
- 6论文阅读_csdn阅读论文
- 7SaaS 多租户【字段隔离】_请求的租户标识未传递,请进行排查
- 8Leetcode 378. 有序矩阵中第 K 小的元素_378 有序矩阵 对角线
- 9opencv模糊图像变清晰_去卷积:怎么把模糊的图像变清晰?
- 10【深度学习基础】CSPNet——PyTorch实现CSPDenseNet和CSPResNeXt_cspnet结构
当前位置: article > 正文
后端分布式系列:分布式存储-HDFS 架构解析_the hadoop distributed file system konstantin shva
作者:正经夜光杯 | 2024-08-17 07:03:15
赞
踩
the hadoop distributed file system konstantin shvachko,
本文以 Hadoop 提供的分布式文件系统(HDFS)为例来进一步展开解析分布式存储服务架构设计的要点。
架构目标
任何一种软件框架或服务都是为了解决特定问题而产生的。还记得我们在 《分布式存储 - 概述》一文中描述的几个关注方面么?分布式文件系统属于分布式存储中的一种面向文件的数据模型,它需要解决单机文件系统面临的容量扩展和容错问题。
所以 HDFS 的架构设计目标就呼之欲出了:
- 面向超大文件或大量的文件数据集
- 自动检测局部的硬件错误并快速恢复
基于此目标,考虑应用场景出于简化设计和实现的目的,HDFS 假设了一种 write-once-read-many 的文件访问模型。这种一次写入并被大量读出的模型在现实中确实适应很多业务场景,架构设计的此类假设是合理的。正因为此类假设的存在,也限定了它的应用场景。
架构总揽
下面是一张来自官方文档的架构图:
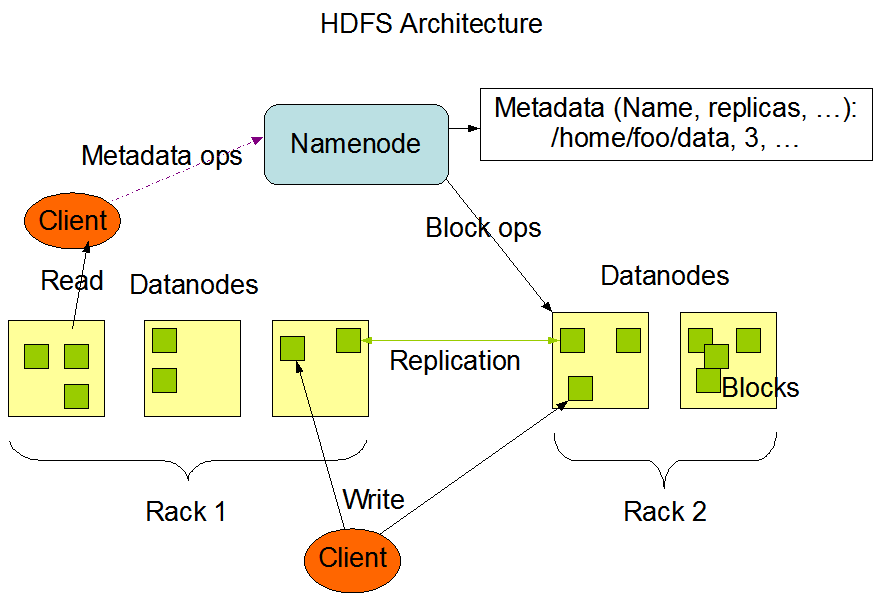
从图中可见 HDFS 的架构包括三个部分,每个部分有各自清晰的职责划分。
- NameNode
- DataNode
- Client
从图中可见,HDFS 采用的是中心总控式架构,NameNode 就是集群的中心节点。
NameNode
NameNode 的主要职责是管理整个文件系统的元信息(Metadata),元信息主要包括
推荐阅读
相关标签

