
热门标签
热门文章
- 1如何备考PMP考试?
- 2[Go语言]我的性能我做主(1)_b.reportallocs()
- 3安装运行streamlit 过程中出现的2个问题_no module named 'streamlit
- 4【JavaWeb】网上蛋糕商城-项目搭建_网上蛋糕商城web项目
- 528岁程序猿,劝告那些想去学车载测试的人
- 6华为OD机试-字符串变换最小字符串(Java&Python&Js)100%通过率_给定一个字符串 最多只能交换一次 返回变换后能得到的最小字符串
- 7强力推荐!史上最强logo设计Midjourney提示词合集_midjourney logo设计关键词
- 8pythonexcel汇总_Python汇总excel到总表格
- 9如何使用Python读写多个sheet文件_python sheets 选择读取多行sheet
- 10喜报丨上海容大中标某股份制大行信用卡中心PDA移动办卡终端项目
当前位置: article > 正文
论文阅读MVBench: A Comprehensive Multi-modal Video Understanding Benchmark
作者:爱喝兽奶帝天荒 | 2024-06-26 08:43:24
赞
踩
论文阅读MVBench: A Comprehensive Multi-modal Video Understanding Benchmark
摘要(Abstract):
论文介绍了MVBench,这是一个全新的多模态视频理解基准测试,旨在评估多模态大型语言模型(MLLMs)在视频理解方面的能力。
