- 1sql自动发邮件功能_sql 发送邮件
- 2大数据——Python环境搭建及Python数据类型_数据搭平台python
- 3基于Android Studio和Gradle 的小米便签配置和安装
- 4【ChatGPT模型精调训练】AI 大模型精调 Fine-Tuning (微调)训练图文代码实战详解_fine-tune chatgpt模型
- 5CentOS 7 Docker方式安装 PHP,Mysql,phpmyadmin 过程记录
- 6【计算机视觉40例】案例09:答题卡识别
- 7【河海大学信息科学与工程学院主办,大咖组委会 | EI(核心),Scopus检索 | 往届均已完成EI检索】2024年第四届人工智能、自动化与高性能计算国际会议(AIAHPC 2024)
- 8android抓trace工具,Android trace文件抓取原理
- 9MySQL日期时间转换函数_mysql时间转换函数
- 10springboot宠物店管理系统tjtaa[独有源码]了解毕业设计的关键考虑因素_宠物店管理系统开发背景
【大数据之Kafka】十三、Kafka消费者生产经验之分区的分配及再平衡、数据积压和消费者事务_kafka分区消费
赞
踩
1 分区的分配及再平衡
一个consumer group中有多个consumer组成,一个 topic有多个partition组成,使用分区分配策略决定由哪个consumer来消费哪个partition的数据。
Kafka有四种主流的分区分配策略: Range、RoundRobin、Sticky、CooperativeSticky。
通过配置参数partition.assignment.strategy,修改分区的分配策略。默认策略是Range + CooperativeSticky。Kafka可以同时使用多个分区策略。
分区分配策略用于消费者组初始化流程中的消费者组中的消费者Leader制定消费方案。

1.1 Rang及再平衡
Range 是对每个 topic 而言的。
(1)首先对同一个 topic 里面的分区按照序号进行排序,并对消费者按照字母顺序进行排序。
(2)通过 partitions数/consumer数 来决定每个消费者应该消费几个分区。如果除不尽,那么前面几个消费者将会多消费 1 个分区。
缺点:
如果只是针对 1 个 topic 而言,C0消费者多消费1个分区影响不是很大。但是如果有N 多个 topic,那么针对每个 topic,消费者 C0都将多消费 1 个分区,topic越多,C0消费的分区会比其他消费者明显多消费N 个分区。容易产生数据倾斜。
案例:
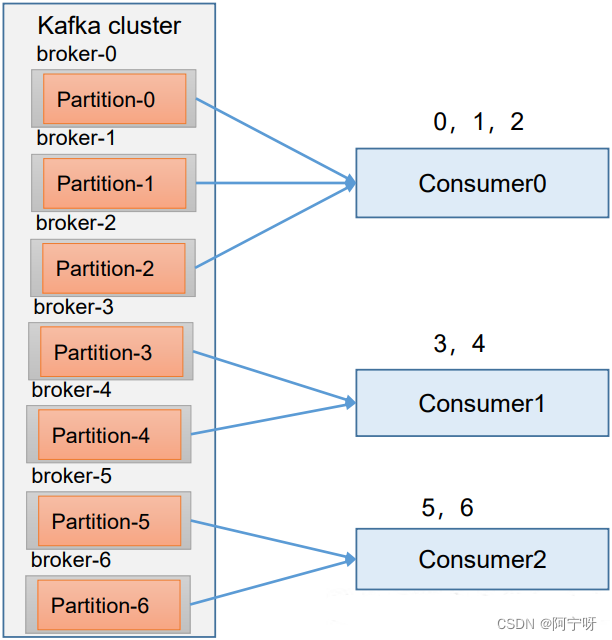
(1)现在有 7 个分区,3 个消费者,排序后的分区将会是0,1,2,3,4,5,6;消费者排序完之后将会是C0,C1,C2。
(2)7/3 = 2 余 1 ,除不尽,那么 消费者 C0 便会多消费 1 个分区。 8/3=2余2,除不尽,那么C0和C1分别多消费一个。
步骤:
(1)修改主题 first 为 7 个分区(分区数可以增加,但是不能减少)。
