
- 1vue 获取服务端多个数据文件导出为一个zip文件_ant-design-vue 多个文件导出压缩包
- 2《昇思25天学习打卡营第三十四天|快速入门》
- 3数组遍历-滑动窗口算法(Sliding Window)精讲及解题案例
- 4智能图片降噪-Topaz Photo AI
- 5Keil&STM32C8T6——基于SPI的OLED屏显汉字_2.4寸spi屏幕取字模
- 6上手PB(2)_nanopb 数据类型
- 7【LLM】Windows本地CPU部署民间版中文羊驼模型(Chinese-LLaMA-Alpaca)踩坑记录_羊驼模型本地部署
- 8分布式文件系统fastdfs解析之二(配置)
- 9python语言在线编译器,python 在线编程工具_python在线编译器
- 10LeetCode707 设计链表
RaftKeeper v2.1.0版本发布,性能大幅提升!
赞
踩
本文作者:吴建超、李卓宇
RaftKeeper是一款高新能分布式共识服务,完全兼容Zookeeper但性能更出色,更多关于RaftKeeer参考Github,我们将RaftKeeper大规模应用到ClickHouse场景中,用于解决ZooKeeper的性能瓶颈问题,同时RaftKeeper也可以用于其它大数据组件比如HBase。
v2.1.0作为v2.0.0后的重要版本,引入了一系列新特性,包括异步创建snapshot。该版本的最大亮点在于性能优化:写请求性能提升11%,读写混合场景更是大幅提升了118%。本文将从工程细节的角度深入解析新版本的改进与优化。
一、性能优化效果
在性能测试中,我们使用了raftkeeper-bench工具,测试环境为三个节点组成的集群,每个节点配置为16核CPU、32GB内存和100GB存储空间。测试对象包括RaftKeeper v2.1.0、RaftKeeper v2.0.4和ZooKeeper 3.7.1,均采用默认配置。
测试分为两组:
第一组测试纯create操作的性能,create操作的value大小为100字节。结果显示,RaftKeeper v2.1.0相较于v2.0.4性能提升了11%,相较于ZooKeeper性能提升了143%。
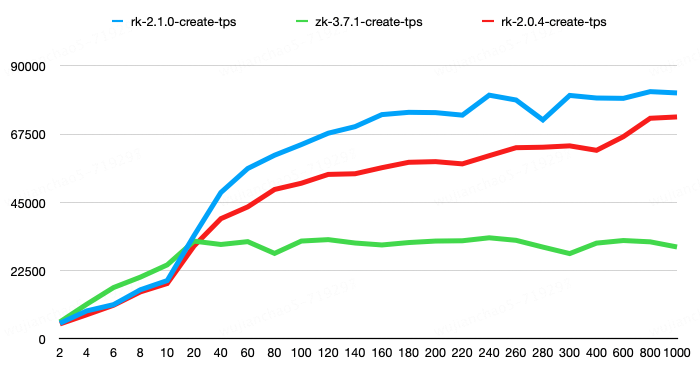
第二组请求比例为create-1%、set-8%、get-45%、list-45%、delete-1%。其中,list请求结果包含100个子节点,每个子节点大小为50字节;get、set、create请求的节点value大小为100字节。结果显示,RaftKeeper v2.1.0相较于v2.0.4性能提升了118%,相较于ZooKeeper性能提升了198%。
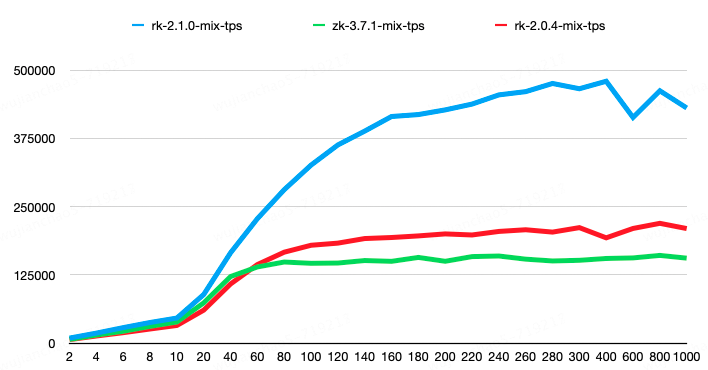
rk2.1.0版本在测试中avgRT和TP99指标均优于rk2.0.4,具体可以参考测试报告。
二、性能优化
接下来从工程细节的角度,介绍一些v2.1.0的优化点。
1. 响应并行序列化
RaftKeeper被我们广泛应用到ClickHouse中,下图是一个规模较大的RaftKeeper集群的火焰图,通过火焰图发现ResponseThread线程消耗不少CPU时间片,其中大概三分之一时间片用于序列化响应。