- 目前许多基准测试主要集中在静态图像任务的空间理解上,而忽视了动态视频任务中的时间理解。MVBench通过20个具有挑战性的视频任务来填补这一空白,这些任务无法通过单帧图像有效解决。
- 论文提出了一种新颖的静态到动态方法来定义与时间相关的任务,并将各种静态任务转化为动态任务,从而系统地生成各种视频任务,无需人工参与。
通过任务定义,研究者们自动将视频注释转换为多项选择的问答(QA),以评估每个任务。 - MVBench的构建高效且公平,避免了对LLMs的评分偏见。论文开发了一个强大的视频MLLM基线VideoChat2,并通过多样化的指令调整数据进行逐步多模态训练。
- 在MVBench上表明,现有的MLLMs在时间理解方面远未达到令人满意的水平,而VideoChat2在MVBench上的准确率超过了这些领先模型15%以上。
MVBench
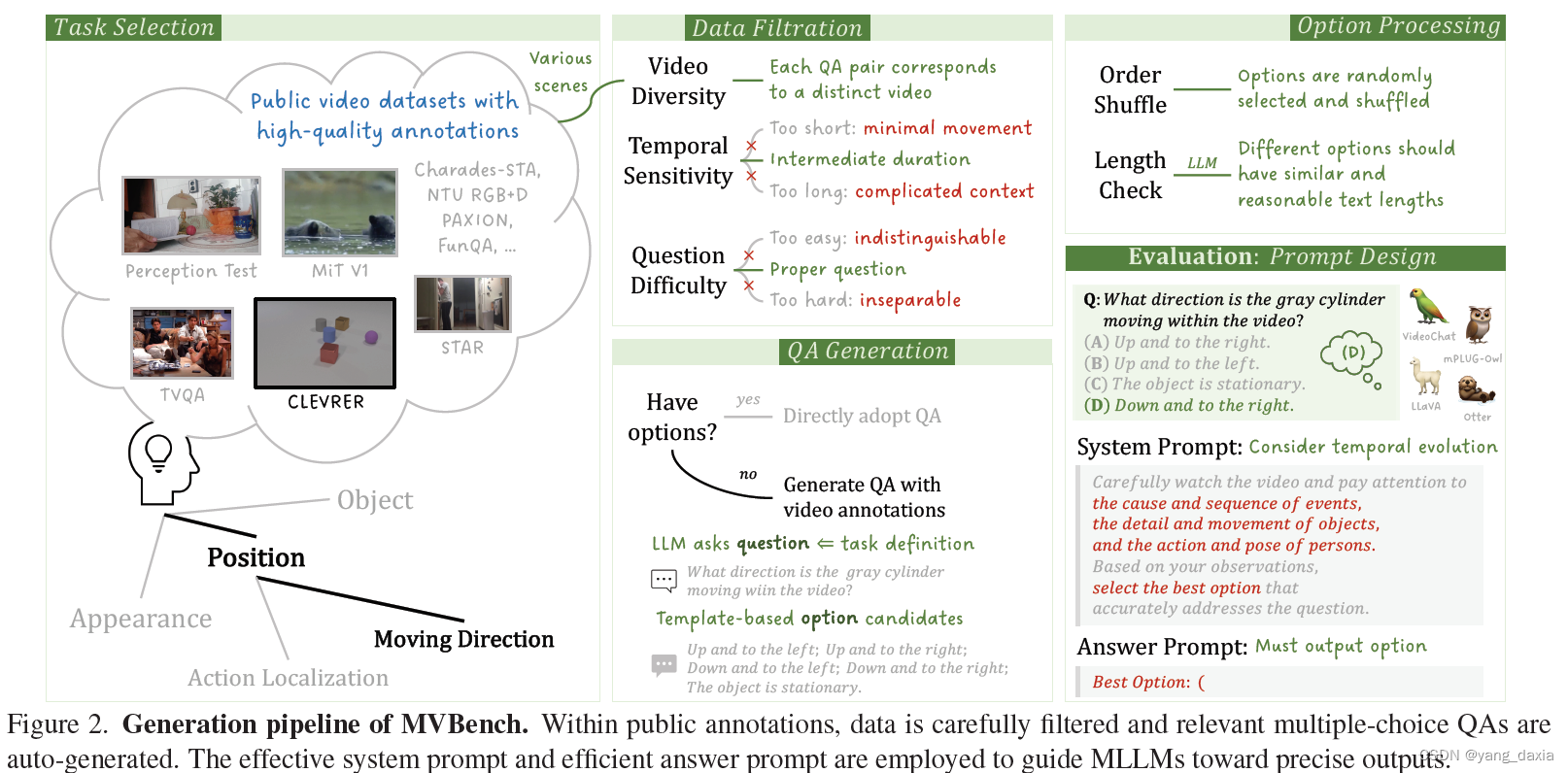
时间任务定义(Temporal Task Definition):
MVBench定义了20个视频理解任务,这些任务需要对视频的时间维度有深入理解,不能仅通过单个帧来解决。
作者提出了一种从静态到动态的方法,将先前定义的静态图像任务转化为具有动态目标的视频任务,涵盖了从感知到认知的一系列时间理解技能。
静态到动态的转变(Static-to-Dynamic Method):
通过将静态图像任务增加时间上下文,例如将图像中的位置任务转换为视频中的移动方向任务,从而创建了一系列需要对整个视频进行推理的动态任务。