bin/kafka-topics.sh --bootstrap-server hadoop102:9092 --alter --topic first --partitions 7
- 1
(2)复制 CustomConsumer 类,创建 CustomConsumer2。这样可以由三个消费者 CustomConsumer、CustomConsumer1、CustomConsumer2 组成消费者组,组名都为“test”,同时启动 3 个消费者。

(3)启动CustomProducerCallback生产者,发送 500 条消息,随机发送到不同的分区。
Kafka 默认的分区分配策略就是 Range + CooperativeSticky,所以不需要修改策略。
package com.study.kafka.producer; import org.apache.kafka.clients.producer.*; import org.apache.kafka.common.serialization.StringSerializer; import java.util.Properties; public class CustomProducerCallback { public static void main(String[] args) throws InterruptedException { //0.创建 kafka 生产者的配置对象 Properties properties = new Properties(); //给 kafka 配置对象添加配置信息:bootstrap.servers properties.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG,"hadoop102:9092,hadoop103:9092"); // key,value 序列化(必须):key.serializer,value.serializer properties.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName()); properties.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG,StringSerializer.class.getName()); //1.创建 kafka 生产者对象 KafkaProducer<String, String> kafkaProducer = new KafkaProducer<>(properties); //2.调用 send 方法,发送消息 for (int i = 0; i < 500; i++) { kafkaProducer.send(new ProducerRecord<>("first", "test" + i), new Callback() { // 该方法在 Producer 收到 ack 时调用,为异步调用 @Override public void onCompletion(RecordMetadata recordMetadata, Exception e) { if (e == null) { // 没有异常,输出信息到控制台 System.out.println("topic:" + recordMetadata.topic() + " partition:" + recordMetadata.partition()); }else { // 出现异常打印 e.printStackTrace(); } } }); // 延迟一会会看到数据发往不同分区 Thread.sleep(2); } //3.