
- 1操作系统---第三章内存管理---虚拟内存管理---应用题_缺页中断后访问内存还是访问快表
- 2全文检索、数据挖掘、推荐引擎系列2---异步服务实现
- 3干货分享!CynosDB for PostgreSQL 架构浅析
- 4基于R语言的Meta分析【全流程、不确定性分析】方法与Meta机器学习技术应用
- 5RecyclerView包含多种布局实现_recyclerview多种布局
- 6petaLinux常用命令汇总_petalinux 命令
- 7【云原生 | Kubernetes 系列】dubbo架构_k8s部署dubbo服务
- 8mysql所支持的比较运算符_MySQL比较运算符一览表(带解析)
- 9Linux限制可通过SSH登录到服务器的IP——hosts.allow
- 10Autodl配置环境记录_autodl miniconda环境
Unity中基于Gpu Instance进行大量物体渲染的实现与分析(一)_unity culling group
赞
踩

图 一个使用gpu instance绘制4000棵树的场景
在3D渲染中,尤其是现代3D游戏中,我希望能够绘制越来越多的场景物体,这对于设备(尤其是移动端)的性能是个极大的考验,对于新一代的渲染api,都逐渐支持了Gpu Instancing技术,这对于大量相同物体的绘制提供了一个新的方案,在最新的unity5中也提供了对gpu instance 的支持,我尝试在unity5中利用gpu instance 技术来表现大量的植被,并对其性能进行了分析,以探索在3D手游中gpu instance的应用的可行性。
关于Gpu Instance
Gpu Instance是一种用来提高渲染大量物体效率的技术,随着手游游戏品质需求的提升,我需要在场景里绘制越来越多的物体,这里面主要涉及两个方面的性能瓶颈,一是cpu对gpu提交数据的次数(包括设置数据buffer,渲染状态以及调用对渲染原语的绘制即drawcall),二是gpu上的绘制(包括顶点处理和像素绘制),随着场景物体的提升,cpu和gpu的压力都会上升。目前在一些典型的3D游戏的制作中,我们的经验值是全屏不超过10万个顶点和200个draw call左右,不然对中端机器会有一定压力。
为了解决场景绘制效率这个问题,主要有以下几种优化方案:
static batching: 即静态合批,静态合批的原理即化整为零,将多个场景物体预先合成一个大的物体进行绘制,unity5的实现就是整合成一个大的vbo,而不整合IBO,一次性提交vbo给gpu,然后并不是把整个vbo都绘制,而是每次需要绘制其中某个某些物体时改变IBO,选择大vbo上的某一段进行绘制。静态合批可以将多个小物体的绘制合并成一个大物体的绘制,减少对渲染状态的改变,它一次并行绘制多个物体,理论上是最快的绘制方法,不过最大的缺点是因为合成新的大vbo需要耗费额外的大量内存,同时不能渲染动态物体,因为合并vbo的时候已经确定顶点数据了,顶点数据不能更改(例如unity5对LOD合批的实现也是讲所有层次的lod都预先合并进去),另外一个vbo的大小是有限制的,如果物体数量过多,也会被拆成多个绘制。
dynamic batching:动态合批,可以解决对顶点数据有变化的物体的合批,它动态的合并vbo进行提交,组建vbo的时间有消耗,为了减少这个消耗,unity对动态合批的vbo大小有限制,以致于很小顶点数的物体才有可能被动态合批。
vertex constant instancing:Instancing 是不同于batching的另一种方案,它的原理是对于模型一致的物体,只提交原始的模型的vbo给gpu,然后将每个物体不同的属性单独抽出来组成buffer发给gpu,在显卡中根据这一份vbo和每个物体不同的属性来绘制多个物体,即一次提交,在gpu上绘制多个,对于大量同样模型的物体绘制是一个很好的方案。vertex constant的instancing是利用顶点常量属性来存储这些per instance attributes,但是也需要一个大的vbo存储所有未经顶点变换的相同的n个原顶点数据,在shader里面读取不同的vertex constant内容绘制不同的instance
