
- 1kodi连接远程服务器,私人影音服务器奶妈级入门篇(1)——Jellyfin for Kodi客户端设置方法...
- 22023华为od机试【金字塔】【微商的收入】Java
- 3NLP——基于Transformer实现机器翻译(日译中)_基于transformer的机器翻译
- 4【随笔】那些免费友好的遥感影像数据下载网站_遥感影像下载
- 5XFRM--IPsec协议的内核实现框架_linux xfrm
- 6软件测试个人总结_软件测试实训个人总结知乎
- 7Github的连接
- 8大规模底库搜索特征比对库Milvus(二),使用 , 减少reid评估时间_milvusclient.flush
- 9使用OpencvSharp实现人脸识别
- 10【android】android12蓝牙框架_android 蓝牙架构
手把手教你多种方式体验Qwen2最强开源大模型_如何使用qwen2
赞
踩
前几天看到新闻openai将开始限制来自非支持国家和地区的API流量,目前OpenAI的API已向161个国家和地区开放,中国内地和中国香港未包含其中。这对于中国使用openai的用户来说算是彻底断了念想,好在国内大模型近些日来迅猛发展,前段时间刚开源的阿里Qwen2蝉联开源大模型榜首,已经和chatgpt不相上下,这篇文章主要介绍如何多方式体验Qwen2。
1.Qwen2介绍+在线使用
qwen2官网介绍:https://qwenlm.github.io/zh/blog/qwen2/
在线体验:
主要亮点:
- 5个尺寸的预训练和指令微调模型, 包括Qwen2-0.5B、Qwen2-1.5B、Qwen2-7B、Qwen2-57B-A14B以及Qwen2-72B;
- 在中文英语的基础上,训练数据中增加了27种语言相关的高质量数据;
- 多个评测基准上的领先表现;
- 代码和数学能力显著提升;
- 增大了上下文长度支持,最高达到128K tokens(Qwen2-72B-Instruct)。
在2个评估数据集上进行验证:
M-MMLU: 来自Okapi的多语言常识理解数据集
MGSM:包含德、英、西、法、日、俄、泰、中和孟在内的数学评测。
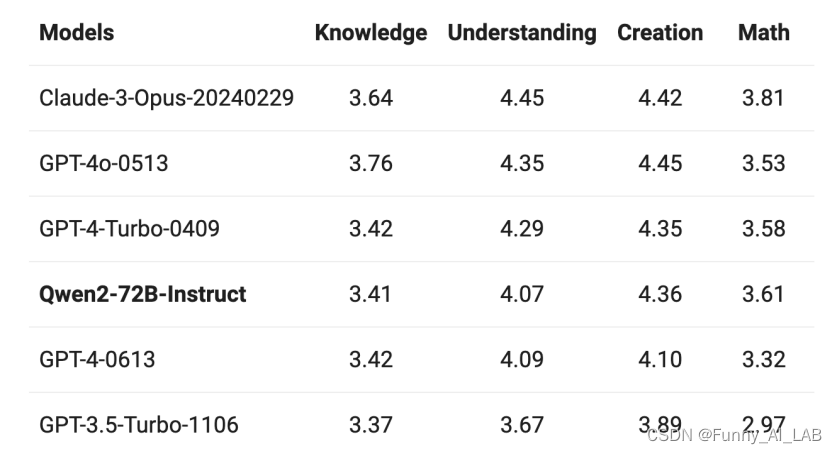 结果均反映了Qwen2指令微调模型突出的多语言能力。
结果均反映了Qwen2指令微调模型突出的多语言能力。
优化点:
通义千问技术博客披露,在Qwen1.5系列中,只有32B和110B的模型使用了GQA。这一次,所有尺寸的模型都使用了GQA,以便让用户体验到GQA带来的推理加速和显存占用降低的优势。针对小模型,由于embedding参数量较大,研发团队使用了tie embedding的方法让输入和输出层共享参数,增加非embedding参数的占比。
上下文长度方面,所有的预训练模型均在32K tokens的数据上进行训练,研发团队发现其在128K tokens时依然能在PPL评测中取得不错的表现。然而,对指令微调模型而言,除PPL评测之外还需要进行大海捞针等长序列理解实验。在使用YARN这类方法时,Qwen2-7B-Instruct和Qwen2-72B-Instruct均实现了长达128K tokens上下文长度的支持。
目前在多项权威榜单和测评中,Qwen2-72B成为开源模型排行榜第一名。
2. 本地部署
- 本地部署:使用 llama.cpp 和 Ollama 等框架在 CPU 和 GPU 上本地运行 Qwen 模型的说明。
- Docker:预先构建的 Docker 镜像可用于简化部署。
- ModelScope:推荐中国大陆用户使用,支持下载检查点并高效运行模型。
- 推理框架:使用 vLLM 和 SGLang 部署 Qwen 模型进行大规模推理的示例。
