
- 1【科研小小白的神经网络Day1】读懂线性回归的代码必掌握的几个函数:torch.zeros、torch.tensor、torch.normal、torch.matmul
- 2无人机之电池保养
- 3深入理解dropout(原理+手动实现+实战)_dropout实现
- 4互联网公司校招Java面试题总结及答案——网易_网易面试java代码题目
- 5DDR官方例程读写仿真记录_ddr读写仿真
- 6区块链快速入门_bip32
- 7基于Java网上订餐系统的设计与实现(论文+源码)_基于java订餐系统论文
- 8import tensorflow遇到的问题 ImportError: Could not find 'msvcp140.dll'_install this dll by downloading visual c++ 2015 re
- 9深入解析CompletableFuture的功能和用法_completablefuture的join会阻塞其他异步线程吗
- 10云WAF如何帮助政府网络进行安全防御
打破算力瓶颈!实现大模型智能更强涌现
赞
踩

我们已经进入大模型时代,据不完全统计,仅是国内正式发布的大模型就超过了 200 个,而且这些模型在不断的升级中,新的模型还不断发布出来,过去的一周多,中国农业大学发布了“神农大模型”,网易发布了“子曰”大模型 2.0 版本。
模型的智能涌现水平同参数量有着直接关系,“大”仍是大模型升级的主流选择。以 GPT 为例,GPT-2 参数量为 15 亿,GPT-3 参数量为 1750 亿,提高了 100 倍,最新的 GPT-4 有消息称参数量为 1.8 万亿,提高了 10 倍。
模型参数量越大,需要的训练量也就越大,消耗的算力也就越多。任何一个大模型的开发和升级都需要考虑算力约束。那么模型的规模同所需算力之间到底是什么关系,我们需要解决这个问题,以便在模型升级过程中做好算力预算。

模型所需算力正比于参数量的平方
Transformer 是当前应用最广的 AI 架构。我们以 Transformer 为核心的大模型为例来估算计算量。
大模型的参数量主要取决于隐藏层的维度和构成模型的Block的数量,我们假定隐藏层的维度为 h,Block 的数量为 i,那么,大模型的参数量为 。我们以 b 代指训练输入数据的 batch size 和每个输入序列(sequence)的长度,那么整个模型训练一次的计算量为 ,上述关系已经得到严格的数学证明,在此不展开。
我们用 C 来指代模型所需算力当量,用 N 来指代模型参数量,来看两者的关系,得到如下结果:
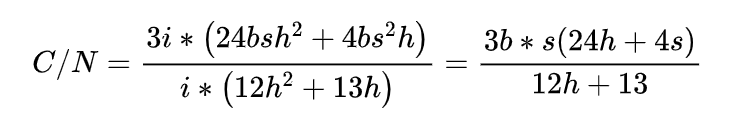
由于在百亿、千亿参数的大模型中,隐含层的维度 h 远大于输入序列的长度 s,可以将 S 忽略不计。所以,上述等式的结果可以近似为 6b*s。b*s 是一次训练输入的总 token 数,我们用 D 来指代。
由此可以得出训练大模型的所需的算力当量评估公式:
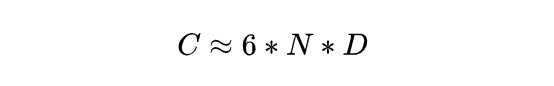
D 同 N 相关性非常大,也就是模型越大训练的总 token 数也越大,我们把这个关系总结为一个线性函数 N=kD,k 是一个固定的常数。
这样上述公式就变为:
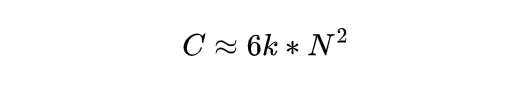
也就是说,大模型规模增大一倍,所需要的算力会增大 4 倍,如果增大 10 倍,所需算力就会增大 100 倍。大模型的算力需求增长速度超越了当前的计算技术极限,让大模型竞赛成为算力竞赛。
在实际的大模型前沿探索中,算力已经成为最大的制约因素。单从资金的角度看,训练千亿、万亿大模型的算力成本已经超出了大多数企业的承受能力,即使有钱如 OpenAI 也负担不起,据透露,GPT-4 每次训练成本高达 6300 万美元。

算力分配的变化——氪算力可直接提高智能涌现
增大参数量,降低训练量,或者保持参数量不变,直接加大训练量,两个方法都可以提高模型的智能涌现水平。好钢要用在刀刃上,在有限的算力约束下,该如何分配?此前的研究结论一直倾向于前者。2020 年 OpenAI 提出一个结论,给定 10 倍的计算预算,他们建议模型的大小应该增加 5.5 倍,而训练 token 数量只增加 1.8 倍。
但是 2023 年 DeepMind 提出了新的观点,模型大小和训练 token 数量应该等比例缩放,模型增大 1 倍,token 数量也应该增加 1 倍。而且 DeepMind 还认为目前的大模型普遍存在训练不足的情况,一个大模型训练充分需要把每个参数训练 20 个 token,但是业界主要的大模型普遍的训练水平不高于每个参数 10 个 token。
这个结论来源于严格的技术实验,DeepMind 用 1.4 万亿 token 训练了参数量为 700 亿的大模型 Chinchilla,该模型的表现超过了参数量 2800 亿的 Gopher、1750 亿 的 GPT-3 和 5300 亿的 Megatron-Turing。
因此,我们可以把前文提到的公式进一步量化为 ,也就是一个大模型要训练的较为彻底,所需要的算力当量是模型规模平方的 120 倍。
在 DeepMind 的研究结果发布以后,大模型“大”竞争开始放缓。2022 年人类大模型普遍达到千亿级别之后,2023 年除了 GPT-4,其他新发布的大模型并没有突破万亿级别,甚至出现了很多百亿级别的模型。控制模型规模,进行更充分的训练,会实现更为理想的智能涌现。
以浪潮信息的“源”大模型为例,1.0 版本参数量 2450 亿,零样本和小样本学习表现优异,能够进行人机对话、与人玩剧本杀、写公文,相当于一个文科生的水平,但是 2.0 版本最大的参数量为 1026 亿,却可以进行高水平的逻辑推理、做数学题、写代码,相当于一个 985 大学的理科生,水平不可同日而语。
投入更大算力对百亿、千亿的模型进行训练挖潜,具有非常重大的现实意义。中小模型,以及由这些基础模型生成的技能模型,对硬件的要求、能源的消耗相对较小。如果基础大模型的参数规模降低 1%,那么对应技能模型的每次推理计算的算力消耗也会降低 1%,会产生巨大的社会意义和经济意义。

发展AI,应该优先发展计算力
应该说,今天的 AI 仍处于发展的初级阶段,AI 也刚开始走入社会经济和个人生活。未来可能不仅每个场景会有一个大模型,每个人也会有一个大模型,这并不是假想,而是很快就能看到的现实。
所以,在相当长的一个时期内,大模型的训练需求将保持旺盛的增长,算力瓶颈是大模型训练和应用面临的长期问题。发展 AI 需要优先发展算力,无论国家还是企业,应该将更多的资源投入到算力产业中。
Copyright © 2003-2013 www.wpsshop.cn 版权所有,并保留所有权利。

