
- 1IPSec-VPN 的配置与管理_ike策略组中,加密算法使用3des、摘要算法使用md5、group dh算法组使用dh2、身份认
- 2LeetCode 371. 两整数之和_leetcode 371 两整数之和 c语言
- 3linux 自定义 文件系统,已解决: petalinux自定义文件系统问题 - Community Forums
- 4Centos 8 替换镜像源_centos8换源
- 5入门HTML(含常见标签)—附实现案例_html案例
- 6利用python制作自己的小游戏,超简教程_python做游戏
- 7学生成绩智能分析系统—教师端的设计与实现_学生成绩管理系统教师端
- 8YOLOv5代码解析——train.py
- 9基于Python爬虫福建福州酒店数据可视化系统设计与实现(Django框架) 研究背景与意义、国内外研究现状
- 10python logistic 多标签,python中多类logistic回归的特征选择
【论文笔记】YOLOv7:Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors
赞
踩
前言
最近真的是一刻也不敢停下来,日子一天天的在减少,越来越焦虑了。写的虽然很多,但或者这也导致我很多博文内容质量都不够精,哭哭┭┮﹏┭┮
YOLOv7是去年出的,或说这一两年YOLO大家族迭代也太快了,我去年这会儿YOLO才第五代,今年就第八代了。之前的一个项目里面也用到了YOLOv7,YOLOv7很多地方都和v5很像,这一篇我会着重去讲一下v7的创新点。

论文: YOLOv7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors
代码:mirrors / WongKinYiu / yolov7
1. YOLOv7的主要贡献
- 模型重参数化
最早出现这一思想实在RepVGG中,YOLOv7将此方法引入到了网络架构中。 - 标签分配策略
YOLOv7的标签分配策略采用的是YOLOv5的跨网格搜索,以及YOLOX的匹配策略。 - E-ELAN网络结构
一种新的网络架构,主打一个高效。 - 辅助头训练
增加训练成本,同时不影响推理时间,因为辅助头只出现在训练过程中。
2. 网络架构
2.1 网络图总览
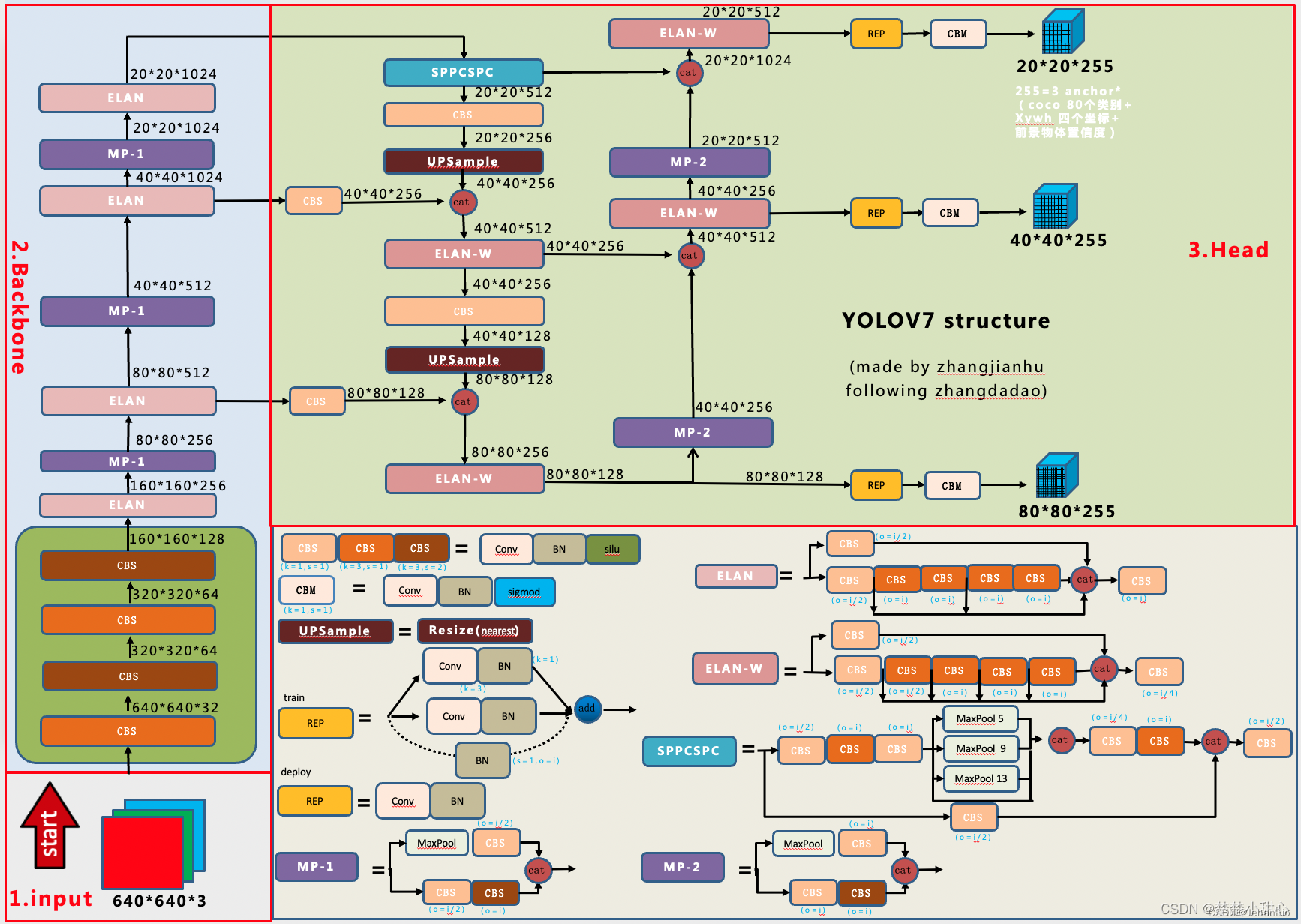
这里的网络图是引入的江小皮不皮的图片,感谢这位博主!
2.2 CBS模块
这里的CBS就说Conv+BN+Silu,注意图中不同颜色的CBS说明卷积核大小和步长不同。
- 1*1的卷积主要用来改变通道数
- 3*3的卷积,步长为1,主要用来特征提取,不会改变大小。
- 3*3的卷积,步长为2,用来下采样。
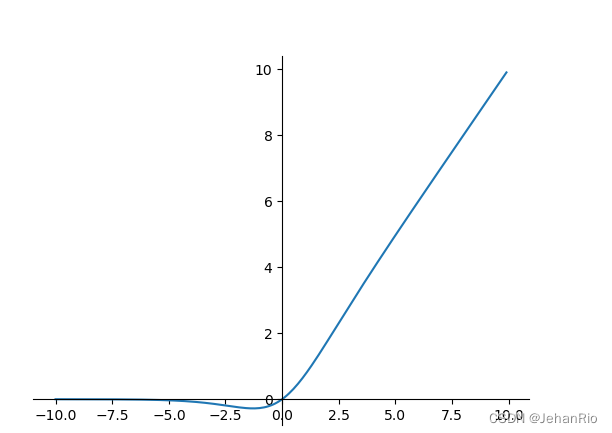
这里的激活函数Silu:f(x)=x⋅σ(x)