gpu instancing:这是最新渲染api提供的一种技术,如果绘制1000个物体,它将一个模型的vbo提交给一次给显卡,至于1000个物体不同的位置,状态,颜色等等将他们整合成一个per instance attribute的buffer给gpu,在显卡上区别绘制,它大大减少提交次数,它在不同平台的实现有差异,例如gles是将per instance attribute也当成一个vbo提交,然后gles3.0支持一种per instance步进读取的vbo特性,来实现不同的instance得到不同的顶点数据,这种技术对于绘制大量的相同模型的物体由于有硬件实现,所以效率最高,最为灵活,避免合批的内存浪费,并且原则上可以做gpu skinning来实现骨骼动画的instancing。
Unity5中实现instance
unity5里面加入了对gpu instance的支持,而我们的一个项目中由于考虑到大量植被的表现,正好可以使用这个技术来提高渲染性能。
unity中提供了两种使用gpu instance的机制,自动和手动:
对于自动,需要使用unity 标准的standar 或surfaceshader,然后在mat下面的instacne那里打勾,然后unity在条件合适的情况下自动instance,但是注意这种限制非常多,如不能static batch,不能liaghtmap,不能改变mat,不能带动作,不能cull,等等,非常难,详见https://docs.unity3d.com/Manual/GPUInstancing.html
对于手动,通过使用Graphics.DrawMeshInstanced或者Graphics.DrawMeshInstancedIndirect这些底层api。
由于unity自动的instance不稳定且不能lightmap等等,于是我们的实现方案是自己用底层api去实现instance,并且自己去实现了支持lightmap和culling的instance。
对lightmap的支持的实现:首先lightmap的实现是要能够在shader中走unity的gi流程,并提供lightmap和lightmap的位置来采样lightmap,unity的instance不负责提供lightmap图,也不负责走lightmap的那套gi,所以这里要做这样几样工作:首先要在绘制带instance的时候,将lightmap图传入shader,然后在shader中自己写gi代码来接这个lightmap对其采样,当然还要把每个instance不同的lightmap位置数据即一个vector4做成per instance atribute传到渲染api里
对于culling的支持的实现:unity的instance 不负责剪裁,可是我们不希望把那些我们看不到的东西也渲染,于是我们使用了unity的底层culling api即cullinggroup,我们通过为每个instance绘制的对象抽象成一个包围盒,传递给culling group,就会从unity得到这个物体当前可视情况的通知,在通知中做相应的显示隐藏操作
对于lod的支持:我们希望带lod group的物体也能良好的被instance,于是我们通过预先处理场景里所有带lod group的物体,组织成我们能够理解的不同距离下的模型,然后结合cullinggroupapi传过来的距离来实现lod的支持。
其他:我们还要实现一个instance 渲染的管理器,来动态的管理每个时刻需要进行instance的物体,把他们按类型分成几个组,交给gpu,在这个过程中,还要一些小的细节,比如为了减少overdraw,我们也会为一个instance组里面的物体做简单的基于距离的排序,让物体从近及远绘制。为了减少对per instance attribute的数组的频繁分配和更改,我们预先申请一个定长的数组等
我们实现了一套支持lightmap,culling以及lod的instance渲染方法
性能测试
我们希望通过实际的测试来了解对于大规模植被的渲染instance相对batching能够有多少的性能提升,以及在物体数量变化情况下性能的提升变化,以希望能够得到对instance和batching两种技术运用的一些经验数据。
测试环境:pc平台,场景中放置4种不同的树,每种树放置大量,简单直线光照,standard渲染,为了防止动态合批影响结果,关闭动态合批,为了尽肯能减少对帧率影响,关闭垂直同步,所有的树木有三层lod,其中最底层lod相同。
