
- 1git 文件名大小写的坑,你踩过吗?_git 大小写
- 2keil5仿真相关配置,解决相关bug_keil调试查看变量值不变化
- 3Ubuntu部署flask项目
- 4python爬取网站数据四种姿势,你值得拥有_python爬取数据
- 5如何在 Ubuntu VPS 上部署 Flask 应用程序
- 6【无标题】基于FPGA的开关电源控制_fpga控制电源开断
- 7Java实现发送邮件(含个人和企业邮箱,以及可能遇到的报错等完整讲述)_java发送企业邮箱
- 8【Git】Git、GitHub、Gitee使用手册(保姆级,初入职场必看)_gitee 手册
- 9Label中一些实用的属性_lable.font
- 10验证性因子分析(二)_验证性因子分析结果
pytorch版本RetinaFace人脸检测模型推理加速,去掉FPN第一层,不检测特别小的人脸框_retinaface in pytorch
赞
踩
pytorch版本RetinaFace人脸检测模型推理加速_胖胖大海的博客-CSDN博客
pytorch版本RetinaFace人脸检测模型推理加速,去掉FPN第一层,不检测特别小的人脸框_胖胖大海的博客-CSDN博客
在之前的文章pytorch版本RetinaFace人脸检测模型推理加速中,介绍了如何从工程实现的角度来加速Pytorch版本的RetinaFace开源代码,上一次的优化点主要有以下两点:
1、优化Prior的计算方式,提升连续处理相同分辨率图片的处理性能
2、将数据预处理操作转换到GPU上处理
上一次优化后的RetinaFace处理性能如下:

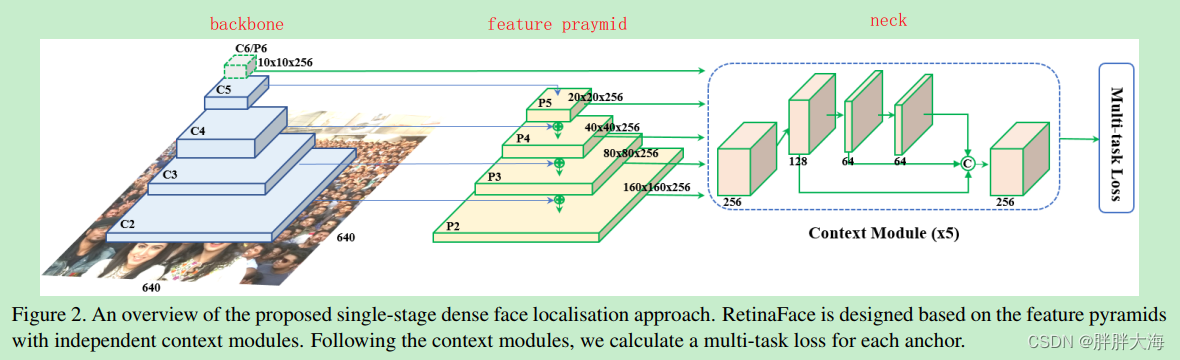
RetinaFace整体结构表示如上图,在Backbone的基础上使用FPN进行特征融合,并在每种特征图上使用ContextModule模块提取更多的上下文信息,然后预测输出人脸置信度、bbox坐标框,以及人脸关键点坐标。如上图P2特征图的感受野最小,特征粒度最小,在此特征图上使用小的anchor检测小的人脸。如上图P5特征图的感受野最大,特征粒度最粗,在此特征图上使用大的anchor检测大的人脸。
在本文中,从精简模型预测结果,丢弃小的人脸检测结果的角度对RetinaFace进行优化。通过前面的描述我们知道,RetinaFace里面采用了特征金字塔FPN,其中低层特征用来检测小的人脸,高层的特征用来检测大的人脸,但是如果下游任务是人脸识别任务的话,小的人脸对于人脸识别结果不论是在准确率还是召回率方面都没有太多正向的作用。所以在这种使用场景下可以把检测小的人脸这部分功能去掉,节省算力,还能提升一些模型的推理速度。同时,将原本代码中cpu版本的NMS操作换成torchvision中提供的GPU版本NMS来提速。
先看一下精简FPN前后人脸检测速度的对比数据:
| 精简前(处理2000张720p的图片) | 精简后(处理2000张720p的图片) | 提升效果 | |||||
| Backbone | fps | 总耗时(s) | 平均耗时(ms) | fps | 总耗时(s) | 平均耗时(ms) | |
| ResNet50 | 19.0 | 104.8 | 52.6 | 21.0 | 94.9 | 47.6 | 9.5% |
| MobileNet | 60.3 | 33.1 | 16.5 | 76.1 | 26.2 | 13.1 | 20.6% |
另外再看一下精简FPN前后的人脸检测效果对比:
FPN精简前:

FPN精简后:

下面以开源代码中提供的使用Resnet50作为backbone的模型为例,主要修改涉及到以下代码文件:
1)、./models/retinaface.py
2)、./models/net.py
3)、./data/config.py
4)、./utils/nms/py_gpu_nms.py
- 首先,看一下config.py配置文件
- cfg_re50 = {
- 'name': 'Resnet50',
- 'min_sizes': [[16, 32], [64, 128], [256, 512]],
- 'steps': [8, 16, 32],
- 'variance': [0.1, 0.2],
- 'clip': False,
- 'loc_weight': 2.0,
- 'gpu_train': True,
- 'batch_size': 24,
- 'ngpu': 4,
- 'epoch': 100,
- 'decay1': 70,
- 'decay2': 90,
- 'image_size': 840,
- 'pretrain': True,
- 'return_layers': {'layer2': 1, 'layer3': 2, 'layer4': 3},
- 'in_channel': 256,
- 'out_channel': 256
- }

其中,在上面的配置文件中,我们看到RetinaFace以Resnet50作为backbone,在backbone的layer2、layer3、layer4三个层进行FPN特征融合,min_sizes对应三个特征图上生成的anchor box的大小,steps分别分别对应三个特征图上的下采样倍数。min_sizes取值[16, 32]和steps取值8用来在低层特征图(如上面的P2)上面检测小的人脸框,所以我们可以把min_sizes里面的[16, 32]和steps里面的8去掉,得到如下的配置文件:
- cfg_re50 = {
- 'name': 'Resnet50',
- 'min_sizes': [[64, 128], [256, 512]],
- 'steps': [16, 32],
- 'variance': [0.1, 0.2],
- 'clip': False,
- 'loc_weight': 2.0,
- 'gpu_train': True,
- 'batch_size': 24,
- 'ngpu': 4,
- 'epoch': 100,
- 'decay1': 70,
- 'decay2': 90,
- 'image_size': 840,
- 'pretrain': True,
- 'return_layers': {'layer2': 1, 'layer3': 2, 'layer4': 3},
- 'in_channel': 256,
- 'out_channel': 256
- }
- 其次,在修改了config.py配置文件之后,我们打算把三层的FPN特征融合改成两层的,取消分辨率最大的(用来检测小人脸)的那一层,所以要同步修改net.py里面的FPN模块,原始的FPN模块推理代码如下:
- class FPN(nn.Module):
- def __init__(self,in_channels_list,out_channels):
- super(FPN,self).__init__()
- leaky = 0
- if (out_channels <= 64):
- leaky = 0.1
- self.output1 = conv_bn1X1(in_channels_list[0], out_channels, stride = 1, leaky = leaky)
- self.output2 = conv_bn1X1(in_channels_list[1], out_channels, stride = 1, leaky = leaky)
- self.output3 = conv_bn1X1(in_channels_list[2], out_channels, stride = 1, leaky = leaky)
-
-
- self.merge1 = conv_bn(out_channels, out_channels, leaky = leaky)
- self.merge2 = conv_bn(out_channels, out_channels, leaky = leaky)
-
-
- def forward(self, input):
- # names = list(input.keys())
- input = list(input.values())
-
-
- output1 = self.output1(input[0])
- output2 = self.output2(input[1])
- output3 = self.output3(input[2])
-
-
- up3 = F.interpolate(output3, size=[output2.size(2), output2.size(3)], mode="nearest")
- output2 = output2 + up3
- output2 = self.merge2(output2)
-
-
- up2 = F.interpolate(output2, size=[output1.size(2), output1.size(3)], mode="nearest")
- output1 = output1 + up2
- output1 = self.merge1(output1)
-
-
- out = [output1, output2, output3]
- return out
修改后的FPN模块,去掉了在forward中执行self.output1层,同时将output2上采样融合进output1这一步也去掉,代码如下:
- class FPN(nn.Module):
- def __init__(self,in_channels_list,out_channels):
- super(FPN,self).__init__()
- leaky = 0
- if (out_channels <= 64):
- leaky = 0.1
- self.output1 = conv_bn1X1(in_channels_list[0], out_channels, stride = 1, leaky = leaky)
- self.output2 = conv_bn1X1(in_channels_list[1], out_channels, stride = 1, leaky = leaky)
- self.output3 = conv_bn1X1(in_channels_list[2], out_channels, stride = 1, leaky = leaky)
-
-
- self.merge1 = conv_bn(out_channels, out_channels, leaky = leaky)
- self.merge2 = conv_bn(out_channels, out_channels, leaky = leaky)
-
-
- def forward(self, input):
- # names = list(input.keys())
- input = list(input.values())
-
-
- # output1 = self.output1(input[0])
- output2 = self.output2(input[1])
- output3 = self.output3(input[2])
-
-
- up3 = F.interpolate(output3, size=[output2.size(2), output2.size(3)], mode="nearest")
- output2 = output2 + up3
- output2 = self.merge2(output2)
-
-
- # up2 = F.interpolate(output2, size=[output1.size(2), output1.size(3)], mode="nearest")
- # output1 = output1 + up2
- # output1 = self.merge1(output1)
-
-
- out = [output2, output3]
- return out
- 最后,修改./models/retinaface.py里面的forward推理函数,由于去掉了P2特征图上的FPN操作,所以现在FPN返回的结果就少了一个特征图,由原来的三个变成了两个,以前返回的特征图是[output1, output2, output3],现在返回的特征图是[output2, output3],修改前的forward代码如下:
- def forward(self, inputs):
- out = self.body(inputs)
-
-
- # FPN
- fpn = self.fpn(out)
-
-
- # SSH
- feature1 = self.ssh1(fpn[0])
- feature2 = self.ssh2(fpn[1])
- feature3 = self.ssh3(fpn[2])
- features = [feature1, feature2, feature3]
-
-
- bbox_regressions = torch.cat([self.BboxHead[i](feature) for i, feature in enumerate(features)], dim=1)