ResponseThread负责序列化响应并且转发给IO线程,它是一个单线程,串行执行序列化会增大延迟。我们可以把响应的序列化交给IO线程来做,以并发的方式提高吞吐。
同时可以看到sdallocx_default函数占用了不少时间片,该函数是jemelloc释放内存的函数,函数对于时间片的消耗没有问题,但是该操作在基于mutex的同步队列中执行会增加锁的时间。
- /// responses_queue是一个基于mutex的同步队列,在tryPop方法中释放response_for_session会增加lock的时间
- responses_queue.tryPop(response_for_session, std::min(max_wait, static_cast<UInt64>(1000)))
解决的方式是在tryPop方法前先释放response_for_session的内存空间。
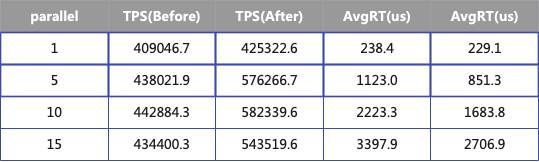
下面的表格展示了优化前后的性能指标,测试共有四组每组使用不同的并发度,其中响应大小为50bytes,当并发度为10的时候,TPS增加31%,AvgRT降低32%。
2. 优化List请求
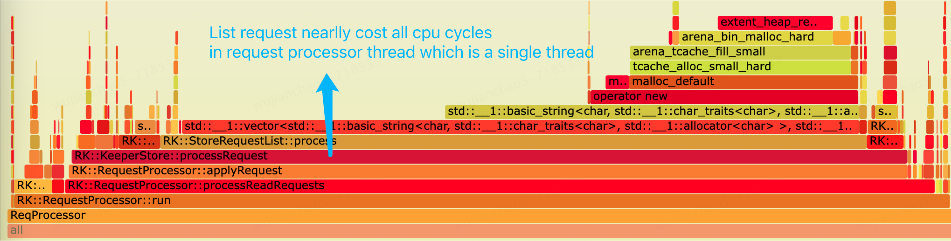
依然是同一个RaftKeeper集群,通过火焰图发现,List请求处理几乎消耗了request-processor线程所有的CPU时间片。在RaftKeeper的执行链路中request-processor负责处理用户的请求,它是一个单线程,所以比较容易成为瓶颈点。
通过火焰图可以发现两个瓶颈点:1.为字符串分配内存空间;2.插入vector。
List请求返回的结果是一个std::vector<string>动态数组,其内存layout如下图所示,每个成员是一个字符串,每个字符串需要分配一块动态内存用于保存数据,所以当字符串多的时候需要大量的动态内存分配。

一个很直观的优化思路,可以设计一个compact strings,数据采用紧凑的方式存储,在以下的设计中,采用两个连续内存空间,一个用于存储数据,一个用于存储offset,具体参考:CompactStrings实现。
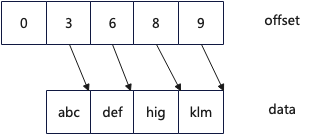
优化后从火焰图方面看List请求处理在CPU的占比从5.46%下降到3.37%,进行List请求的benchmark测试,TPS从45.8w/s 增长到 61.9w/s,同时TP99更低。
- 优化前:
- read requests 14826483, write requests 0, Read RPS: 458433, Read MiB/s: 2441.74, TP99 1.515 msec
-
- 优化后:
- read requests 14172371, write requests 0, Read RPS: 619388, Read MiB/s: 3156.67, TP99 0.381 msec.
