
- 12024年Web前端最新Vue项目中整合富文本编辑器,前端开发自学技巧_富文本编辑器 vue
- 2【FFmpeg】AVCodecContext结构体
- 3从零开始精通Onvif之历史与演变
- 4RabbitMQ详细安装步骤_yum rabbitmq
- 5多维点分布的均匀性评估方法(NDD和Voronoi 图法)_vo 随机分布
- 6【深度学习】猫狗识别TensorFlow2实验报告_猫狗识别实验报告
- 7毕业设计:基于机器学习的课堂学生表情识别系统 人工智能 python 目标检测_智能在线学习系统,上课表情识别毕设
- 8java switch语句 枚举_Java:不能在switch语句中使用泛型枚举
- 9卷积神经网络(CNN)理解
- 10C++中4种方式把字符串和数字连接起来_c++ 字符串拼接数字
从FPGA说起的深度学习(二)
赞
踩

这是新的系列教程,在本教程中,我们将介绍使用 FPGA 实现深度学习的技术,深度学习是近年来人工智能领域的热门话题。
在本教程中,旨在加深对深度学习和 FPGA 的理解。
用 C/C++ 编写深度学习推理代码
高级综合 (HLS) 将 C/C++ 代码转换为硬件描述语言
FPGA 运行验证

在上一篇文章中,谈到了深度学习是什么以及在 FPGA 上进行深度学习的好处。在本课程的后续文章中,我们将开始开发针对 FPGA 的深度学习设计。特别是,在本文中,我们将首先在 Python 上运行训练代码,并创建一个网络模型方便在后续 FPGA 上运行。
在后续文章中,我们将根据实际源码进行讲解。稍后将提供包括 FPGA 设计在内的所有代码。
要使用的数据集工具
MNIST 数据库
本课程针对的问题是通常称为图像分类的任务。在这个任务中,我们输出一个代表输入图像的标签。这里的标签例如是图像中物体的通用名称。
MNIST 数据库(http://yann.lecun.com/exdb/mnist/)是一个包含 0 到 9 的手写数字的数据集,并为每个手写数字定义了正确的标签 (0-9)。由于输入是一张28x28的灰度图,输出最多10个类,在图像分类任务中属于非常初级的任务。除了 MNIST 之外,主要的图像分类数据集包括CIFAR10(https://www.cs.toronto.edu/~kriz/cifar.html)和ImageNet(http://www.image-net.org/),并且往往会按上诉列出的顺序成为更难的问题。
MNIST 在许多深度学习教程中都有使用,因为它是一个非常简单的数据集。由于本课程的主要目的是在 FPGA 上实现深度学习,因此我们将创建一个针对 MNIST 的学习模型。
 MNIST 数据库——维基百科
MNIST 数据库——维基百科
PyTorch
PyTorch(https://pytorch.org/)是来自 Facebook 的开源深度学习框架,也是与来自 Google 的TensorFlow(https://www.tensorflow.org/)一起使用最频繁的框架之一。在本文中,我们将在 PyTorch 上学习和创建网络模型。
PyTorch安装参考官网步骤。我使用的 Ubuntu 16.04 LTS 上安装的 Python 3.5 不支持最新的 PyTorch,所以我使用以下命令安装了旧版本。
pip install torch==1.4.0 torchvision==0.5.0由于本文的重点不在于如何使用PyTorch,所以我将省略代码的解释,尤其是学习部分。如果有兴趣,建议尝试下面的官方教程,尽管它是英文的。
使用 PYTORCH 进行深度学习:60 分钟闪电战
https://pytorch.org/tutorials/beginner/deep_learning_60min_blitz.html
卷积神经网络
卷积神经网络 (CNN) 是一种旨在在图像任务中表现出色的神经网络。本文创建的网络模型是一个卷积神经网络,该网络由以下三层和激活函数的组合组成。
全连接层
卷积层
池化层
激活函数
下面概述了每一层的处理和作用。
全连接层
全连接层是通过将输入向量乘以内部参数矩阵来输出向量的过程。如果只说神经网络没有前言比如卷积,往往指的就是这个全连接层。
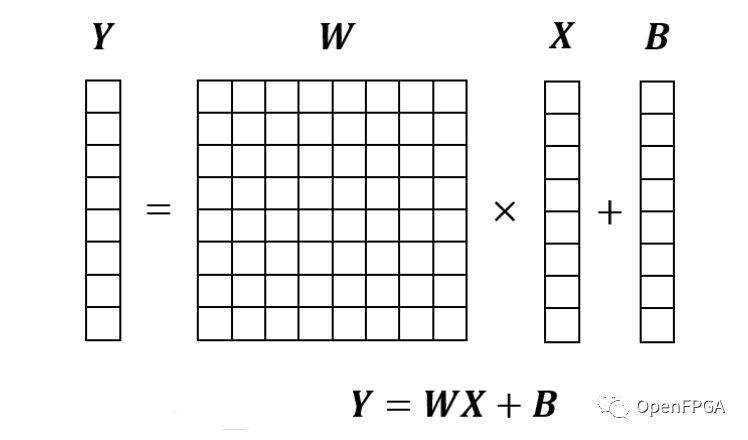
