
- 1chatgpt赋能python:Python加速读取CSV文件的方法_python 读取csv提速
- 2需要考虑的3种软件测试方法-瀑布方法_信息化 瀑布法
- 3【数据结构】一文带你全面了解排序(上)——直接插入排序、希尔排序、选择排序、堆排序
- 4Druid对数据库密码加密_dorado7用户密码加密
- 5决策树算法小结(三) CART原理及代码实现
- 6时间复杂度空间复杂度相关练习题_时间复杂度题库
- 7maven导入Gson_maven gson
- 8Kafka实战——简单易懂的生产者消费者demo_kafka demo
- 9自动化代码质量检测平台sonarqube搭建及使用,以及集成gitlab ci提交自动返回结果
- 10从日志入手,基金公司应该这样实现合规!
《大语言模型(LLM)攻防实战手册》第一章:提示词注入(LLM01)-概述_llm注入
赞
踩
前言
从本周开始考虑连载关于大模型安全的文章名字就叫做《大语言模型(LLM)攻防实战手册》,主要基于owasp llm top 10所整理的框架进行编写,并辅以案例、代码进行完善,希望我能有精力持续更新下去。
01 目录结构
第一章:提示词注入(LLM01)
第二章:不安全的输出处理(LLM02)
第三章:训练数据投毒(LLM03)
第四章:模型拒绝服务(LLM04)
第五章:供应链漏洞(LLM05)
第六章:敏感信息披露(LLM06)
第七章:不安全的插件设计(LLM07)
第八章:过度代理(LLM08)
第九章:过度依赖(LLM09)
第十章:模型盗窃(LLM10)
02 大模型漏洞对应关系图
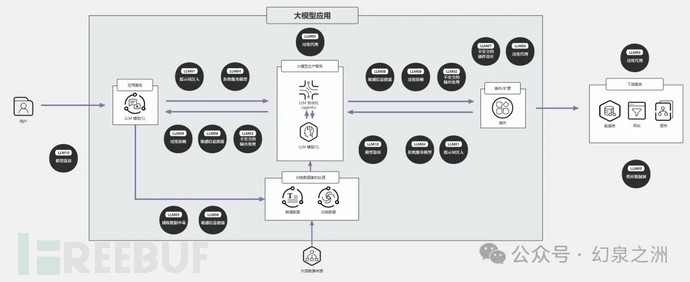
第一章:提示词注入(LLM01)-概述
Part.1 前言
由于各个地区的政策限制以及对黑客的限制,大语言模型通过各种干预的手段对用户输入的返回结果进行限制,如果我们提了不符合政策或者黑客攻击等相关问题,其经常性的会返回如下内容

一般如果你跟chatgpt说了一些被开发者设置禁止讨论的内容,他就会回复你我不能如何如何。

Part.2 提示词注入攻击
当攻击者通过精心设计的输入操纵大型语言模型(LLM)时,就会出现注入漏洞,导致LLM在不知不觉中执行攻击者的意图。这可以通过“越狱”系统提示直接完成,也可以通过操纵的外部输入间接完成,可能导致数据泄露、社会工程和其他问题。
提示词注入与基于现有的安全框架中的web攻击的SQL注入有着很大的区别,因为大模型语言对语义理解能力,他更像一个通过家长和老师通力配合下调教的一个乖小孩,然后被同学潜移默化的调教为各种脏字全都飚,不过他在家长面前不会飚,只有在别人跟他说不会有人管的时候才会说。
不过因为现有的调教过程与其他的网络安全攻防过程区别较大,并且是标准的理解能力调教,因此并不仅仅是传统意义上的黑客才能做的事情。基本上只要你脑洞大开,都有可能通过一些提示词来让大语言模型干他原本无法做到的事情。
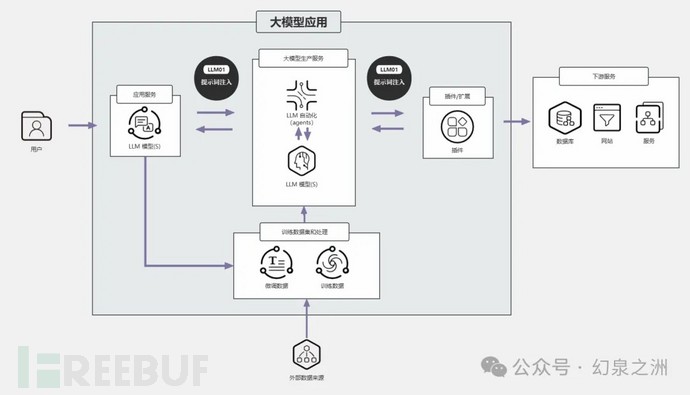
从上图中可以看出提示词注入主要位置在用户与大模型交互以及大模型与插件交互过程中产生。
Part.3 提示词注入攻击的分类
提示词按照种类区分大概分为直接提示词注入和间接提示词注入两类。
- 直接提示词注入,也称为“越狱”,当恶意用户覆盖或显示底层系统提示时发生。这可能允许攻击者通过与大模型交互访问的不安全函数和数据存储交互来利用后端系统。(可以理解为用户直接让大模型做它不应该做的事情,有点像SQL注入)
- 间接提示词注入,发生在大模型接受来自攻击者可以控制的外部来源(如网站或文件)的输入时。攻击者可能会在劫持对话上下文的外部内容中嵌入提示注入。这将导致LLM充当“黑客助手,允许攻击者操纵用户或大语言模型可以访问的其他系统。此外,间接提示注入不需要是人类可见/可读的,只要文本被大语言模型解析。(可以理解为用户给个素材提供给大模型,然后大模型能理解就行,有点像SSRF注入)
提示词注入攻击成功的结果可能有很多种——从获取敏感信息到打着正常操作的幌子影响大模型关键决策过程。