- classifications = torch.cat([self.ClassHead[i](feature) for i, feature in enumerate(features)], dim=1)
- ldm_regressions = torch.cat([self.LandmarkHead[i](feature) for i, feature in enumerate(features)], dim=1)
-
-
- if self.phase == 'train':
- output = (bbox_regressions, classifications, ldm_regressions)
- else:
- output = (bbox_regressions, F.softmax(classifications, dim=-1), ldm_regressions)
- return output
在RetinaFace算法中,在FPN特征金字塔的基础上,对于FPN输出的每层特征使用Context Module模块进行进一步的特征融合,对应的就是代码里面的SSH模块。ssh1处理的是FPN的output1,ssh2处理的是FPN的output2,ssh2处理的是FPN的output3。所以修改后把ssh1的推理注释掉,保留ssh2和ssh3。并且,由于RetinaFace在FPN的每一级特征之后都进行一次独立的预测,预测置信度、人脸box框,以及人脸的五个关键点,所以在预测阶段,也要去掉在ssh1上的预测结果。修改后的forward代码如下:
- def forward(self, inputs):
- out = self.body(inputs)
-
-
- # FPN
- fpn = self.fpn(out)
-
-
- # SSH
- # feature1 = self.ssh1(fpn[0])
- feature2 = self.ssh2(fpn[0])
- feature3 = self.ssh3(fpn[1])
- features = [feature2, feature3]
-
- # 在每一级FPN特征之上使用独立的分支进行预测置信度、box框、关键点坐标
- bbox_regressions = torch.cat([self.BboxHead[i + 1](feature) for i, feature in enumerate(features)], dim=1)
- classifications = torch.cat([self.ClassHead[i + 1](feature) for i, feature in enumerate(features)], dim=1)
- ldm_regressions = torch.cat([self.LandmarkHead[i + 1](feature) for i, feature in enumerate(features)], dim=1)
-
-
- if self.phase == 'train':
- output = (bbox_regressions, classifications, ldm_regressions)
- else:
- output = (bbox_regressions, F.softmax(classifications, dim=-1), ldm_regressions)
- return output
- 优化nms后处理过程,将原本在cpu上执行的nms操作放到GPU上执行,修改前nms代码如下:
- def py_cpu_nms(dets, thresh):
- """Pure Python NMS baseline."""
- x1 = dets[:, 0]
- y1 = dets[:, 1]
- x2 = dets[:, 2]
- y2 = dets[:, 3]
- scores = dets[:, 4]
-
-
- areas = (x2 - x1 + 1) * (y2 - y1 + 1)
- order = scores.argsort()[::-1]
-
-
- keep = []
- while order.size > 0:
- i = order[0]
- keep.append(i)
- xx1 = np.maximum(x1[i], x1[order[1:]])
- yy1 = np.maximum(y1[i], y1[order[1:]])
- xx2 = np.minimum(x2[i], x2[order[1:]])
- yy2 = np.minimum(y2[i], y2[order[1:]])
-
-
- w = np.maximum(0.0, xx2 - xx1 + 1)
- h = np.maximum(0.0, yy2 - yy1 + 1)
- inter = w * h
- ovr = inter / (areas[i] + areas[order[1:]] - inter)
-
-
- inds = np.where(ovr <= thresh)[0]
- order = order[inds + 1]
-
- return keep
修改后的nms代码如下:
- def py_gpu_nms(dets, nms_thresh):
- """
- Arguments
- dets (Tensors[N, 5])
- :return
- """
- dets = torch.tensor(dets).cuda()
- boxes = dets[:, :4]
- scores = dets[:, -1]
- idxs = torch.zeros_like(scores)
- keep = torchvision.ops.batched_nms(boxes, scores, idxs, nms_thresh)
- return keep.detach().cpu().numpy()
总结:上述修改过程去掉了在Resnet50 backbone上,由layer2计算的FPN进行预测小的人脸检测框的功能。这样修改后,anchor box的数量从36000降低到9040,并且这样修改后,网络只是丢弃了比较小的人脸,对于后续如人脸识别的准确率和召回率都几乎没有影响。
效果:经过实际测试,在Resnet50模型上,使用P40 GPU进行推理,720p分辨率的图片人脸检测速度平均提升6ms,达到20fps左右。在MobileNet模型上,720p分辨率的图片人脸检测速度平均提升3ms,达到70fps左右。