2.1 Ollama 使用
Ollama下载:https://ollama.com/download
官网下载安装成功,打开终端安装:ollama run qwen2:7b
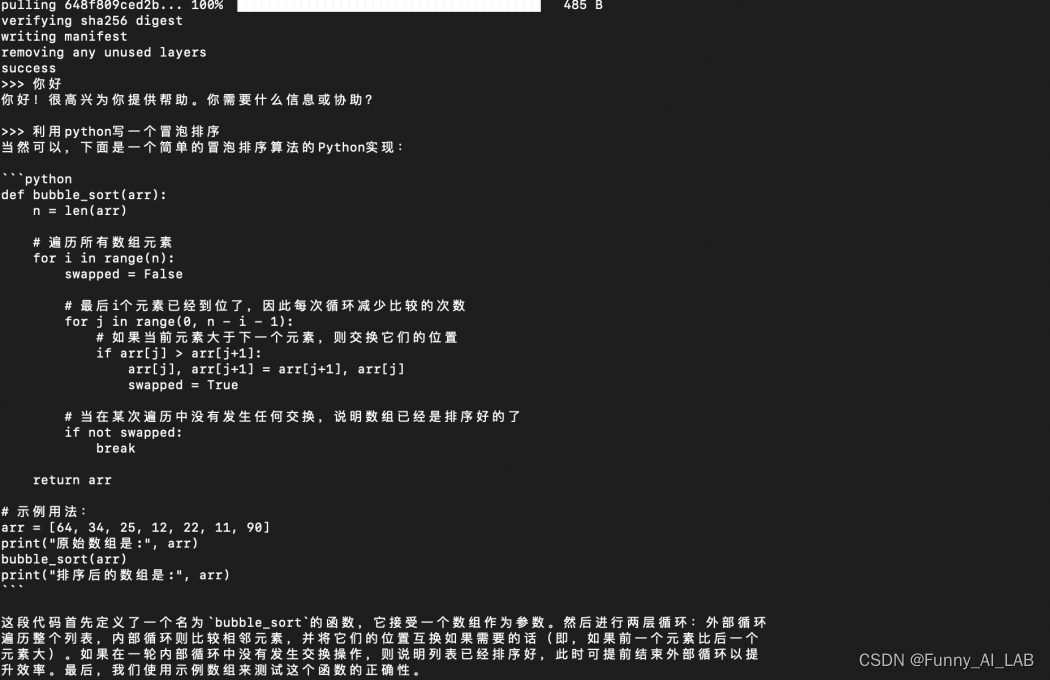
安装成功,测试使用,利用qwen2-7B写一个冒泡排序,速度感人
2.2 vllm部署
参考:deployment/vllm
使用 [vLLM]来部署 Qwen。它使用简单,速度快,具有最先进的服务吞吐量、使用 PagedAttention 高效管理注意键值内存、连续批处理输入请求、优化的 CUDA 内核等。
安装环境cuda11.8:
pip install vLLM>=0.4.0
pip install ray
- 1
- 2
- 3
Qwen2 代码支持的模型也受 vLLM 支持。vLLM 最简单的用法是离线批量推理:
from transformers import AutoTokenizer from vllm import LLM, SamplingParams # Initialize the tokenizer tokenizer = AutoTokenizer.from_pretrained("Qwen/Qwen2-7B-Instruct") # Pass the default decoding hyperparameters of Qwen2-7B-Instruct # max_tokens is for the maximum length for generation. sampling_params = SamplingParams(temperature=0.7, top_p=0.8, repetition_penalty=1.05, max_tokens=512) # Input the model name or path. Can be GPTQ or AWQ models. llm = LLM(model="Qwen/Qwen2-7B-Instruct") # Prepare your prompts prompt = "Tell me something about large language models." messages = [ {"role": "system", "content": "You are a helpful assistant."}, {"role": "user", "content": prompt} ] text = tokenizer.apply_chat_template( messages, tokenize=False, add_generation_prompt=True ) # generate outputs outputs = llm.generate([text], sampling_params) # Print the outputs. for output in outputs: prompt = output.prompt generated_text = output.outputs[0].text print(f"Prompt: {prompt!r}, Generated text: {generated_text!r}")

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
使用 vLLM 可以轻松构建兼容 OpenAI-API 的 API 服务,可以将其部署为实现 OpenAI API 协议的服务器。默认情况下,它会在 启动服务器。您可以使用和参数http://localhost:8000指定地址。运行以下命令:–host–port