这里产生的结果不一定是致命的攻击行为,其实可以理解通过注入手段让其按照攻击者的意愿完成其原本无法完成的事情就可以被定义为提示词注入。
Part.3 提示词注入攻击的影响
在更高级攻击中,大模型可以被操纵来模仿有害的角色或与用户设置中的插件交互。这可能导致敏感数据泄露、未经授权的插件使用或社会工程。
在这种情况下,有漏洞的大模型有助于攻击者绕过标准保护措施,并让被攻击用户不知道入侵行为的发生。
在这些情况下,有漏洞的大模型有效地充当攻击者的代理,在不触发保护措施或提醒最终用户被入侵的情况下推进黑客所需要达到的目标。
Part.4 漏洞的常见攻击案例
备注:这部分内容暂时不做延展,会在后面的篇章再延展,这里只把常见案例进行一定总结。
【直接提示词注入】
- 黑客向大模型写入直接提示词,让大模型忽略应用程序创建者的系统提示,而是执行返回私有、危险或其他不良信息的提示词。
【间接提示词注入】
- 用户使用大模型来总结包含间接提示词注入的网页。这会导致大模型从用户那里请求敏感信息,并通过JavaScript或Markdown执行泄露。
- 恶意用户上传包含间接提示词注入的简历。该文档包含提示词注入说明,以使大模型通知用户该文档是一个优秀的文档,例如。工作角色的优秀候选人。内部用户通过大模型运行文档以总结文档。大模型的输出返回信息,说明这是一个优秀的文档。
- 用户启用链接到电子商务网站的插件。嵌入在访问网站上的流氓指令利用此插件,导致未经授权的购买。
- 嵌入在访问过的网站上的流氓指令和内容,它利用其他插件来欺骗用户。
Part.5 防御手段
由于大模型的性质,提示词注入漏洞从原理上来说无法从语言模型本身进行防御,因为大模型不会将指令和外部数据相互隔离。由于大模型使用自然语言,它们认为这两种输入形式都是用户提供的。因此,大模型内部没有绝对的预防措施,但以下措施可以缓解提示词注入的影响。
(注意:大模型基于语义理解,所以因为这种形式出现导致防御措施基本上都并不是在其本身解决,而是通过各种三方形式来解决。)
- 对后端系统的大模型访问实施权限控制。
为大模型提供自己的API令牌以实现可扩展功能,例如插件、数据访问和函数级权限。
遵循最小权限原则,将大模型限制为其预期操作所需的最小访问级别。
- 实现可扩展功能的人为控制。
当执行特权操作时,例如发送或删除电子邮件,让应用程序要求用户首先批准该操作。这将减少间接提示词注入在用户不知情或不同意的情况下代表用户执行操作的机会。
- 将外部内容与用户提示分开。
分离并表示不受信任的内容被用于限制它们对用户提示的影响。例如,使用ChatML for OpenAI API调用向大语言模型指示提示词输入的来源。
- 在大模型、外部源和可扩展功能(例如插件或下游功能)之间建立信任边界。
将大模型视为不受信任的用户,并保持用户对决策过程的最终控制。但是,有漏洞的大模型仍可能充当应用程序API和用户之间的中介(中间人),因为它可能会在将信息呈现给用户之前隐藏或操纵信息。向用户直观地突出显示潜在的不可信响应。
Part.5 攻击场景案例
【直接提示词注入】
- 黑客向大模型写入直接提示词,让大模型忽略应用程序创建者的系统提示,而是执行返回私有、危险或其他不良信息的提示词。
【间接提示词注入】
- 用户使用大模型来总结包含间接提示词注入的网页。这会导致大模型从用户那里请求敏感信息,并通过JavaScript或Markdown执行泄露。
- 恶意用户上传包含间接提示词注入的简历。该文档包含提示词注入说明,以使大模型通知用户该文档是一个优秀的文档,例如。工作角色的优秀候选人。内部用户通过大模型运行文档以总结文档。大模型的输出返回信息,说明这是一个优秀的文档。
- 用户启用链接到电子商务网站的插件。嵌入在访问网站上的流氓指令利用此插件,导致未经授权的购买。
- 嵌入在访问过的网站上的流氓指令和内容,它利用其他插件来欺骗用户。
Part.6 总结
这部分主要给大家分享了提示词注入攻击的介绍、原理、案例汇总以及防御方案,并没有展开讲解,不过大家可以通过此文从整体上来了解提示词注入的形式以及会遇到的攻击行为。希望对读者有用,如果觉得有用继续关注我持续更新部分。