关闭资源 kafkaProducer.close(); } }

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
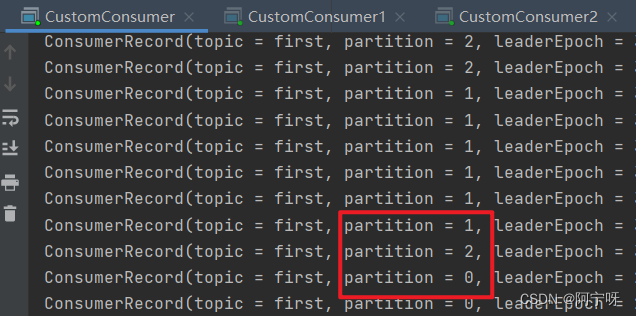
(4)观看 3 个消费者分别消费哪些分区的数据。
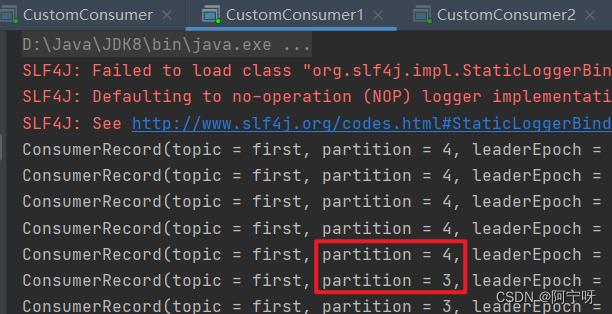
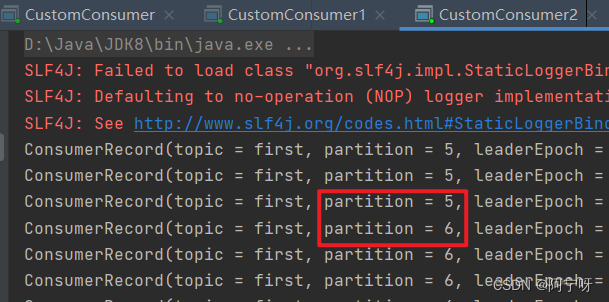
(5)停止掉 0 号消费者,快速重新发送消息观看结果(45s 以内,越快越好)。
1 号消费者:消费到 3、4 号分区数据。
2 号消费者:消费到 5、6 号分区数据。
0 号消费者的任务会整体被分配到 1 号消费者或者 2 号消费者。
说明:0 号消费者挂掉后,消费者组需要按照超时时间 45s 来判断它是否退出,所以需要等待,时间到了 45s 后,判断它真的退出就会把任务分配给其他 broker 执行。
(6)再次重新发送消息观看结果(45s 以后)。

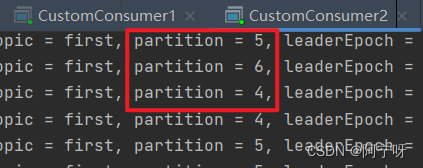
说明:消费者 0 已经被踢出消费者组,所以重新按照 range 方式分配。
1.2 RoundRobin 以及再平衡
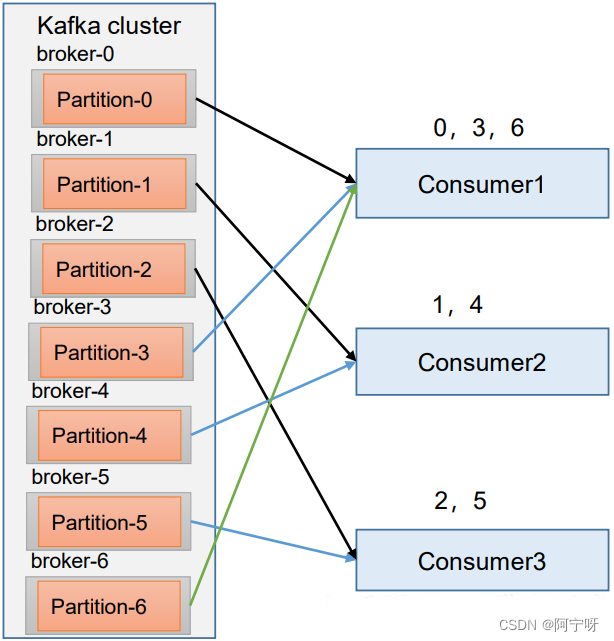
RoundRobin 针对集群中所有Topic而言。
RoundRobin 轮询分区策略,是把所有的 partition 和所有的consumer 都列出来,然后按照 hashcode 进行排序,最后通过轮询算法来分配 partition 给到各个消费者。
步骤:
(1)依次在 CustomConsumer、CustomConsumer1、CustomConsumer2 三个消费者代码中修改分区分配策略为RoundRobin。
// 修改分区分配策略
properties.put(ConsumerConfig.PARTITION_ASSIGNMENT_STRATEGY_CONFI G, "org.apache.kafka.clients.consumer.RoundRobinAssignor");
- 1
- 2
(2)重启 3 个消费者,重复发送消息的步骤,观看分区结果 。
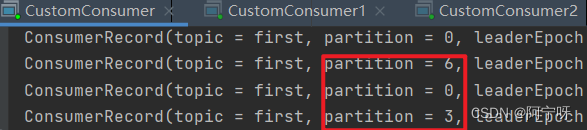
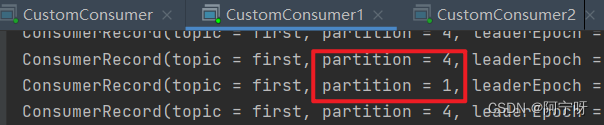

(3)停止掉 0 号消费者,快速重新发送消息观看结果(45s 以内,越快越好)。
1 号消费者:消费到 1、4 号分区数据。
2 号消费者:消费到 2、5 号分区数据。
0 号消费者的任务会按照 RoundRobin 的方式,把数据轮询分成 0 、3 和 6 号分区数据,分别由 1 号消费者或者 2 号消费者消费。
