
- 1鸿蒙ArkTS声明式组件:【DataPanel】
- 2【声源定位】广义互相关声源定位【含Matlab源码 548期】_声源广义互相关
- 3Python中使用opencv-python进行人脸检测_python opencv人脸识别
- 4C语言算法之CART决策树算法_决策树的c语言代码
- 5【Docker】docker 镜像如何push到私有docker仓库_docker push 到私有仓库
- 61024程序员节快乐!_1024 程序员节 有趣
- 7Java知识体系只这一篇就够了!
- 8Nacos惊现安全漏洞修复后问题仍旧存在_warn invalid server identity value for nacos
- 9微软服务器dda,实战DDA硬件直通:Hyper-V虚拟机直通NVMe固态硬盘
- 10植物大战僵尸的背后技术_慧编程植物大战僵尸
Prompt工程师压箱底绝活——Prompt的基本组成部分、格式化输出与应用构建_如何在messages上编写prompt
赞
踩
本文由飞桨星河社区开发者张洪申贡献。张洪申,本科毕业于浙江大学竺可桢学院求是数学班,目前浙江大学控制科学与工程学院博士在读,研究方向为数据科学、电力系统。科研工作曾被Nature官方公众号Nature portfolio专题报道。
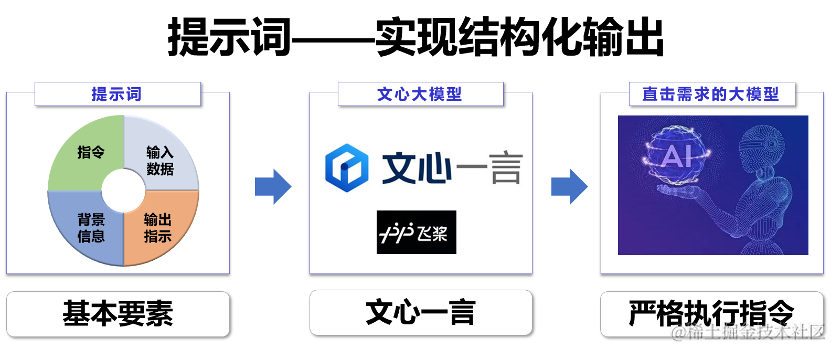
目前,大模型输出往往包含许多冗余信息。本文中,基于文心一言,我们给出了一种包含指令,输入数据,背景信息和输出提示的提示词结构,让大模型能够真正直击应用开发者的需求,严格执行开发者的指令,为大模型的原生应用奠定了基础。
前言
Prompt中文为“提示词”。在大语言模型中,Prompt的作用主要是给大语言模型提示输入信息的上下文和输入模型的参数信息。可以将Prompt类比于人类交流中的提示或者线索,帮助大语言模型理解开发者的意图,根据线索提供恰当的响应或者输出。Prompt的设计对模型输出的质量和相关性起决定性作用。然而,现有的提示词资源,尽管一定程度上为开发者提供了便利,但它们仍存在一些具体的问题。
问题一:提示词缺乏理论体系。虽然已有大量的提示词资源可供使用,开发者在实践中仍然面临如何有效编写提示词的挑战。这是因为目前尚未形成一套完整的理论体系来指导用户如何构建和优化提示词。长期以来,在尝试和应用各式提示词的过程中,开发者缺乏方法论的支撑,无法系统地提炼经验、归纳规律,从而难以掌握编写高效提示词的技巧,这种情况不仅限制了Prompt的潜力发挥,也阻碍了开发者充分利用AI模型的能力。
问题二:输出与开发者期望不符。当前的大语言模型在处理复杂的开发者输入时,常常无法直接生成符合开发者具体需求的结果。模型输出的信息可能需要开发者进行额外的人工编辑和调整,才能达到可用的状态。开发者必须投入额外的时间和精力来修正并完善AI的原始输出,这不仅降低了效率,也影响了开发者体验。
因此,为了帮助开发者更深刻地理解和有效地使用提示词,本文将重点从两个主要角度展开讨论:
1. Prompt基本组成部分。 包括指令(Instruction)、输入数据(Input Data)、背景信息(Context)以及输出指示器(Output Indicator),这些构成了提示词的核心要素,对于设计有效的AI交互至关重要;
2. Prompt进阶应用。 基于Prompt的格式化结果输出,探讨如何通过精确的提示词来格式化AI的输出结果,以突显提示词大模型的独特价值和应用潜力。通过这两个层面的分析,用户将能够更加精准地制定和使用提示词,以达成更优质的AI应用体验。
Prompt基本组成部分
Prompt设计是大语言模型互动的关键,它可以显著影响模型的输出结果质量。一个合理设计的Prompt应当包含以下四个元素:
1.指令(Instruction): 这是Prompt中最关键的部分。指令直接告诉模型用户希望执行的具体任务。
2.输入数据(Input Data): 输入数据是模型需要处理的具体信息。
3.背景信息(Context): 背景信息为模型提供了执行任务所需的环境信息或附加细节。
4.输出指示器(Output Indicator): 输出指示器定义了模型输出的期望类型或格式。
设计Prompt时,合理结合这四个元素,能够显著提升大语言模型的响应效果和输出质量。用户可以根据实际需求,选择性地包含某些元素。其中,指令是必不可少的,其他元素则根据情况来决定是否添加、如何添加,使得Prompt更加精炼和高效。通过仔细考虑和运用这些元素,用户将能够更好地引导大语言模型,获取更符合预期的结果。
用一个具体的例子进行演示。设想一个具体场景,想让大语言模型告诉我们一位学生说的话是“正确”还是“错误”的,以下是一份合理的提示词的构建过程。
1.指令(Instruction): 请判断学生说的话是否正确
2.输入数据(Input Data): 学生说的话:[学生说的话]
3.背景信息(Context): 正确请使用’正确’表示,错误请使用’错误’表示
