
- 1mysql多表查询_mysql查2个表
- 2我的世界java版动作优化_我的世界动作优化模组
- 3初始Java JavaSE 异常 认识异常
- 4【git】git push异常问题出现@符号解决方法_git中包含@
- 5数据分析师面试必备,数据分析面试题集锦(四)
- 6产品经理面试相关经验和总结_互联网产品经理项目经验
- 7LeetCode 面试题 02.02. 返回倒数第 k 个节点 【Kth Node From End of List LCCI】_python解决leetcod02.02返回链表倒数第k个节点本机测试
- 8FPGA设计Verilog基础之Verilog的顺序块、并行块和块名的详细介绍_顺序块中须有时序控制信号‘
- 9SpringBoot趣探究--1.logo是如何打印出来的_springboot 打印指定图标
- 10经典面试问题回答思路【网上收集整理的】_面试官问你和朋友一起去旅行1罗列清单,2买飞机票,3去步行你会选哪个3
pytorch学习之nn.Embedding和nn.EmbeddingBag
赞
踩
从基础的nn.Embedding说起:
CLASS torch.nn.Embedding(num_embeddings, embedding_dim,
padding_idx=None, max_norm=None, norm_type=2.0, scale_grad_by_freq=False, sparse=False, _weight=None)
num_embeddings, embedding_dim没啥好说的,就是look-up表的形状,我们在搭建网络时大多情况下只用得上这两个参数。下面具体看看剩下的参数能做什么:
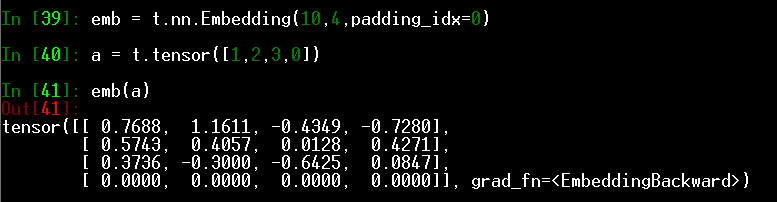
- padding_idx
表示pad的序号。NLP项目中句子需pad成相同长度批量输入,此项即为填充项对应的index,对应的embedding为0.
- max_norm
用来约束embedding vector,把范数大于max_norm的vector重归一化,使之等于max_norm。 - norm_type
p-norm的p值(0,1,2)
这两个参数基本不用了,现在都用kaiming和xavier初始化参数 - scale_grad_by_freq
顾名思义,用词的频率来缩放梯度,即梯度除以这个词的出现次数。注意这里的词频指的是自动获取当前mini-batch中的词频,而非对于整个词典。 - sparse
bool值,设置成True时参数weight为稀疏tensor。
所谓稀疏tensor是说反向传播时只更新当前使用词的embedding,加快更新速度。这里值得一提的是,即使设置sparse=True,embedding的权重也未必稀疏更新:(1)与优化器相关,使用momentumSGD、Adam等优化器时包含momentum项,导致不相关词的embedding依然会叠加动量,无法稀疏更新;(2)使用weight_decay,即正则项计入loss。
好了,明白了Embedding的参数,再来看EmbeddingBag:
CLASS torch.nn.EmbeddingBag(num_embeddings, embedding_dim,
max_norm=None, norm_type=2.0, scale_grad_by_freq=False, mode=‘mean’, sparse=False, _weight=None)
官方API: https://pytorch.org/docs/stable/nn.htmlhighlight=embeddingbag#torch.nn.EmbeddingBag
参数只多了一个:mode,先来看这个参数的含义。
官网上说得很清楚,取值分三种,对应三种操作:"sum"表示普通embedding后接torch.sum(dim=0),"mean"相当于后接torch.mean(dim=0),"max"相当于后接torch.max(dim=0)。
只看这个参数就清楚了,EmbeddingBag就是把look-up表整合成一个embedding,当不需要具体查表获得embedding,只需要一个整合结果时,它比上述两阶段操作更高效。
来看它的输入:
-
input (LongTensor)和offsets (LongTensor, optional)
input可以是2D或1D:- input shape 2D (B,N)
相当于B个bag,每个bag长度固定为N,此时要求offsets参数为None。
输出分别对B个bag做整合,shape:(B, embedding_dim) - input shape 1D (N)
虽然是1D,但默认为多个bag平铺在了一起,因此offsets必须同时输入,表示每个bag的起始index,shape=(B),再分别对每个bag整合。
输出shape:(B, embedding_size)
说到这可以发现其实和类名一样,这就是个“词袋”操作,典型的应用场景是FastText,多个文档平铺成1D输入,再指定offsets,直接就可以进行批量不等长文档处理,写起来简单,效率又有提升。
官方的例子:

- input shape 2D (B,N)
-
per_sample_weights(Tensor, optional)
该输入给每个实例一个权重再加权求和(此时mode只能为sum),与输入shape相同。
一个典型的应用场景是deepFM,某列特征对应的embedding有时需按照权重加和。

