
热门标签
热门文章
- 1Pyspark Windows测试环境部署(Hadoop、Spark、IDEA)、Pyspark读取Mysql数据、Spark-submit命令提交Pyspark程序_spark需要windows的mysql吗?
- 2HDL Bits刷题记录,counter1000,1Hz计数器_from a 1000 hz clock, derive a 1 hz signal, called
- 3使用React创建一个web3的前端_入门web3前端
- 4MongoDB启动命令
- 5AI通用大模型 —— Pathways,MoE, etc._moe大模型和其他通用大模型的区别
- 6本地部署Llama3教程,断网也能用啦!_llma3本地部署
- 7浙江大学软件学院人工智能保研面经2021_浙大软院推免面试名单
- 8月薪15~20k的前端面试问什么?(1),2024年最新面试官必问的技术问题之一有哪些
- 9leetcode 53. 最大子数组和
- 10什么是UI设计?_ui设计 csdn
当前位置: article > 正文
大语言模型原理与应用实践:基于监督学习进行微调 Supervised Learning & Fine-Tuning
作者:煮酒与君饮 | 2024-06-28 12:25:05
赞
踩
大语言模型原理与应用实践:基于监督学习进行微调 Supervised Learning & Fine-Tuning
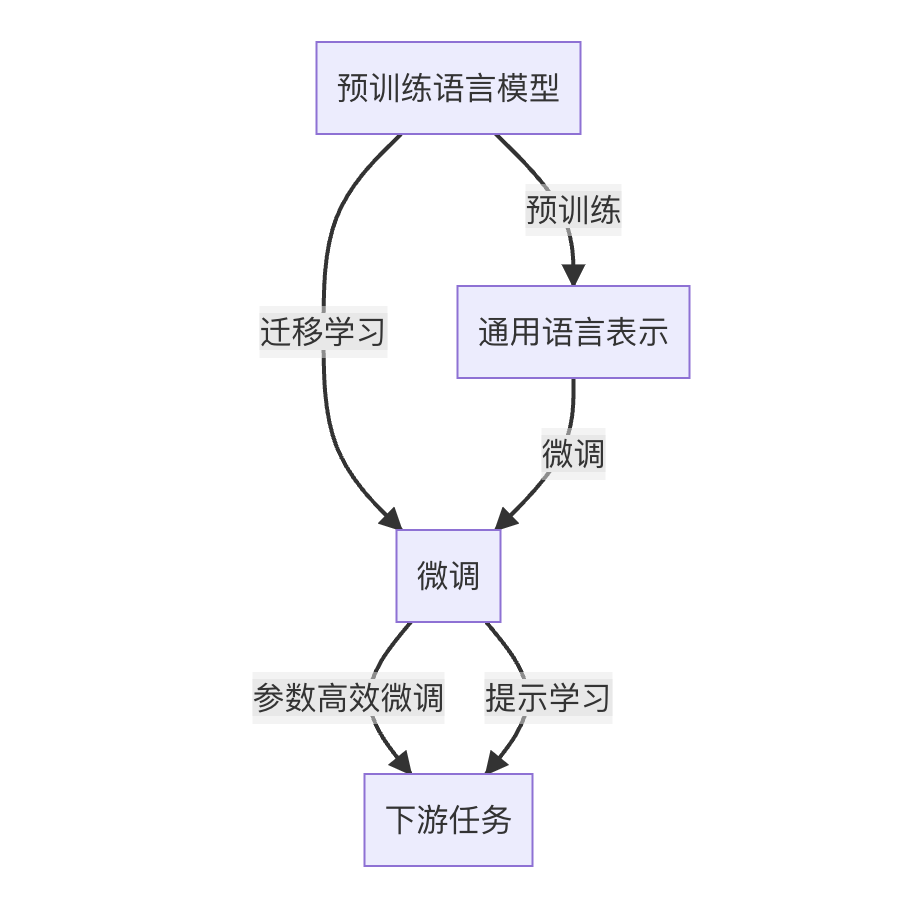
文章目录
- 大语言模型原理与应用实践:基于监督学习进行微调 Supervised Learning & Fine-Tuning
- 大语言模型原理与应用实践:基于监督学习进行微调 Supervised Learning & Fine-Tuning 2
- 大语言模型原理与应用实践:基于监督学习进行微调 Supervised Learning & Fine-Tuning3
大语言模型原理与应用实践:基于监督学习进行微调 Supervised Learning & Fine-Tuning
关键词:大语言模型,微调(Fine-tuning),迁移学习,监督学习,Transformer,BERT,预训练,下游任务,参数高效微调,自然语言处理(NLP)
1. 背景介绍
1.1 问题的由来
近年来,随着深度学习技术的快速发展,大规模语言模型(Large Language Models, LLMs)在自然语言处理(Natural Language Processing, NLP)领域取得了巨大的突破。这些大语言模型通过在海量无标签文本数据上进行预训练,学习到了丰富的语言知识和常识,可以通过少量的有标签样本在下游任务上进行微调(Fine-Tuning),获得优异的性能。其中最具代表性的大模型包括OpenAI的GPT系列模型、Google的BERT、T5等。
然而,由于预训练语料的广泛性和泛化能力的不足,这些通用的大语言模型在特定领域应用时,效果往往难以达到实际应用的要求。因此,如何针对特定任务进行大模型微调,提升模型性能,成为了当前大语言模型研究和应用的一个热点问题。
1.2 研究现状
目前,大语言模型微调的主流范式是基于监督学习的微调方法。即收集该任务的少量标注数据,将预训练模型当作初始化参
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/煮酒与君饮/article/detail/765971
推荐阅读
相关标签