由于全连接层的输入是向量,所以无法得到图像中应该注意的与周围像素点的关系。在卷积神经网络中,全连接层主要用于将卷积层和池化层创建的压缩图像信息(特征)转换为标签数据(0-9)。
卷积层
卷积层是对图像进行卷积处理的层。如果熟悉图像处理,可能会称其为滤镜处理。
在卷积层中,对于输入图像中的每个像素,获取周围像素的像素值,每个像素值乘以一个数组(kernel),它是一个内参,求和就是像素值输出图像。这以图形方式表示,如下所示。
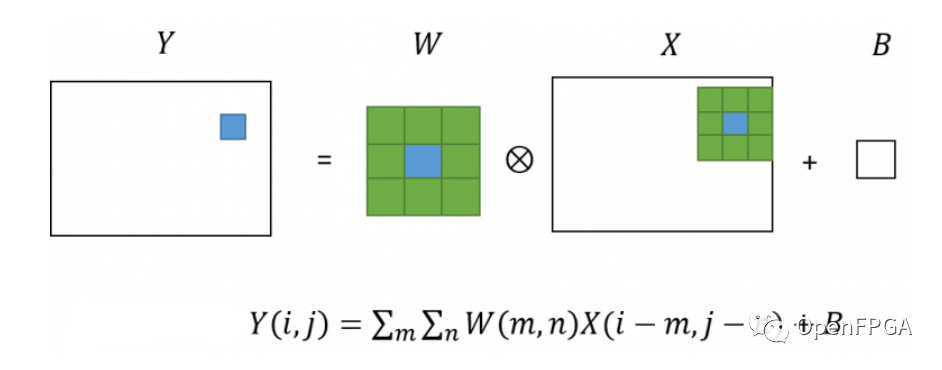
卷积神经网络的许多层都是由这个卷积层组成的,因为它以这种方式针对图像处理。
池化层
池化层是用于压缩由卷积层获得的信息的层。使用本次使用的参数,通过取图像中2x2块的最大值将图像大小减半。下图显示了最大值的减少处理。
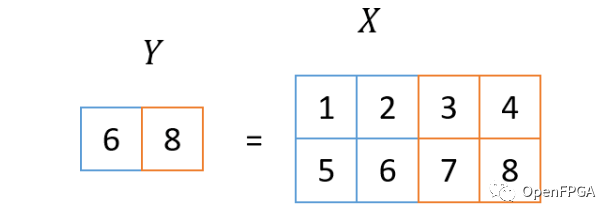
通过应用多个池化层,聚合图像每个部分的信息,并接近表示最终图像整体的标签信息。
激活函数
激活函数是一个非线性函数,插入在卷积层和全连接层之后。这是为了避免将实际上是线性函数的两层合并为一层。已经提出了各种类型的激活函数,但近年来 ReLU 是主要使用的激活函数。
ReLU 是 Rectified Linear Unit 的缩写。该函数会将小于0的输入值置为0,大于0的值原样输出。
创建网络模型
使用的网络模型是著名网络模型LeNet的简化版(http://yann.lecun.com/exdb/publis/pdf/lecun-98.pdf)。LeNet 是早期的卷积神经网络之一,和这个一样,都是针对手写识别的。
本文使用的模型定义如下。与原来的LeNet相比,有一些不同之处,例如卷积层的核大小减小,激活函数为ReLU。
- class Net(nn.Module):
- def __init__(self, num_output_classes=10):
- super(Net, self).__init__()
-
-
- self.conv1 = nn.Conv2d(in_channels=1, out_channels=4, kernel_size=3, padding=1)
-
- # 激活函数ReLU
- self.relu1 = nn.ReLU(inplace=True)
-
- #
- self.pool1 = nn.MaxPool2d(kernel_size=2, stride=2)
-
- # 4ch -> 8ch, 14x14 -> 7x7
- self.conv2 = nn.Conv2d(in_channels=4, out_channels=8, kernel_size=3, padding=1)
- self.relu2 = nn.ReLU(inplace=True)
- self.pool2 = nn.MaxPool2d(kernel_size=2, stride=2)
-
- # 全连接层
- self.fc1 = nn.Linear(8 * 7 * 7, 32)
- self.relu3 = nn.ReLU(inplace=True)
-
- # 全连接层
- self.fc2 = nn.Linear(32, num_output_classes)
-
- def forward(self, x):
-
- # 激活函数ReLU
- x = self.conv1(x)
- x = self.relu1(x)
-
- # 缩小
- x = self.pool1(x)
-
- # 2层+缩小
- x = self.conv2(x)
- x = self.relu2(x)
- x = self.pool2(x)
-
- # (Batch, Ch, Height, Width) -> (Batch, Ch)
- x = x.view(x.shape[0], -1)
-
- # 全连接层
- x = self.fc1(x)
- x = self.relu3(x)
- x = self.fc2(x)
-
- return x

使用netron(https://lutzroeder.github.io/netron/)可视化此模型的数据流如下所示:

按照数据的顺序流动,首先输入一张手写图像(28×28, 1ch),在第一个Conv2d层转换为(28×28, 4ch)的图像,通过ReLU变成非负的。
然后通过 Maxpool2d 层将该图像缩小为 (14×14, 4ch) 图像。随后的 Conv2d、ReLU、MaxPool2d 遵循几乎相同的程序,生成 (7×7, 8ch) 图像。将此图像视为7x7x8 = 392度的向量,应用两次全连接层最终将输出10度的向量。此 10 阶向量中具有最大值的元素的索引 (argmax) 是推断字符 (0-9)。
学习/推理
使用上述模型训练 MNIST。这里需要执行三个步骤:
加载训练/测试数据
循环学习
测试(推理)
首先,读取数据。PyTorch 带有一个预定义的 MNIST 加载器,我们用它来加载数据(训练集/测试集)。trainloader/testloader 是定义如何读取每个数据集中数据的对象。
- import torch
- import torchvision
- import torchvision.transforms as transforms
-
- # 2. 定义数据集读取方法
- #获取MNIST的学习测试数据
- trainset = torchvision.datasets.MNIST(root='./data', train=True, download=True, transform=transforms.ToTensor())
- testset = torchvision.datasets.MNIST(root='./data', train=False, download=True, transform=transforms.ToTensor())
-
- #数据读取方法的定义
- #1步骤的每个学习测试读取16张图像
- trainloader = torch.utils.data.DataLoader(trainset, batch_size=16, shuffle=True)
- testloader = torch.utils.data.DataLoader(testset, batch_size=16, shuffle=False)
现在数据读取已经完成,是时候开始学习了。首先,我们定义损失函数(误差函数)和优化器。在后续的学习中,我们会朝着损失值减小的方向学习。
- # 损失函数,最优化器的定义
- loss_func = nn.CrossEntropyLoss()
- optimizer = torch.optim.Adam(net.parameters(), lr=0.0001)
学习循环像这样:从trainloader读取输入数据(inputs),纠正标签(labels),通过网络得到输出(outputs),得到带有正确标签的error(loss)。
然后我们使用一种称为误差反向传播 (loss.backward()) 的技术来计算每一层的学习方向(梯度)。优化器使用获得的梯度来优化模型(optimizer.step())。这是一步学习流程,在此代码中,重复学习直到够 10 个数据集。
由于我们将使用 FPGA 进行推理处理,因此即使不了解此处描述的学习过程也没有问题。如果你对我们为什么这样学习感兴趣,请参考上一篇文章中一些通俗易懂的文献。
- # 循环直到使用数据集中的所有图像10次
- for epoch in range(10):
- running_loss = 0
-
- # 在数据集中循环
- for i, data in enumerate(trainloader, 0):
- # 导入输入批(图像,正确标签)
- inputs, labels = data
-
- # 零初始化优化程序
- optimizer.zero_grad()
-
- # 通过模型获取输入图像的输出标签
- outputs = net(inputs)
-
- # 与正确答案的误差计算+误差反向传播
- loss = loss_func(outputs, labels)
- loss.backward()
-
- # 使用误差优化模型
- optimizer.step()
- running_loss += loss.item()
- if i % 1000 == 999:
- print('[%d, %5d] loss: %.3f' %