2.3 CBM
和CBS一致,只是改了激活函数,一般用在Detect层。
卷积核为1*1,步长也为1。
2.4 MP
关于这个MP,作者秉承着我全都要的原则,左边采用了MaxPooling,右边用stride=2下采样后,进行concat。
3. ELAN
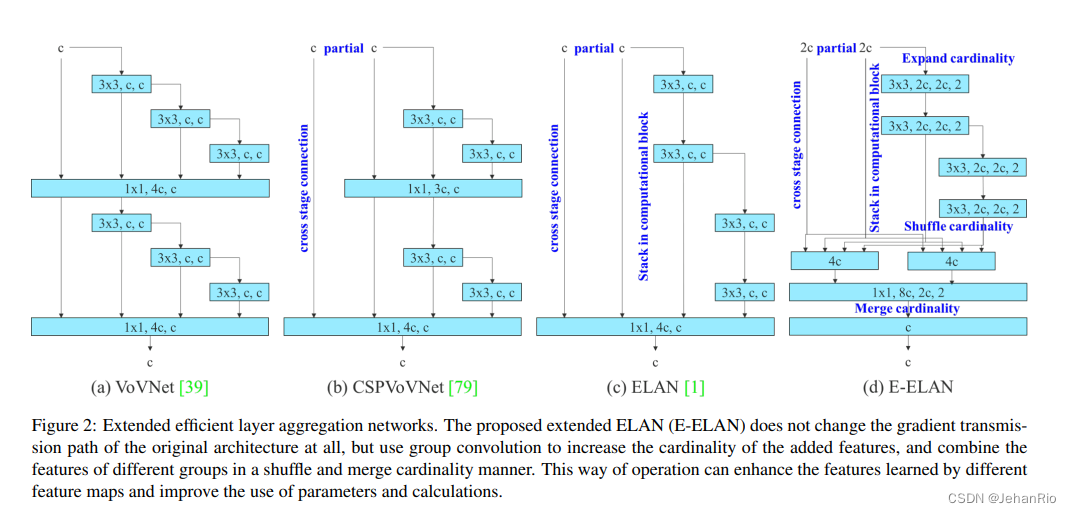
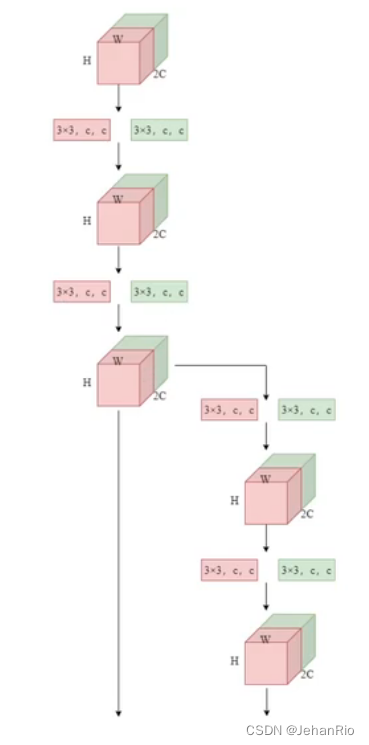
这里插入的是论文中经典的一张图片。
这里提到了4个网络,这里主要讲讲ELAN。ELAN是一个高效的网络模块,它通过控制最短和最长的梯度路径,使网络能够学习到更多的特征,并且具有更强的鲁棒性。
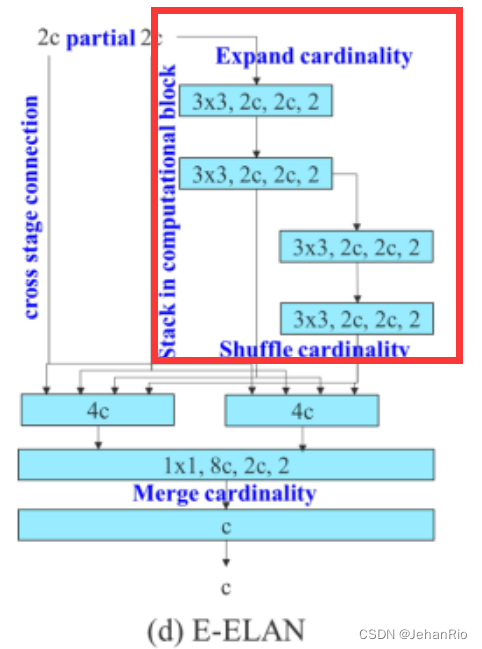
在论文中提到:通过控制最短最长的梯度路径,更深的网络可以有效地学习和收敛。在本文中,我们提出了基于 ELAN 的扩展 ELAN(E-ELAN)。E-ELAN就是把ELAN扩展一份,做分组卷积,把输出相加。
在此基础上,YOLOv7提出了E-ELAN。
E-ELAN 使用了 expand、shuffle、merge cardinality 来实现对 ELAN 网络的增强(数据增强方法),E-ELAN 仅仅改变了 computation block 的结构,transition layer 的结构没有改变。
具体是怎么实现的呢?