说明:0 号消费者挂掉后,消费者组需要按照超时时间 45s 来判断它是否退出,所以需要等待,时间到了 45s 后,判断它真的退出就会把任务分配给其他 broker 执行。
(4)再次重新发送消息观看结果(45s 以后)。
1号消费者:消费到 0、2、4、6 号分区数据。
2号消费者:消费到 1、3、5 号分区数据。
说明:消费者 0 已经被踢出消费者组,所以重新按照 RoundRobin 方式分配。
1.3 Sticky 以及再平衡
粘性分区定义:可以理解为分配的结果带有“粘性的”。即在执行一次新的分配之前,考虑上一次分配的结果,尽量少的调整分配的变动,可以节省大量的开销。
粘性分区是 Kafka 从 0.11.x 版本开始引入这种分配策略,首先会尽量均衡的放置分区到消费者上面,在出现同一消费者组内消费者出现问题的时候,会尽量保持原有分配的分区不变化。
步骤:
(1)修改分区分配策略为粘性,重启 3 个消费者,如果出现报错,全部停止等会再重启,或者修改为全新的消费者组。
// 修改分区分配策略
properties.put(ConsumerConfig.PARTITION_ASSIGNMENT_STRATEGY_CONFIG,"org.apache.kafka.clients.consumer.StickyAssignor");
- 1
- 2
(2)重启 3 个消费者,重复发送消息的步骤,观看分区结果 。
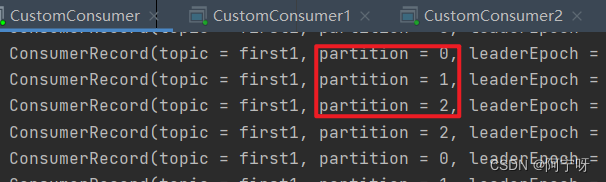
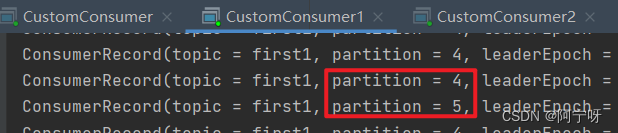
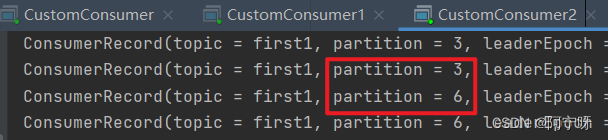
(3)停止掉 0 号消费者,快速重新发送消息观看结果(45s 以内,越快越好)。
1 号消费者:消费到 4、5 号分区数据。
2 号消费者:消费到 3、6 号分区数据。
0 号消费者的任务会按照粘性规则,尽可能均衡的随机分成 0、1 和 2 号分区数据,分别由 1 号消费者或者 2 号消费者消费。
说明:0 号消费者挂掉后,消费者组需要按照超时时间 45s 来判断它是否退出,所以需要等待,时间到了 45s 后,判断它真的退出就会把任务分配给其他 broker 执行。
(4)再次重新发送消息观看结果(45s 以后)。
1号消费者:消费到 0、2、3、6号分区数据。
2号消费者:消费到 1、4、5 号分区数据。
说明:消费者 0 已经被踢出消费者组,所以重新按照粘性方式分配。
2 消费者事务
如果想完成Consumer端的精准一次性消费,需要Kafka消费端将消费过程和提交offset过程做原子绑定。此时我们需要将Kafka的offset保存到支持事务的自定义介质( 比如 MySQL)。

3 数据积压(消费者如何提高吞吐量)
(1)如果是Kafka消费能力不足,则可以考虑增加Topic的分区数,并且同时提升消费组的消费者数量,消费者数= 分区数。(两者缺一不可)
(2)如果是下游的数据处理不及时:提高每批次拉取的数量。批次拉取数据过少(拉取数据/处理时间 < 生产速度),使处理的数据小于生产的数据,也会造成数据积压。