
- 1项目开发-工具-前端开发_前端开发工具项目
- 2小红书-社区搜索部 (NLP、CV算法实习生) 二面面经_cv岗面经
- 3uniapp navigateBack返回上一页携带参数_uni.navigateback携带参数
- 4设计模式简谈_设计模式 shape circle
- 5正点原子嵌入式linux驱动开发——STM32MP1启动详解
- 6大数据分析设计-基于Hadoop运动项目推荐系统_hadoop课程设计
- 7【Android Gradle】之一小时 Gradle及 wrapper 入门_android distribution wrapper
- 8大模型微调选型指南:我的企业需要微调或者训练一个自己的大模型吗?还是RAG更适合我?先说结论:微调duck不必_在通用大模型微调还需要训练吗
- 9【CSAPP】探究BombLab奥秘:Phase_1的解密与实战_sub $0x8,%rsp
- 10【保姆级教程】GPT4.0画画-生成绘本_gpt绘图
如何免费用 Qwen2 辅助你翻译与数据分析?
赞
踩
对于学生用户来说,这可是个好消息。

开源
从前人们有一种刻板印象——大语言模型里好用的,基本上都是闭源模型。而前些日子,Meta推出了Llama3后,你可能已经从中感受到现在开源模型日益增长的威力。当时我也写了几篇文章来介绍这个系列模型,例如这一篇《如何免费用 Llama3 70B 帮你做数据分析与可视化》,很受欢迎。

最近阿里推出了新一代的开源大语言模型 Qwen2。同样是一个系列 —— 从非常小不到 10 亿参数的模型,一直到 72B (也就是 720 亿)参数的中型模型。因为信息比较多,我干脆让 Perplexity 给我对 Qwen2 的信息做了个汇总。

Perplexity 说,Qwen2 系列模型规模大,多语言能力强,并且在编程、数学等领域提升非常明显,且支持超长上下文。最后这一点,我觉得它比 Llama 3 的表现要好。
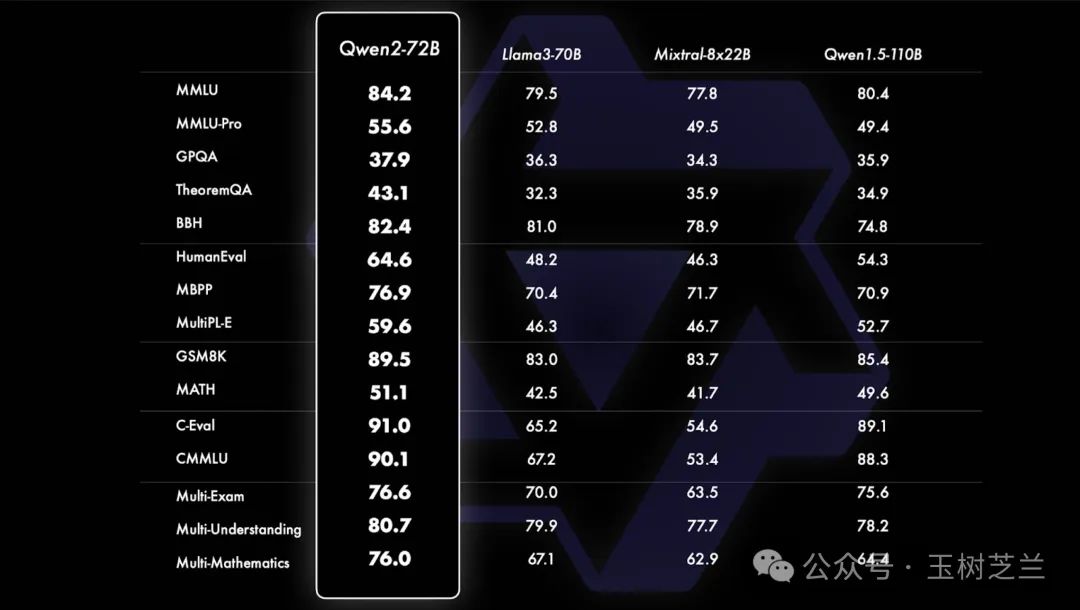
我这里拿了一张 Qwen2 发布会时的图,它展示了 Qwen2 的 72B 与 Llama3 的 70B 以及 Mixtral-8x22B 混合专家模型间的对比。Qwen2 相较于后者,在每一个指标上都有提升。
当然,我们不能光看数据对吧?这篇文章,咱们得动手实践获得一手认知。首先,咱们来试试本地运行。
尝试
考虑到本地机器计算能力限制,我们选一个小一点的模型,也就是 Qwen2 的 7B 模型。这里我使用 Ollama 来运行它。关于 Ollama 的介绍,可以参考这篇文章。
我们执行指令:
ollama run qwen2Ollama 会立即自动下载模型。
下载好后,你就可以直接跟它对话了。
我提的问题是:
帮我写个 Snake Game in Python。
你可能会问,为什么指令写得这么奇怪?你要么说中文,要么说英文,为什么中英文混用呢?
答案是我故意的因为Qwen2号称多语言能力比较强,所以我们先让它试试这种混用看效果怎么样。
测试结果来看,Qwen2 对中英文混合的 prompt 理解效果挺好。它不仅懂了我的意思,还直接开始基于 Pygame 来输出 Python 代码。

代码完整输出完后,Qwen2 还会告诉用户怎么用。

我于是先按照它的要求把 Pygame 安装上。

之后,我把 Qwen2 生成的代码贴到 Visual Studio Code 里面,再执行。
这是运行的效果。我试玩儿了好一会儿。
你不难发现,「人工智能」挺智能的,可以快速编出这样的程序;反倒是玩儿游戏的这家伙,看上去似乎不怎么智能 本文内容由网友自发贡献,转载请注明出处:https://www.wpsshop.cn/w/运维做开发/article/detail/827489
Copyright © 2003-2013 www.wpsshop.cn 版权所有,并保留所有权利。