- 首先,使用 group convolution 来增大 channel 和 computation block(所有 computation block 使用的 group 参数及 channel multiplier 都相同)
- 接着,将 computation block 得到的特征图 shuffle 到 g 个 groups,然后 concat,这样一来,每个 group 中的特征图通道数和初始结构的通道数是相同的
- 最后,将 g 个 group 的特征都相加
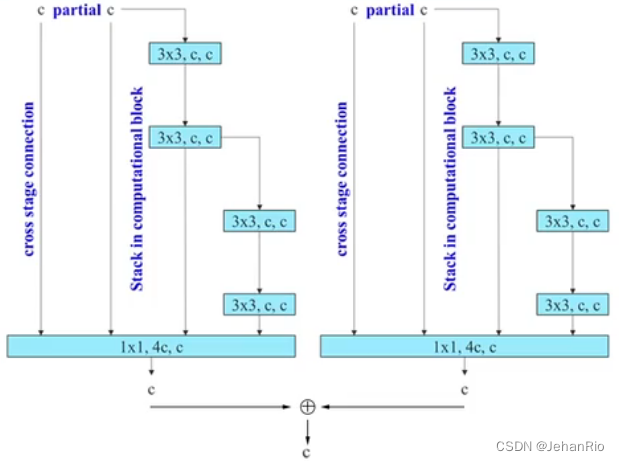
分组卷积可以减少参数量
假设常规卷积的参数是 C in × K × K × C out C_{\text {in }} \times K \times K \times C_{\text {out }} Cin ×K×K×Cout
那么分组卷积的参数就是 C in × K × K × C out C in G × K × K × C out G × G = C in × K × K × C out G C_{\text {in }} \times K \times K \times C_{\text {out }}\frac{C_{\text {in }}}{G} \times K \times K \times \frac{C_{\text {out }}}{G} \times G=\frac{C_{\text {in }} \times K \times K \times C_{\text {out }}}{G} Cin ×K×K×Cout GCin ×K×K×GCout ×G=GCin ×K×K×Cout
没错,ELAN是之前就有,YOLOv7的创新点是提出了E-ELAN。E-ELAN只有在和yolov7-e6e.yaml文件中使用到。
所以他这里的涉及有几个优点:
- 更好的特征提取:从不同网络层提取特征学习;
- 更稳定的模型学习能力:梯度路径设计策略直接确定并传播信息以更新权重到每个计算单元,因此所设计的架构可以避免训练期间的退化;
- 更高效的推理速度:可以在不增加额外复杂架构的情况下实现更高的精度。
绿色部分就是ELAN。
4. 基于级联的模型缩放
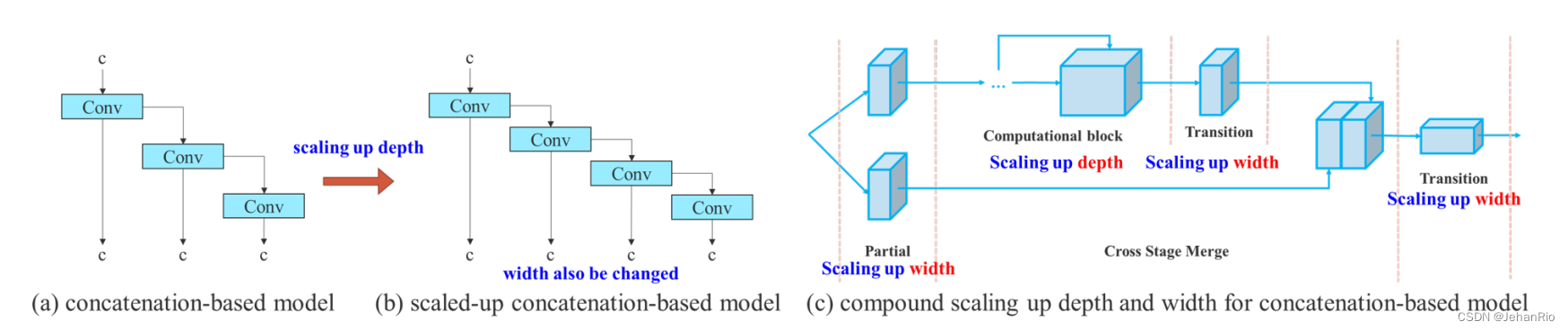
