
热门标签
热门文章
- 1Android studio第一次导入项目遇到的问题,和解决方案_android studiothisprojectfilespecified
- 2fw150rm刷openwrt固件_N1刷openwrt固件至eMMC详细教程,非常适合小白!!!
- 3拓扑排序的算法实现_如何实现拓扑排序算法
- 4压缩pdf文件大小,如何压缩pdf_python 压缩pdf文件大小
- 52024年最新Hadoop分布式高可用HA集群搭建笔记(含Hive之构建)(1),java面试核心知识_hadoop高可用集群
- 6JCR一区级 | Matlab实现PSO-Transformer-LSTM多变量回归预测_matlab pso-transformer-lstm多变量回归预测
- 7Backend Qt5Agg is interactive backend. Turning interactive mode on.
- 8初学GitHub,如何提交代码_github 提交
- 9中国健康养生元宇宙未来风向
- 10linux 查看当前目录下占用空间命令
当前位置: article > 正文
Pod一直处于CrashLoopBackOff状态的排查思路_crashloopbackoff pod 状态
作者:爱喝兽奶帝天荒 | 2024-07-13 13:23:17
赞
踩
crashloopbackoff pod 状态
问题现象
一台宿主机上启动的Pod一直重启,describe报错信息如下
Pod sandbox changed, it will be killed and re-created.

原因分析
- Pod处于CrashLoopBackOff状态,第一想到的是Liveness probe failed或者OOM-kill; 测试Pod没有配置存活探测,查看对应机器也没有OOM-kill相关内核日志;