python -m vllm.entrypoints.openai.api_server --model Qwen/Qwen2-7B-Instruct
- 1
使用创建聊天接口 与Qwen进行交流:
curl http://localhost:8000/v1/chat/completions -H "Content-Type: application/json" -d '{
"model": "Qwen/Qwen2-7B-Instruct",
"messages": [
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Tell me something about large language models."}
]
}'
- 1
- 2
- 3
- 4
- 5
- 6
- 7
或者使用python客户端:
from openai import OpenAI # Set OpenAI's API key and API base to use vLLM's API server. openai_api_key = "EMPTY" openai_api_base = "http://localhost:8000/v1" client = OpenAI( api_key=openai_api_key, base_url=openai_api_base, ) chat_response = client.chat.completions.create( model="Qwen/Qwen2-7B-Instruct", messages=[ {"role": "system", "content": "You are a helpful assistant."}, {"role": "user", "content": "Tell me something about large language models."}, ] ) print("Chat response:", chat_response)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
3. 云端部署
阿里云百炼于近期应用、模型双引擎全新升级,兼容LlamaIndex等开源框架,更具开放性的应用框架,更极致生态化的模型服务,降低推理成本,加速大模型应用落地
官网链接:https://www.aliyun.com/product/bailian

按照上面的教程选择部署模型
根据自己的需求进行选择,收费标准:
billing-for-alibaba-cloud-model-studio
4. 总结
对比几种使用方式:
| 部署方式 | 在线使用 | 本地部署 | 云端部署 |
|---|---|---|---|
| 优点 | 易于访问,无需复杂设置、成本效益,按需支付,自动更新,使用最新模型 | 数据隐私,数据本地存储定制性高,可按需优化<控制性强,完全控制模型运行和维护 | 可扩展性,易于资源扩展专业支持,包括技术支持和维护,灵活性,快速调整资源和服务 |
| 缺点 | 依赖网络,需要稳定网络数据隐私风险,数据需上传定制性有限,控制能力受限 | 硬件要求高,需强大GPU成本高,初始投资大维护要求,需技术能力 | 成本问题,持续的云服务费用数据隐私风险,数据需上传网络依赖,服务可用性依赖网络 |
大模型的在线使用、本地部署和云端部署各有其优缺点:
综合考虑,选择哪种部署方式取决于组织的具体需求、资源和优先级。例如,对于重视数据隐私和定制性的场景,本地部署可能更合适;而对于需要快速扩展和专业技术支持的场景,云端部署可能更有优势。在线使用则适合对成本敏感且不需要高度定制的用例。