3. 优化无用的系统调用
系统调用会引起用户态和内核态的上下文切换,往往系统调用函数会有比较大的开销,我们通过bpftrace对RaftKeeper进行了profile
- BPFTRACE_MAX_PROBES=1024 bpftrace -p 4179376 -e '
- tracepoint:syscalls:sys_enter_* { @start[tid] = nsecs; }
- tracepoint:syscalls:sys_exit_* /@start[tid]/ {
- @time[probe] = sum(nsecs - @start[tid]);
- delete(@start[tid]);
- @cc[probe] = sum(1);
- }
-
- interval:s:10{ exit(); }
- '
发现大量的getsockname和getsockopt系统调用占用了不少开销。
- Execution count:
- @cc[tracepoint:syscalls:sys_exit_getsockname]: 2878146
- @cc[tracepoint:syscalls:sys_exit_getsockopt]: 2821796
-
- Execution time (ns):
- @time[tracepoint:syscalls:sys_exit_getsockopt]: 3161677518
- @time[tracepoint:syscalls:sys_exit_getsockname]: 2647505715
这些系统调用本不该存在,经过排查发现是在打印日志的时候错误的进行了调用。
- const auto socket_name = sock.isStream() ? sock.address().toString() : sock.peerAddress().toString();
- LOG_TRACE(log, "Dispatch event {} for {} ", notification.name(), socket_name);
4. 线程池优化
下图是一次benchmark(读写4:6的比例)RaftKeeper的火焰图,进行性能瓶颈分析发现,发现request-processor线程的CPU时间片大部分时间(超过60%)消耗在条件变量等待的调用。

在RaftKeeper的主执行链路中request-processor线程负责处理用户请求,它的主要流程可以简单抽象为:1. 对于写请求,单线程处理;2. 对于读请求,通过线程池并发处理,然后调用request_thread->wait()阻塞等待所有读取请求完成。
- /// 1. process read-request by a thread pool
- for (RunnerId runner_id = 0; runner_id < runner_count; runner_id++)
- {
- request_thread->trySchedule(
- [this, runner_id]
- {
- moveRequestToPendingQueue(runner_id);
- processReadRequests(runner_id);
- });
- }
-
- /// 2. wait read request processing
- request_thread->wait();
-
- /// 3. process write-request in single thread
- processCommittedRequest(committed_request_size);

增加监控指标分别统计读和写请求的执行时间发现,在读请求和写请求数量几乎相同的情况下,读请求的处理延时是写请求的3倍。
因为每个请求的处理时间很短,到这里可以推测出,线程池任务调度的时间不可忽视,所以出现了性能下降。解决方式是去掉线程池,单线程处理读请求,以下benchmark是优化前后benchmark结果,TPS提升13%。
- 优化前:
- thread_size,tps,avgRT(microsecond),TP90(microsecond),TP99(microsecond),TP999(microsecond),failRate
- 200,84416,2407.0,3800.0,4500.0,8300.0,0.0
-
- 优化后:
- thread_size,tps,avgRT(microsecond),TP90(microsecond),TP99(microsecond),TP999(microsecond),failRate
- 200,108950,1846.0,3100.0,4000.0,5600.0,0.0
三、Snapshot优化
1. 异步snapshot
在RaftKeeper整个请求处理链路中,创建snapshot是在主链路中进行处理的,当数据量大的时候会长时间阻塞用户请求,造成请求超时、leader切换等引起服务不可用的问题,在我们线上场景中对于6000w的数据做snapshot需要180s。
为了解决以上问题,新版本中支持了异步snapshot,当需要创建snapshot的时候首先将整个DataTree拷贝一份,这一步在主线程中处理,然后在后台将拷贝的DataTree序列化到磁盘中。

采用这用方式6000w的数据做snaphot对用户的阻塞时间从180s降低到了4.5s,但是这种方案也有一些负面效果,需要额外消耗大于50%的内存。
为了进一步降低对用户的阻塞时间,对DataTree拷贝进行了进一步优化。DataTree拷贝其实是一个计算密集型的任务,所以可以采用向量化的方式,同时会遍历hashmap可以适当进行prefetch。
- inline void memcopy(char * __restrict dst, const char * __restrict src, size_t n)
- {
- auto aligned_n = n / 16 * 16;
- auto left = n - aligned_n;
- while (aligned_n > 0)
- {
- _mm_storeu_si128(reinterpret_cast<__m128i *>(dst), _mm_loadu_si128(reinterpret_cast<const __m128i *>(src)));
-
- dst += 16;
- src += 16;
- aligned_n -= 16;
- __asm__ __volatile__("" : : : "memory");
- }
- ::memcpy(dst, src, left);
- }
上面的拷贝函数基于SSE指令集,优化后DataTree拷贝时间从4.5s降低到3.5s。
2. Snapshot加载速度优化
RaftKeeper老版本中,启动服务之后snapshot加载速度比较慢,线上一个作为ClickHouse metadata存储的Raftkeeper有6kw的数据,在NVMe磁盘的服务器上加载snapshot需要180s,导致服务启动速度很慢。
加载snapshot主要分两步,第一步读取磁盘上的数据,反序列化成节点;第二步遍历DataTree并构建父子关系,其中第一步是并行的,第二步是单线程的。
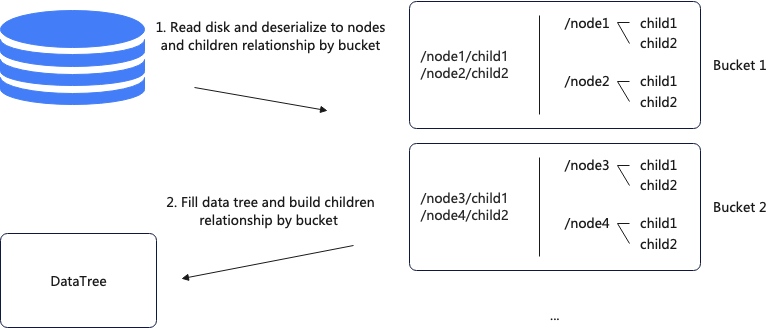
由于第二步是单线程执行,可以改成并行的方式,并行化改造的基础是DataTree是一个二层HashMap结构,改造后每个线程负责固定的bucket,这样避免了并发问题。具体流程为首先从磁盘读取数据并按照bucket的粒度存储节点和父子关系,然后填充DataTree并构建父子关系。
优化后加载snapshot时间从180s降低到99s,之后又通过锁优化、snapshot格式优化、减少数据拷贝等手段将时间降低到22s。
四、上线效果
我们选取线上一个对ZooKeeper请求量大的ClickHouse集群,在ClickHouse测的监控指标看QPS大概为17w/s,其中绝大部分为List请求。依次将其从ZooKeeper升级到RaftKeeper v2.0.4和v2.1.0,观察监控指标
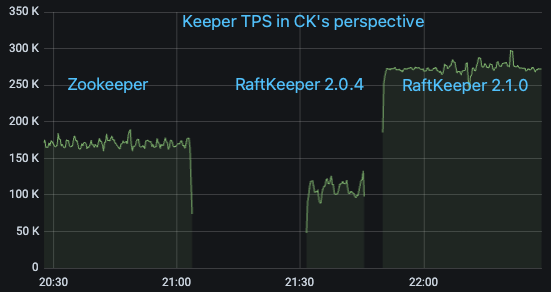
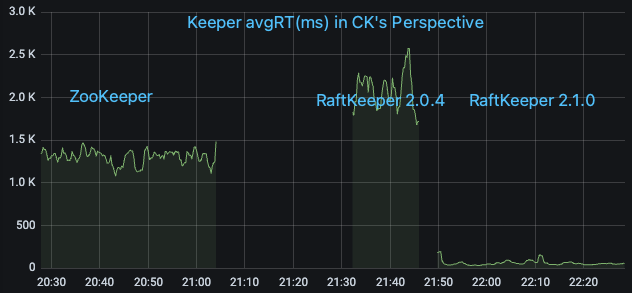
可以看到RaftKeeper v2.0.4的表现不及ZooKeeper(主要原因是该场景下绝大部分请求是list,v2.0.4对于list请求性能较差),但是v2.1.0有比较大幅的优势。
五、写在最后
在大规模的ClickHouse部署中,我们发现RaftKeeper显著提升了ClickHouse的导数吞吐量。如果你遇到类似的问题,可以尝试使用RaftKeeper。更多关于RaftKeeper v2.1.0版本的信息,请参考Release Notes。欢迎试用并贡献代码,如有任何问题,请通过社区联系我们。