- 怀疑是否dockerd进程资源比较紧张,比如被死循环的容器一直消耗资源;查看机器资源都处于正常水平,排除Pod因为资源问题重启;
- 修改测试Pod的网络方式改为hostnetwork模式启动Pod,在问题机器上可以正常启动Pod,再次排除资源问题导致;
- SandboxChanged:怀疑是CNI 分配IP失败,导致循环分配,看起来比较像;于是查看网络插件canal Pod日志(hostnetwork模式)和kubelet日志查看具体过程;
以下是网络插件的日志信息,可以看到都是INFO日志,分配PodIP成功。
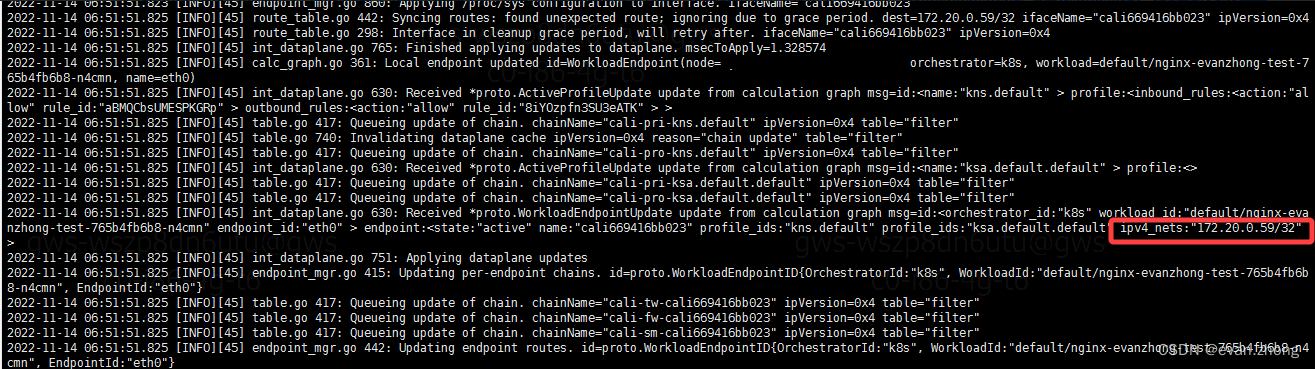
以下是kubelet对应的日志,也可以看到使用了对应的Pod IP并分配给container

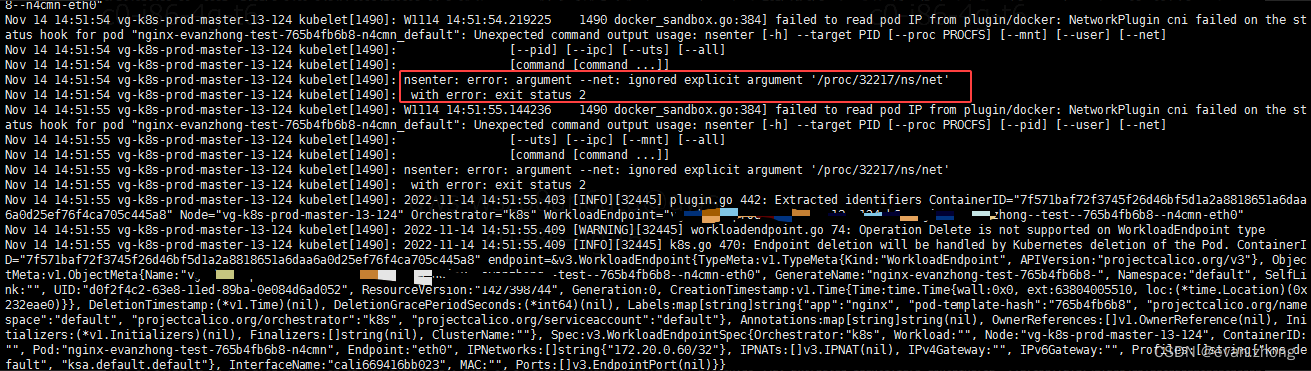
继续往下看kubelt的日志, 发现了一个可疑的error,使用nsenter 的某个参数失败,然后接下来是Endpoint will be hanled。 下一段日志又到了kubelet重新分配IP和container endpoint,这里和问题现象符合,docker ps可以看到有很多pause容器退出重建; 所以可以初步怀疑就是kubelet在创建Pod过程中卡在nsenter的使用方法上,对比nsenter的版本和help手册发现果然是该机器的nsenter问题。
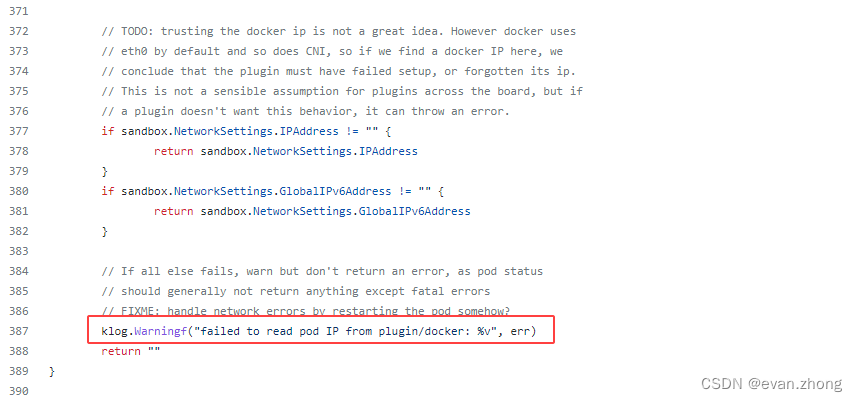
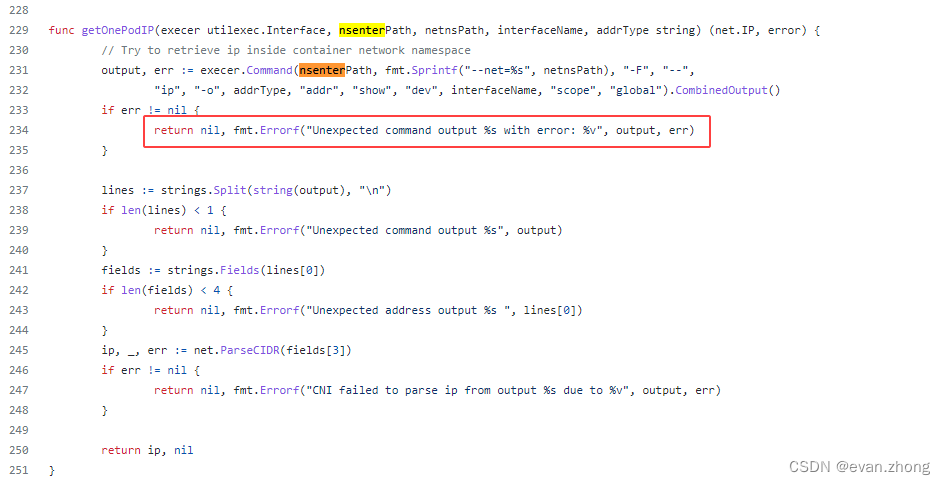
修复nsenter相关的bin文件后问题解决,也是第一次碰到,Pod创建过程中居然依赖nsenter工具,于是也去看了下对应的go代码,果然在分配IP后会使用nsenter检索IP,如果检索失败就会退出,对应的源码信息如下:
本文内容由网友自发贡献,转载请注明出处:【wpsshop博客】
推荐阅读
相关标签