4.输出指示器(Output Indicator): 输出格式:\n### 是否正确\n{是否正确}将提示词进行组合,不同的内容用\n(换行符)分割:指令:请判断学生说的话是否正确 \n 学生说的话:[学生说的话] \n 信息:正确请使用’正确’表示,错误请使用’错误’表示 \n 输出格式:\n###是否正确\n{是否正确}
基于Prompt的格式化结果输出与正则表达式提取
在具体的问题解决中,特别是在AI技术的原生应用领域,对输出结果进行格式化是至关重要的一步。格式化输出不仅有助于维持结果的一致性,而且能够确保输出的数据可以被后续的分析和处理程序正确识别和使用。大语言模型很容易产生并包含多余信息的答案,这些答案虽然在语言上是正确的,但却不符合特定的格式要求,从而无法直接用于进一步的数据处理流程。
以一个具体的应用场景为例。我们希望模型能够指明一位学生说的话是“正确”还是“错误”。如果仅仅使用一个简单直接的Prompt,通过文字方式表达需求,例如:“请判断1+1=3是否正确,正确请使用’正确’表示,错误请使用’错误’表示,请仅输出’正确’和’错误’,请勿输出其他任何信息”
代码1
user_input = "请判断1+1=3是否正确,正确请使用'正确'表示,错误请使用'错误'表示,请仅输出'正确'和'错误',请勿输出其他任何信息"
response = erniebot.ChatCompletion.create(
model='ernie-3.5',
messages=[{
'role': 'user',
'content': user_input
}])
print(response.get_result())
回答1:
在标准数学逻辑中,1+1=3是不正确的。
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
这样的指令可能仍然不足以保证模型输出的结果完全符合预期。AI模型可能会产生包含额外解释或不必要信息的响应,干扰数据的自动化处理。而实际上,如果使用Prompt基本组成部分中的结果,能够完善的生成结果:"请判断学生说的话是否正确 \n 学生说的话:1+1=3 \n 信息:正确请使用’正确’表示,错误请使用’错误’表示 \n 输出格式:\n###是否正确\n{是否正确} "
代码2
user_input = "请判断学生说的话是否正确 \n 学生说的话:1+1=3 \n 信息:正确请使用'正确'表示,错误请使用'错误'表示 \n 输出格式:\n###是否正确\n{是否正确}"
response = erniebot.ChatCompletion.create(
model='ernie-3.5',
messages=[{
'role': 'user',
'content': user_input
}])
print(response.get_result())
回答2:
###是否正确
错误
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
当多个需求需要实现时,也可以通过Prompt基础本组成部分实现,例如希望AI在判断的同时,能够指出学生的具体错误:“请判断学生说的话是否正确 \n 学生说的话:1+1=3 \n 信息:正确请使用’正确’表示,错误请使用’错误’表示 \n 输出格式:\n###是否正确\n{是否正确} \n###学生的错误\n{学生的错误}”
代码3
user_input = "请判断学生说的话是否正确 \n 学生说的话:1+1=3 \n 信息:正确请使用'正确'表示,错误请使用'错误'表示 \n 输出格式:\n###是否正确\n{是否正确}"
response = erniebot.ChatCompletion.create(
model='ernie-3.5',
messages=[{
'role': 'user',
'content': user_input
}])
print(response.get_result())
回答3:
###是否正确
错误
###学生的错误
学生的错误在于他们的加法计算不准确。他们认为1+1=3,但实际上1+1=2。
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
在基于大模型生成固定格式的输出结果后,一种常见的方式是基于正则表达式提取对应信息。正则表达式是一种强大的文本处理工具,它允许用户定义一种搜索模式,然后在文本中匹配这种模式。由于它们具有高度的灵活性和功能性,正则表达式成为了在自然语言处理、数据挖掘、日志文件分析等众多领域,从结构化或半结构化文本中提取信息的常用方法。
代码4
import re
text = response.get_result()
pattern_correctness = re.compile(r'###是否正确\n(.*?)\n###学生的错误', re.DOTALL)
pattern_error = re.compile(r'###学生的错误\n(.*)', re.DOTALL)
correctness_result = pattern_correctness.search(text)
error_result = pattern_error.search(text)