模型缩放的主要目的是调整模型的某些属性,并生成不同比例的模型,以满足不同推理速度的需要,YOLOv5也是这样。然而,如果将这些方法应用于基于串联的架构,我们会发现当对深度进行放大或缩小时,紧接在基于连接的计算块之后的平移层(translation layer)的入度将减小或增加,如图(a)和(b)所示。
从图中可以看出,当对模型深度加深的时候,网络的宽度也改变了。这种现象将导致后续传输层的输入宽度增加。所以作者提出了©中的网络。在执行模型缩放时,只需要缩放计算块中的深度,传输层的其余部分则使用相应的宽度缩放。
基于级联的模型缩放方法是一个复合模型缩放方法,当缩放一个计算块的深度因子时,同时也要计算该块输出通道的变化。然后,对过渡层以相同的变化量进行宽度因子缩放,这样就可以保持模型在初始设计时的特性,并保持最优结构。
5. RepVGG
RepVGG是采用VGG风格搭建的,即简单美,只采用3x3卷积和1x1卷积还有ReLU激活函数,但是采用了重参数化技术(re-parameter),即训练时使用复杂的结构训练,推理时用简单的卷积做推断,因此叫做RepVGG。
具体可以看这篇:结构重参数化:利用参数转换解耦训练和推理结构
简单来说,结构重参数化就是用一个结构的一组参数转换为另一组参数,并用转换得到的参数来参数化(parameterize)另一个结构。只要参数的转换是等价的,这两个结构的替换就是等价的。
至于推理证明这里先按下不表,先挖个坑,后面来填补。感兴趣的同学可以看下这篇:结构重参数化之二:RepVGG

A图是ResNet结构,最上面的部分的identity采用了1×1卷积,而RepVGG大体结构与ResNet相似
B图是RepVGG训练时结构,借鉴了ResNet的residual block的结构,具体包括3×3、1×1、shortcut三个分支。
- 当输入输出的维度不一致,即stride=2时,则只有3×3、1×1两个分支
- 当输入输出的维度一致时,在后三层卷积中不仅有1×1的identity connection,还有一个无卷积的直接进行特征融合的
identity connection,即直接将原图相加
C图是RepVGG测试时结构,会把这些连接全部去掉,就变成了一个单一的VGG结构,这种操作也被称为训练与预测的解耦合。
但是YOLOv7的作者发现,这样就破坏了ResNet的残差结构和DenseNet的concat,这样就会导致精度下降。比如下图a中,不带残差结构,可以直接替换成b。但是对于c这种带残差的,效果就很会差。所以像d这种,当一个带有残差或concat的卷积层被重参数的卷积所取代时,应该不存在 identity connection。
