
热门标签
热门文章
- 1go mod 删除包_Golang中Modle包的使用
- 2Redis的安装启动和redisManager的连接和Spring Boot集成
- 3神仙级渗透测试入门教程(非常详细),从零基础入门到精通,从看这篇开始!_网络渗透技术自学_渗透人员手动执行渗透测试
- 4mysql query use_mysql_query()函数执行“use 数据库名”这条SQL语句能实现数据库的选择( )。...
- 5kegra:用Keras深度学习知识图_keras 知识图谱
- 6NLP_循环神经网络(RNN)_循环神经网络nlp
- 7浅谈HTTP状态码_网址临时过载货维护
- 8git 将dev分支的代码合并到master_dev合并到master
- 9Java中split方法详细讲解_java split
- 10【渝粤题库】陕西师范大学164205 ERP原理及应用 作业(专升本)_产品a的零件废品系数为2%
当前位置: article > 正文
极客时间:在发布之际本地简单测试Llama 3、Gemma和Mistral模型_llama3 gemma
作者:煮酒与君饮 | 2024-07-20 22:30:33
赞
踩
llama3 gemma
每周跟踪AI热点新闻动向和震撼发展 想要探索生成式人工智能的前沿进展吗?订阅我们的简报,深入解析最新的技术突破、实际应用案例和未来的趋势。与全球数同行一同,从行业内部的深度分析和实用指南中受益。不要错过这个机会,成为AI领域的领跑者。点击订阅,与未来同行! 订阅:https://rengongzhineng.io/

在发布Llama 3之后,我在我的8G内存M1 Macbook上对三个模型进行了本地测试:gemma:2b(我本想使用gemma:7b,但在ollama中遇到了‘模型未找到’的错误。因此,这不是一个公平的比较。如果你知道原因,请在下面留言),llama3:8b和Mistral:7.3b。这篇博客展示了测试问题及其答案,并评估了每个模型的正确性和详细性能。我使用基于Python的ollama库来查询模型并根据执行时间、峰值内存使用和响应准确性来评估它们。下面是用于测试的Python脚本.
- import time
- import psutil
- from memory_profiler import memory_usage
- import ollama
-
- model_names = ['gemma:2b', 'llama3', 'mistral']
-
- questions = [
- "What is the capital of France?",
- "Explain the theory of relativity.",
- "Who wrote 'Pride and Prejudice'?",
- "How does photosynthesis work?"
- ]
-
- def ask_questions(model, questions):
- for question in questions:
- print(f"Question: {question}")
- def model_call():
- return ollama.chat(model=model, messages=[{'role': 'user', 'content': question}])
- start_time = time.time()
- memory_and_response = memory_usage(proc=model_call, interval=0.01, retval=True, max_usage=True)
- peak_memory, response = memory_and_response
- end_time = time.time()
- answer = response['message']['content'] if 'message' in response and 'content' in response['message'] else "No valid response"
- elapsed_time = end_time - start_time
- print(f"Answer: {answer}\nTime taken: {elapsed_time:.2f} seconds\nPeak memory used: {peak_memory:.2f} MB\n")
- print("--------------------------------------------------")
-
- if __name__ == '__main__':
- for model_name in model_names:
- load_start = time.time()
- model = model_name
- load_end = time.time()
- load_time = load_end - load_start
- print(f"\nTesting model: {model_name}\nModel loading time: {load_time:.2f} seconds")
- ask_questions(model, questions)

测试问题与模型回应
我无法使用像Glue、SQuAD等问题库,因为它们的运行时间过长。因此,我向每个模型提出了相同的一小组问题,以评估它们的性能和准确性:
- What is the capital of France?
- Correct Answer: Paris
- Responses:
- gemma:2b: “The capital of France is Paris. It is also the cultural and political center of the country.”
- llama3: “The capital of France is Paris.”
- Mistral: “The capital city of France is Paris.” - Explain the theory of relativity
- Correct Answer: The theory consists of two main components: special relativity, which describes physics in the absence of gravity, and general relativity, which extends special relativity to include gravity and describes gravity as the warping of spacetime by mass
- Responses:
— gemma:2b: “Detailed explanation about space-time, speed of light, and gravity. Includes introduction to key concepts like space and time interconnection, constant speed of light, gravity as a property of spacetime, and phenomena like time dilation under special and general relativity contexts.”
-llama3: “Overview of special and general relativity with fundamental principles. Discusses Einstein’s theories from 1905 and 1915, emphasizing changes in the understanding of time and space, constant speed of light, time dilation, length contraction, and the equivalence of gravity with acceleration in influencing spacetime.”
-mistral: “Explanation of both theories, focusing on the consequences of Einstein’s principles. Describes special relativity with concepts like the constancy of the speed of light and time dilation, and general relativity’s view of gravity as spacetime curvature. Includes implications like black holes and gravitational waves.” - Who wrote ‘Pride and Prejudice’?
- Correct Answer: Jane Austen
- Responses:
— gemma:2b: “Jane Austen wrote ‘Pride and Prejudice’. She was born in 1817 and died in 1917. ‘Pride and Prejudice’ was her first published novel and was first published in 1813.” (Correct but contains factual errors in birth and death year)
-llama3: “Jane Austen, a renowned English novelist known for her works of romantic fiction.” (Correct)
-mistral: “Jane Austen wrote ‘Pride and Prejudice’.” (Correct) - How does photosynthesis work?