自动问答生成(Automatic QA Generation):
利用现有的视频基准测试和大型语言模型(LLMs),自动将视频注释转换为多项选择的问答对,用于评估MLLMs的性能。
选择了11个公共视频基准测试,并根据任务定义自动生成问题和答案选项。
数据筛选(Data Filtration):
为了增加视频的多样性并保证任务的时间敏感性,作者从现有的基准测试中精心选择了视频数据集,排除了过短或过长的视频片段,选择了中等时长的视频。
问题难度平衡(Question Difficulty):
为了平衡问题难度,作者设计了选择标准,确保问题既不过简单也不过复杂,以避免模型给出相似的响应。
答案选项生成(Answer Option Generation):
利用模板构建答案选项,或者使用LLM基于任务定义生成问题,并从现有注释中创建答案选项。
评估提示设计(Prompt Design for Evaluation):
为了强调MLLMs的时间敏感性,作者设计了详细的系统提示,鼓励模型仔细观察视频内容并回答问题。
videoCHat2
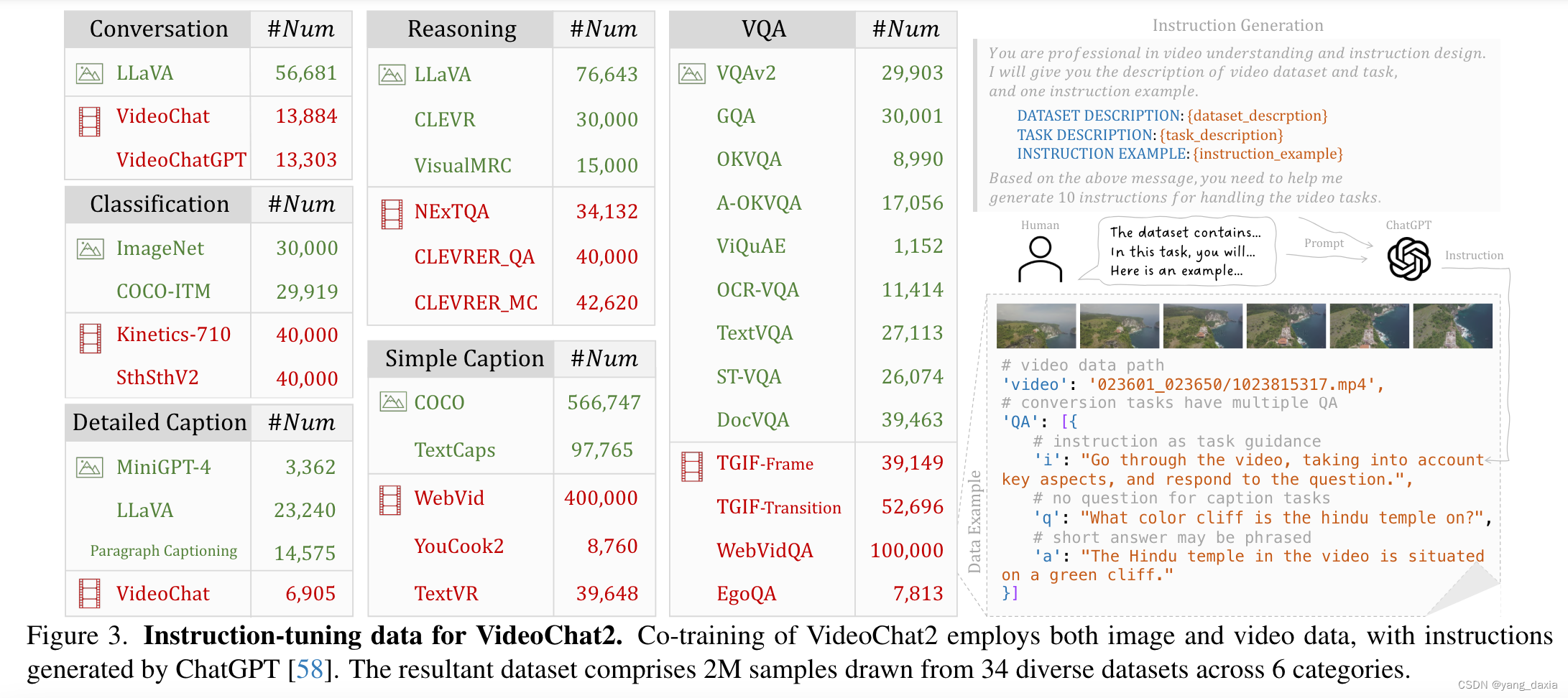
指令微调数据生成。通过chat
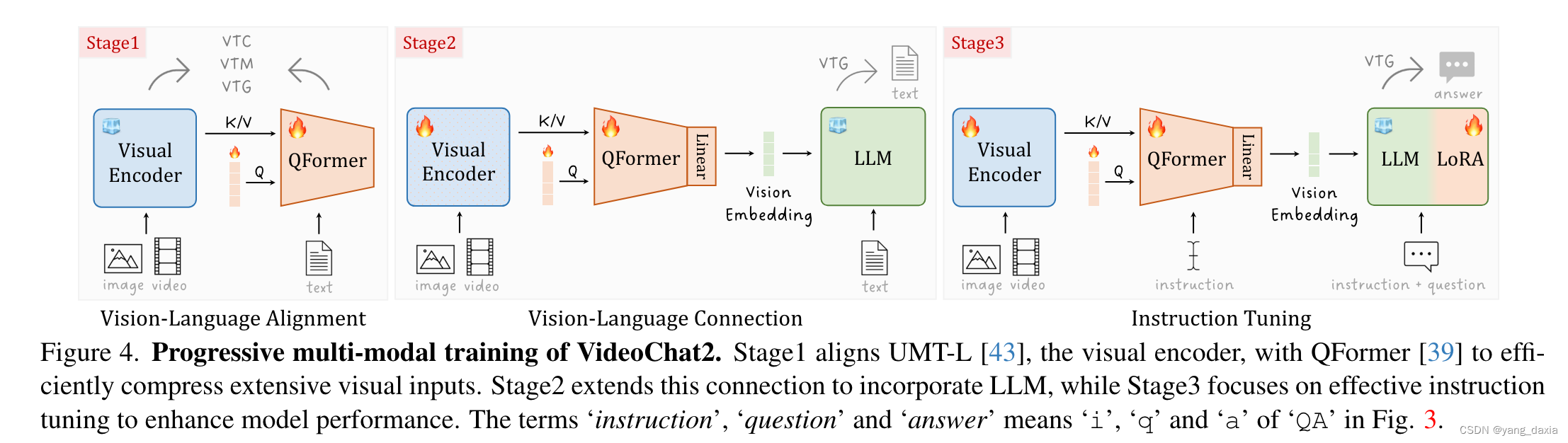
3阶段训练。视频语言对齐、视频语言链接、指令微调
声明:本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:【wpsshop博客】
推荐阅读
相关标签