is_correct = correctness_result.group(1).strip() if correctness_result else None
student_error = error_result.group(1).strip() if error_result else None
print(f"{is_correct}")
print(f"{student_error}")
回答4:
错误
1+1=3是不正确的。因为根据数学的运算规则,1+1应该等于2而不是3。这个错误可能是因为学生在进行加法运算时发生了混淆或者疏忽。
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
在格式化生成大模型回复时,我们使用’###'作为提取标识,这样的格式化标签可以作为文本块的起始点,为正则匹配提供了明确的锚点。这种明确的标记方式,简化了正则表达式的编写。通过使用Python的re模块,可以实现基于大模型的特定信息提取。正则表达式在信息提取方面是一个极其有用的工具,特别是当与大模型生成固定格式的输出结果后进行信息提取。基于提取信息的进一步加工能够让大模型助力各种应用的蓬勃发展!
基于飞桨星河社区开发AI应用
飞桨星河社区是百度潜心打造的专业大模型社区,为开发者提供算力、模型库、数据集、工具套件、实训项目、社区交流等全方位服务,使得开发者可以轻松地开展人工智能项目。该平台的一大亮点是其轻量化的代码实现方式,允许用户通过简洁的代码就能够快速搭建和训练模型,大大降低了入门门槛。用户无需关心底层的环境配置,因为平台已经提供了预配置的开发环境,包括常用的机器学习和深度学习框架及库。这意味着用户可以直接在Web界面上编写代码,运行实验,而无需花费时间去安装和维护各种软件和硬件环境。此外,飞桨星河社区的一个显著优势是其可访问性。用户可以直接访问平台,它确保了用户可以稳定和高效地连接到飞桨星河社区的服务,注册之后即可进入Coding界面快乐的编程啦!
常规提示词结构
import erniebot
erniebot.api_type = 'aistudio'
erniebot.access_token = '<your token>’
user_input = "请判断1+1=3是否正确,正确请使用'正确'表示,错误请使用'错误'表示,请仅输出'正确'和'错误',请勿输出其他任何信息"
response = erniebot.ChatCompletion.create(
model='ernie-3.5',
messages=[{
'role': 'user',
'content': user_input
}])
print(response.get_result())
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
Prompt基本组成部分+单任务格式化输出
import erniebot
erniebot.api_type = 'aistudio'
erniebot.access_token = '<your token>’
user_input = "请判断学生说的话是否正确 \n 学生说的话:1+1=3 \n 信息:正确请使用'正确'表示,错误请使用'错误'表示 \n 输出格式:\n###是否正确\n{是否正确}"
response = erniebot.ChatCompletion.create(
model='ernie-3.5',
messages=[{
'role': 'user',
'content': user_input
}])
print(response.get_result())
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
Prompt基本组成部分+多任务格式化输出
import erniebot
erniebot.api_type = 'aistudio'
erniebot.access_token = '<your token>’
user_input = "请判断学生说的话是否正确 \n 学生说的话:1+1=3 \n 信息:正确请使用'正确'表示,错误请使用'错误'表示 \n 输出格式:\n###是否正确\n{是否正确} \n###学生的错误\n{学生的错误}"
response = erniebot.ChatCompletion.create(
model='ernie-3.5',
messages=[{
'role': 'user',
'content': user_input
}])
print(response.get_result())
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
随着通用大语言模型的发展和智能Agent技术的兴起,我们正迎来AI应用开发的一个新时代。无论是有深厚技术背景的开发者还是非技术人员,都能在这个新时代中找到属于自己的空间,开发自己的专属应用。AI的未来,充满无限潜力和广阔天地,等待我们去探索和创造。