- Correct Answer: Photosynthesis is the process by which green plants and some other organisms use sunlight to synthesize foods from carbon dioxide and water. It generally involves the green pigment chlorophyll and generates oxygen as a byproduct
- Responses:
— gemma:2b: Detailed steps of light absorption, water splitting, carbon dioxide fixation, and oxygen release. (Correct and detailed)
-llama3: Overview of light-dependent and light-independent reactions. (Correct and simplified)
-mistral: Detailed explanation including light-dependent reactions and Calvin cycle. (Correct and comprehensive)
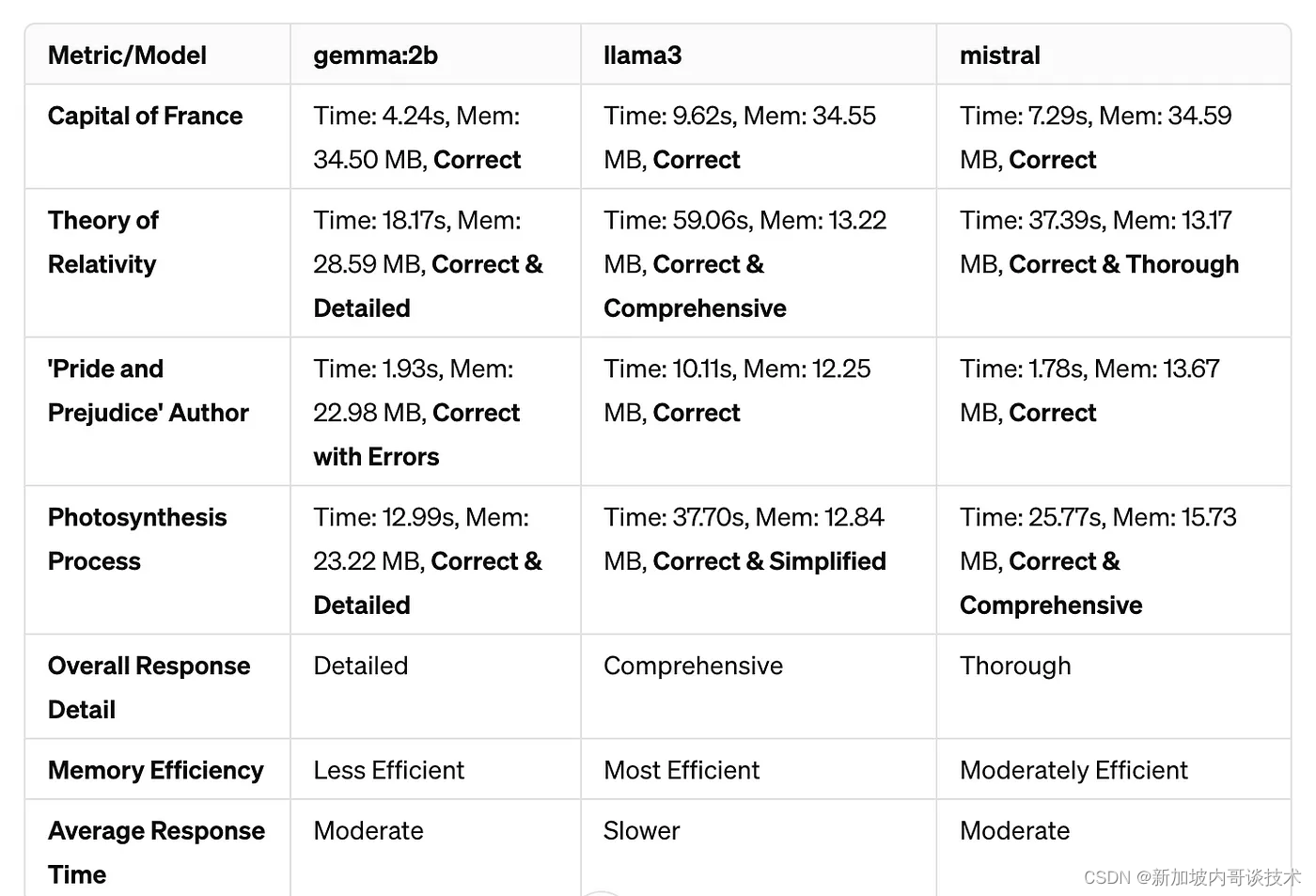
观察结果:
- 响应准确性:所有模型都准确回答了所有提出的问题。gemma:2b显示了高水平的细节,但在一个回应中包含了一些事实错误。
- 细节和清晰度:gemma:2b提供了最详细的解释,使其适合于内容深度至关重要的应用。llama3和Mistral有效地平衡了简洁性和必要的细节。
- 效率:llama3是最节省内存的模型,尽管以较长的响应时间为代价,这可能会影响实时应用中的用户体验。Mistral提供了一个良好的平衡,而gemma:2b消耗了最多的内存。
结论
总之,这里进行的测试揭示了每个模型的一些有趣发现。值得注意的是,gemma:2b是一个较小的模型,只有20亿参数,而llama3和Mistral则明显更大,每个都有超过70亿参数。尽管体积较小,gemma:2b的性能却值得称赞。然而,它倾向于包含不必要的细节,正如关于简·奥斯汀的事实错误所示,这表明其输出需要进行准确性检查。
试一试看,让我知道你那边的情况如何。玩得开心!
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/煮酒与君饮/article/detail/858652
推荐阅读
相关标签

