
- 1rabbitmq的延迟队列和死信队列的实现(二种方式,超详细)_mq 延时消息 死信队列
- 2Go语言开发利器:几种主流IDE的优势与应用_go语言开发工具
- 3【LangChain】第3篇:Agent代理简介及实践_agent代理程序
- 4如何和hr谈薪资_hr问师兄的薪资
- 5嵌入式单片机之STM32F103C8T6最小系统板电路设计参考_stm32f103c8t6怎么用电池供电
- 6【Lora模型训练过程报错】Error no kernel image is available for execution on the device at line
- 7android测试类Test
- 8经典的Embedding方法Word2vec_word2vec.word2vec
- 9【人工智能】Transformers之Pipeline(二):自动语音识别(automatic-speech-recognition)_pipeline语音识别
- 10数字人整合包集合,第六个最好用,附免费下载链接_echomimic musetalk sadtalker 对比
如何让大模型的输出长度可控?Meta AI开源新方法_大模型限制输出字数
赞
踩
如何让大模型的输出长度可控?Meta AI开源新方法
原创 nipi NLP前沿 2024-06-26 13:59 湖北
在实际的应用落地过程中,经常会遇到期望“大模型输出的长度不能超过多少” 这种需求。但是在prompt中,加了一个代表输出长度的参数约束之后,模型大概率还是不会按照你约束的要求来输出。这里的原因可能有很多,比如,对齐的模型评估因为存在长度偏差,算法倾向于输出更长的响应来利用偏差等。即使是目前最顶级的大模型:GPT4、Claude3 ops,仍然会出现几乎50%的概率违反长度约束,如下图的红蓝点占比几乎接近,这说明现有的模型在控制输出长度时存在的重大缺陷。
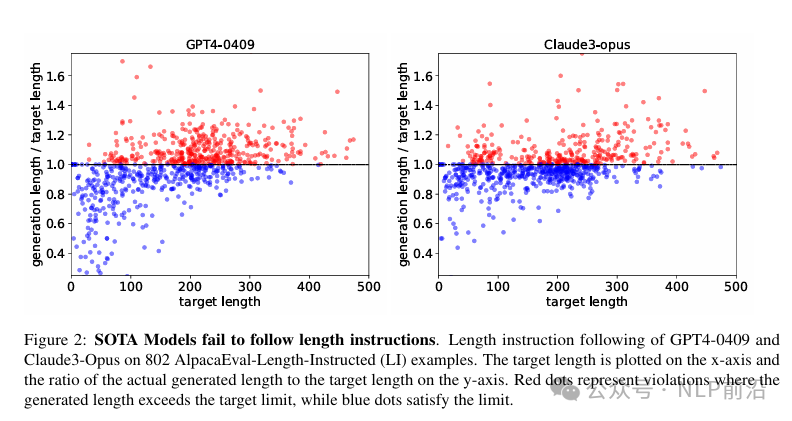
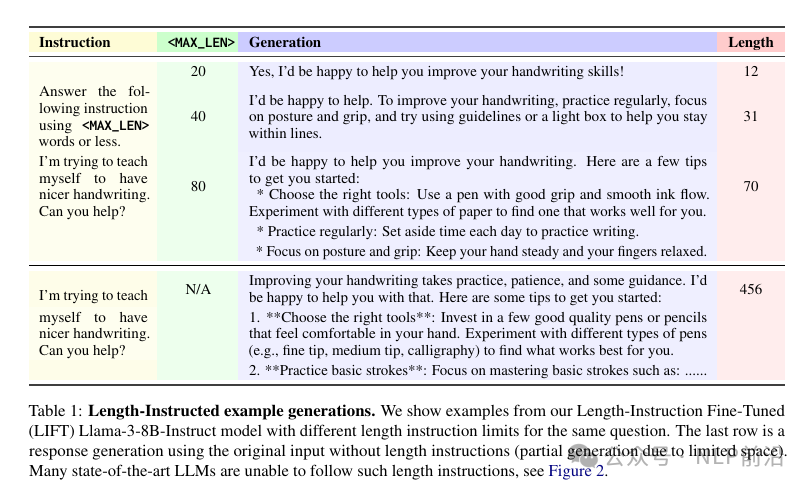
尽管一些评估基准测试通过引入长度惩罚来对抗这种偏差,但这并未从根本上解决问题。文章认为,许多查询中期望的回答长度是定义不明确的,这种模糊性使得评估变得困难,并影响了使用这些评估信号的训练算法。因此作者提出,在评估中应包含进一步的明确化指令,规定期望的回答长度。例如,通过添加“回答应少于300个单词”的额外指令来解决模糊性。并且为了改善模型遵循长度指令的能力,提出了LIFT(Length-Instruction Fine-Tuning )的方法,测试效果如下图,通过指定生成的最大长度,模型基本都会遵守。文章重点是如何构造一个有效的数据集可以调优模型对长度约束的遵循能力。