- (epoch + 1, i + 1, running_loss / 1000))
- running_loss = 0.0
测试代码如下所示:该测试与学习循环几乎相同,但省略了学习的损失计算。scikit-learn我们还使用这里的函数来accuracy_score, confusion_matrix输出准确度和混淆矩阵。
- from sklearn.metrics import accuracy_score, confusion_matrix
-
- # 4.测试
- ans = []
- pred = []
- for i, data in enumerate(testloader, 0):
- inputs, labels = data
- outputs = net(inputs)
-
- ans += labels.tolist()
- pred += torch.argmax(outputs, 1).tolist()
-
- print('accuracy:', accuracy_score(ans, pred))
- print('confusion matrix:')
- print(confusion_matrix(ans, pred))
通过到目前为止的实施,可以在 PyTorch 上训练和推断 MNIST。当我在 i7 CPU 上实际运行上述代码时,该过程在大约 3 分钟内完成。日志在下面。
[n, m] loss: X这条线表示第n个epoch(使用数据集的次数)和学习数据集中第m个数据时的损失(错误)。可以看出,随着学习的进行,损失几乎接近于 0。即使是这种非常小的网络模型也可以成功学习。
测试准确率最终显示出足够高的准确率,达到 97.26%。接下来的矩阵是混淆矩阵(confusion_matrix),其中第i行第j列的值代表正确答案i和推理结果j。这次数据的准确性足够了,结果似乎没有什么明显的偏差。这一次,我们一次性得到了足够的准确率,但是我们在原来的开发中并没有得到我们想要的准确率,所以我们在这里回顾一下模型和学习方法。
- [1, 1000] loss: 1.765
- [1, 2000] loss: 0.655
- [1, 3000] loss: 0.475
- ...
- [10, 1000] loss: 0.106
- [10, 2000] loss: 0.101
- [10, 3000] loss: 0.104
- accuracy: 0.9726
- confusion matrix:
- [[ 973 0 1 0 0 2 0 2 2 0]
- [ 0 1128 2 1 0 0 2 0 2 0]
- [ 3 3 997 8 0 1 2 7 10 1]
- [ 1 0 6 968 0 12 0 5 10 8]
- [ 1 0 3 0 960 0 1 2 2 13]
- [ 3 1 0 5 0 870 2 0 7 4]
- [ 10 2 1 1 7 8 927 0 2 0]
- [ 1 3 9 0 1 0 0 1006 1 7]
- [ 5 1 1 12 4 3 3 8 927 10]
- [ 5 6 0 3 10 1 0 10 4 970]]
最后,使用以下代码保存模型。前者是从 PyTorch 重新评估的模型文件,后者用于在 PyTorch 的 C++ API(libtorch)上读取网络模型。
- # 5. 保存模型
- # 用于从PyTorch正常读取的模型文件
- torch.save(net.state_dict(), 'model.pt')
-
- # 保存用于从libtorch(C++API)读取的Torch Script Module
- example = torch.rand(1, 1, 28, 28)
- traced_script_module = torch.jit.trace(net, example)
- traced_script_module.save('traced_model.pt')
总结
在本文中,我们使用 MNIST 数据集作为学习目标来创建、训练和推断网络模型。
使用基于 LeNet 的轻量级网络模型,我们能够在 MNIST 数据集上实现良好的准确性。在下一篇和后续文章中,我们的目标是在 FPGA 上运行该模型,并在考虑高级综合(HLS)的情况下开始 C++ 实现。