下面是几组测试结果
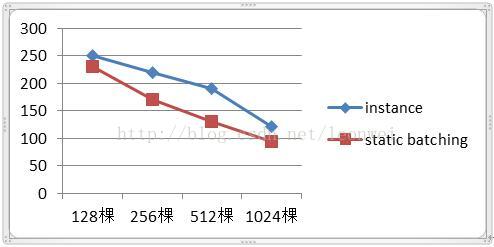
1) 随着树的数量升高最低fps的变化
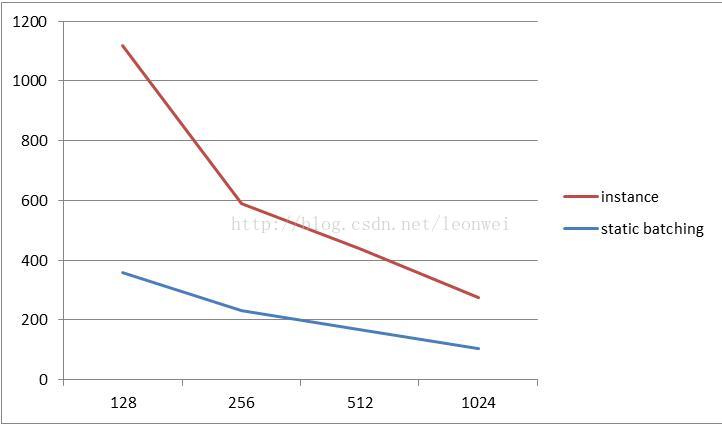
2) 随着树的数量升高最高fps的变化
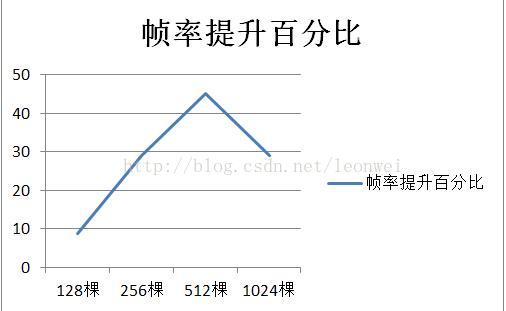
3) 随着树木数量升高instance相比batching的帧率提高百分比
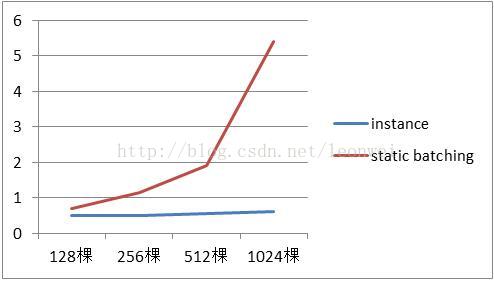
4) 随着树木的数量升高cpu上renderthread的所花时间变化
5) 随着树木的数量升高drawcall的变化
6) 随着随着树木的数量升高setpass的变化
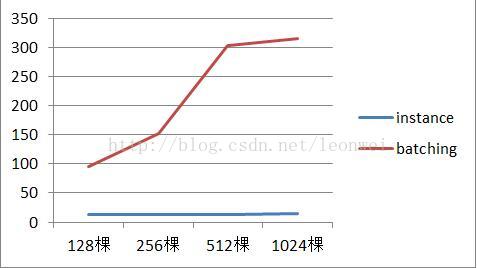
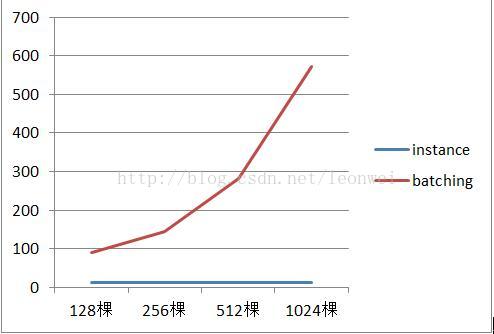
7) 随着随着树木的数量升高场景内存的变化
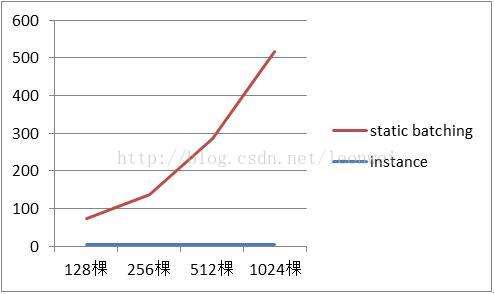
我们的测试结论
1) 在大量重复物体的绘制上,在各种指标和树木的数量上,instance都明显优于静态合批
2) 从帧率上,我们发现两种方式帧率都会随着渲染物体增加而降低帧率,但是在512棵树之内,instance对batching的帧率提升比随数量而升高,超过512这个比例有下降,可能说明在512树之内,drawcall是比较大的瓶颈,即cpu瓶颈很大,这时instance提升明显,超过一定数量,瓶颈会更多转移到gpu短的像素绘制,cpu有很多时间用来等到gpu,这时候instance的提升作用会降低。
3) 渲染时间上看,instance即使在1024棵树的时候,也几乎和128棵树相差不多,因为cpu需要做的事情,绘制100棵和1棵差别不大,但是batching会大幅上升
4) 两个关键指标draw call 和setpass上看,instance几乎不会随着数量增加而增加,而batching虽然也会对vbo合并,但是受制于一个vbo的大小,当物体过多时,合批将会部分失效,被迫拆成几个vbo,这样dc也会上升
5) 从内存上看,instance在绘制100和1000棵树占用的场景内存是一致的,都大约3M,只是树木的原始mesh,但是batching带来的内存占用是显著的,到1024棵树时已经需要大约500多m内存了,这在手机上几乎是不可能的,因为batching采用的策略需要把所有的渲染物体预选合并成一个大vbo来减少drawcall
6) Instancing对超大量物体的容忍度极高,我们可以看到文章开头的图片是我们绘制4000棵数的时候,instancing的帧率仍然可以维持在70-80帧,render time不变,而同样情况下batching的fps只有7帧。
7) 综上,我们得出更简单的三条结论:物体数量中等时,instance节省内存的意义更大,数量很多时,提升帧率的意义更大,数量逆天时,instance可以容忍的极限很高,然而无论怎样物体数量越少越好。不过各种技术的选择也都存在一个度,对于那些面数很少或者重复数量不多的静态的东西,就完全没有使用instance的必要了,因为如果能用一个static batching完成的绘制效率反而是更高的。static baching原理上毕竟是一次提交一次绘制,而instancing是一次提交,但是是顺序执行在硬件上的多次绘制。我们认为物体的重复数量必须达到一个static baching(大约6万多个顶点)无法容纳的程度或者基于更加节省内存的考虑才有必要使用gpu instancing。
可以看到,我们通过在unity中基于gpu instance 技术,可以对于植被这种需要大量渲染但是种类有限的对象,可以提高他们的渲染性能,并且当重复的数量达到一定程度时,instance相比batching相比可以节省内存,并且对数量的容忍度非常高,对于性能有限的移动设备是一种很好的选择。
下一步
目前只解决了静态物体的gpu instancing,我也正在尝试在gpu上实现骨骼的skinning来最终实现对带有骨骼动画对象的instancing,来用于大规模角色的绘制。