文章地址如下:
https://arxiv.org/pdf/2406.17744
由于当前的 SOTA 模型都可能会不遵循prompt中的指定长度约束。为了提高模型在长度指令跟踪任务中的能力。LIFT方法首先构建长度指令微调数据。该训练数据由偏好对组成,可用于通过 RLHF 或其他偏好优化方法来训练模型。
数据构造方式:
-
选择一个已有的偏好对齐数据集,数据格式为(x,y_w,y_l)
-
过滤掉len(y_w)与len(y_l)长度差异小于阈值T=10的样本
-
对于筛选出的回答对,使用特定的模板在原始提示前插入长度指令。这个模板要求模型生成的回答不超过特定的单词数量。
-
构建新的偏好对,文字描述&图片描述如下:
-
如果len(y_w) > len(y_l),则可以构造2个样本,长度约束大于二者最大长度,仍然是y_w > y_l;长度约束介于len(y_l)和len(y_w)之间,则修改为y_l > y_w
-
如果len(y_w) < len(y_l),构造方式同上一致,但是这种情况不用修改win,lose
-
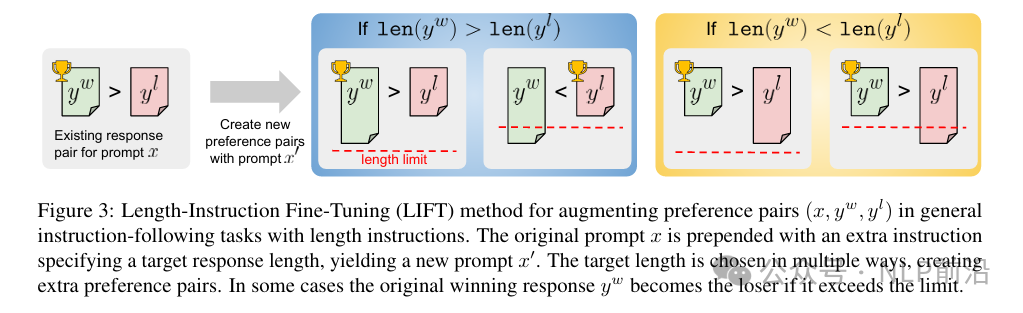
构造完数据,使用dpo训练。
评测的一些结论
-
LIFT-DPO方法显著提高了模型遵循长度指令的能力。例如,Llama2-70B-Base模型在接受标准DPO训练时,在AlpacaEval-LI上的违反率为65.8%,而在接受LIFT-DPO训练后,这一比率大幅降低到7.1%,同时胜率也从4.6%提高到13.6%。
-
LIFT-DPO训练不仅提高了遵循长度指令的能力,而且保持了在没有长度限制时的指令跟随性能。在没有长度指令的标准AlpacaEval 2和MT-Bench基准测试上,与标准DPO模型相比,没有表现出性能下降。这表明
-
通过逐步减少长度指令的限制(通过缩放因子),发现LIFT-DPO模型即使在非常严格的长度限制下,也能保持低违反率(低于10%),而标准DPO和R-DPO模型的违反率则随着长度限制的减少而显著增加。
最后
文章通过提出LIFT方法,目标是减少模型评估中的“长度偏差”,提高模型遵循用户指令的生成长度约束的能力,使得大模型在实际应用中提供更多的可控性。
PS:给公众号添加【星标⭐️】不迷路!您的点赞、在看、关注是我坚持的最大动力!
欢迎多多关注公众号「NLP前沿」,加入交流群,交个朋友吧,一起学习,一起进步!
近几天文章推荐

