
- 1大数据知识框架体系总结梳理_大数据全栈知识体系
- 2栈(stack)栈的链式存储(链表)_栈的链式存储结构
- 3探索PVZToolKit:一款强大的植物大战僵尸辅助工具
- 4OpenCV 图像处理 轮廓检测基本原理_opencvfindcontours函数
- 5用Docker作为PaaS的替代方案是否完美无缺_redis docker paas
- 6工作三年,Android开发水平就这?(1)_三年开发真实水平
- 7DeepMind论文:深度压缩感知,新框架提升GAN性能_deep compressed sensing network - official pytorch
- 8JavaWeb-Springboot-文件上传_spring.servlet.multipart 配置
- 9Day2.不就是运算符吗!
- 10Ubuntu 20.04 OpenCV4.5.0 Qt 5.12.0_vwmare下麒麟系统qt5.12.0安装opencv
【LLM】Windows本地CPU部署民间版中文羊驼模型(Chinese-LLaMA-Alpaca)踩坑记录_羊驼模型本地部署
赞
踩
目录
前言
准备工作
Git
Python3.9
Cmake
下载模型
合并模型
部署模型
前言
想必有小伙伴也想跟我一样体验下部署大语言模型, 但碍于经济实力, 不过民间上出现了大量的量化模型, 我们平民也能体验体验啦~,
该模型可以在笔记本电脑上部署, 确保你电脑至少有16G运行内存
开原地址:GitHub - ymcui/Chinese-LLaMA-Alpaca: 中文LLaMA&Alpaca大语言模型+本地CPU部署
(Chinese LLaMA & Alpaca LLMs)
Linux和Mac的教程在开源的仓库中有提供,当然如果你是M1的也可以参考以下文章:
https://gist.github.com/cedrickchee/e8d4cb0c4b1df6cc47ce8b18457ebde0
准备工作
最好是有代理, 不然你下载东西可能失败, 我为了下个模型花了一天时间, 痛哭~
我们需要先在电脑上安装以下环境:
- Git
- Python3.9(使用Anaconda3创建该环境)
- Cmake(如果你电脑没有C和C++的编译环境还需要安装mingw)
Git
下载地址:Git - Downloading Package

下载好安装包后打开, 一直点下一步安装即可…
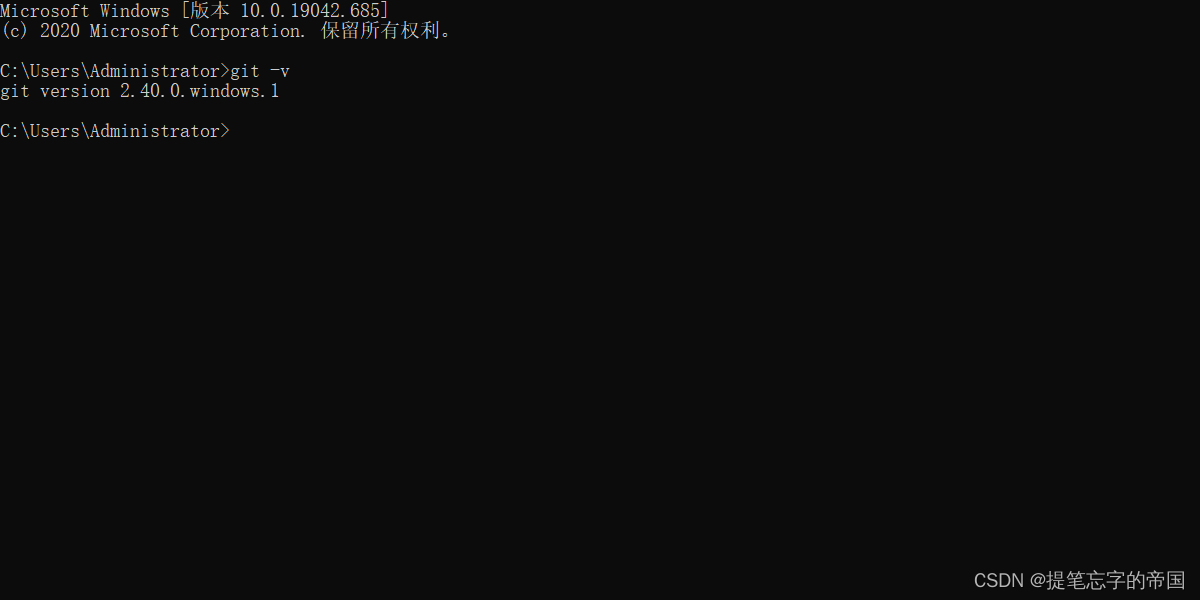
在cmd窗口输入以下如果有版本号显示说明已经安装成功
git -v
- 1
Python3.9
我这里使用Anaconda3来使用Python, Anaconda3是什么?
如果你熟悉docker, 那么你可以把docker的概念带过来, docker可以创建很多个容器, 每个容器的环境可能一样也可能不一样,
Anaconda3也是一样的, 它可以创建很多个不同的Python版本, 互相不冲突, 想用哪个版本就切换到哪个版本…
Anaconda3下载地址:Anaconda | Anaconda Distribution
安装步骤参考:





等待安装好后一直点next, 直到点Finish关闭即可
在cmd窗口输入以下命令, 显示版本号则说明安装成功
conda -V
- 1

接下来我们在cmd窗口输入以下命令创建一个python3.9的环境
conda create --name py39 python=3.9 -y
- 1
–name后面的py39是环境名字, 可以自己任意起, 切换环境的时候需要它
python=3.9是指定python版本
添加-y后就不需要手动输入y去确认安装了

查看有哪些环境的命令:
conda info -e
- 1

激活/切换环境的命令:
conda activate py39
- 1
要使用哪个环境的话换成对应名字即可

进入环境后你就可以在这输入python相关的命令了, 如:

要退出环境的话输入:
conda deactivate
- 1
当我退出环境后再查看python版本的话会提示我不是内部或外部命令,也不是可运行的程序
或批处理文件。如:

Cmake
这是一个编译工具, 我们需要使用它去编译llama.cpp, 量化模型需要用到, 不量化模型个人电脑跑不起来, 觉得量化这个概念不理解的可以理解为压缩, 这种概念是不对的,
只是为了帮助你更好的理解.
在安装之前我们需要安装mingw, 避免编译时找不到编译环境, 按下win+r快捷键输入powershell
输入命令安装scoop, 这是一个包管理器, 我们使用它来下载安装mingw:
这个地方如果没有开代理的话可能会出错
iex "& {$(irm get.scoop.sh)} -RunAsAdmin"
- 1
安装好后分别运行下面两个命令(添加库):
scoop bucket add extras
scoop bucket add main
- 1
- 2
- 3
- 4
输入命令安装mingw
scoop install mingw
- 1
到这就已经安装好mingw了, 如果报错了请评论, 我看到了会回复
接下来安装Cmake
安装参考:



安装好后点Finish即可
下载模型
我们需要下载两个模型, 一个是原版的LLaMA模型, 一个是扩充了中文的模型, 后续会进行一个合并模型的操作
- 原版模型下载地址(要代理):https://ipfs.io/ipfs/Qmb9y5GCkTG7ZzbBWMu2BXwMkzyCKcUjtEKPpgdZ7GEFKm/
- 备用:nyanko7/LLaMA-7B at main
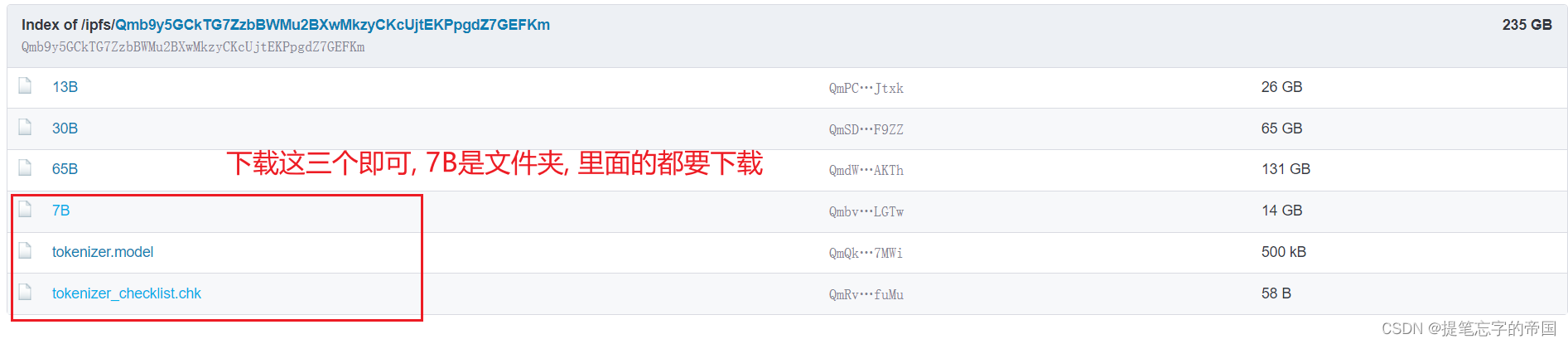
- 扩充了中文的模型下载:
建议在D盘上新建一个文件夹, 在里面进行下载操作, 如下:
在弹出的框中分别输入以下命令:
git lfs install
git clone https://huggingface.co/ziqingyang/chinese-alpaca-lora-7b
- 1
- 2
- 3
- 4
这里可能会因为网络问题一直失败…一直重试就行, 有别的问题请评论, 看到会回复
合并模型
终于写到这里了, 累~
在你下载了模型的目录内打开cmd窗口, 如下:

这里我先说下这图片中的两个目录里文件是啥吧
先是chinese-alpaca-lora-7b目录, 这个目录一般你下载下来就不用动了, 格式如下:
chinese-alpaca-lora-7b/
- adapter_config.json
- adapter_model.bin
- special_tokens_map.json
- tokenizer_config.json
- tokenizer.model然后是path_to_original_llama_root_dir目录, 这个文件夹需要创建, 保持一致的文件名, 目录内的格式如下:
path_to_original_llama_root_dir/
- 7B/ #这是一个名为7B的文件夹
- checklist.chk
- consolidated.00.pth
- params.json
- tokenizer_checklist.chk
- tokenizer.model
自行按照上面的格式存放
打开窗口后需要先激活python环境, 使用的就是前面装Anaconda3
# 不记得有哪些环境的先运行以下命令
conda info -e
# 然后激活你需要的环境 我的环境名是py39
conda activate py39
- 1
- 2
- 3
- 4
- 5
切换好后分别执行以下命令安装依赖库
pip install git+https://github.com/huggingface/transformers
pip install sentencepiece==0.1.97
pip install peft==0.2.0
- 1
- 2
- 3
- 4
- 5
执行命令安装成功后会有Successfully的字眼
接下来需要将原版模型转HF格式,
需要借助[最新版
Copyright © 2003-2013 www.wpsshop.cn 版权所有,并保留所有权利。