于是作者使用无identity connection的RepConv(RepConvN)来设计规划重参化卷积结构,经过实验得出以下是可行的(只替换上面的卷积为RepConv,或者使用RepConvN结构(去掉了恒等连接)),如下图所示:
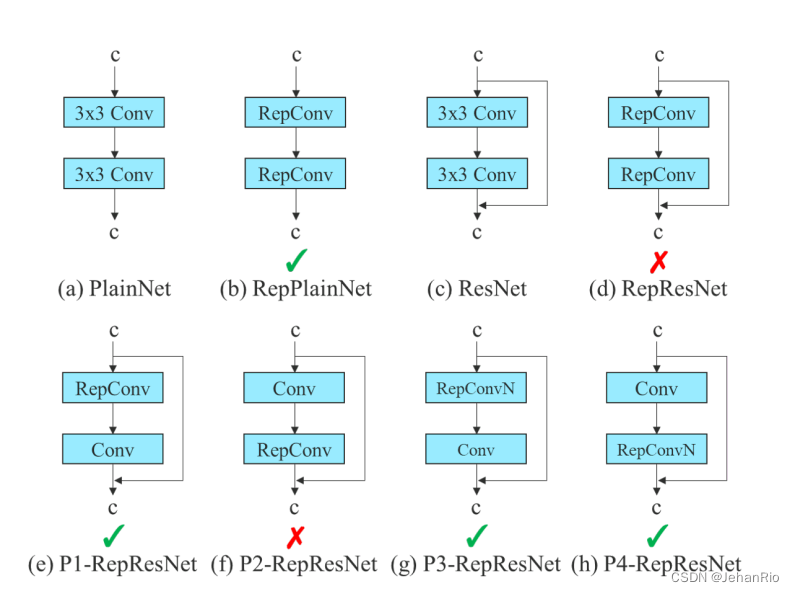
在代码中,可以发现,作者仅仅只在推理阶段使用了RepConv,且是最基本的RepConv,即图b那种。
6. 标签分配器
- 先知道一个概念:深度监督。
意思是在模型训练的过程中,除了最终的检测头,在中间的层也增加了辅助检测头,这个辅助检测头也会加入到损失函数的计算中,并且辅助反向传播,去更新前面的参数。
- 另一个需要知道的概念是:标签分类。
标签分配指的是把输入图片中的标注框和最终预测的预测值对应起来,便于进一步求损失值。
我们知道,目标检测的损失往往由三个部分组成:分类损失Lcls,置信度损失Lobj与边界框的iou损失Lbox。Lcls与Lbox仅由正样本产生,而Lobj则由所有样本产生。
不同于DETR这种端到端的目标检测算法,YOLO会产生大量的预测框,每一个预测框称之为一个样本。那么对于产生的这些预测框,哪些应该作为正样本去与gt(ground truth)计算Lbox与Lcls,哪些又应该作为负样本仅仅贡献Lobj呢?这就取决于所定义的标签分配方法。
在过去的深度网络训练中,标签分配通常直接引用GT(真实标签),并根据给定的规则生成硬标签。比如YOLOv5中,根据中心点所在的位置加入附近两个格子,即同时分配给三个位置来预测。这种方法就叫做硬标签,因为他是直接根据gt来直接产生每个格子的标签,传入损失函数中求损失值。
而YOLOv7中使用的是软标签分配方法。在该方法中,Head产生的预测值和GT一起传给分配器,才会得到每个网格的目标值,利用这里的软标签再和预测值一起传入损失函数中求损失值。

关于这个分配器,在YOLOv7中用到的是ComputeLossOTA 。这里先按下不表。
常规思路是:由于用到了辅助头训练,因此分开求Lead Head和辅助头的软标签和损失值。
但YOLOv7提出了2种新方法。
- 第一种是辅助头求Loss时,直接利用Lead Head产生的软标签进行计算。
- 第二种是在第一种的基础上产生了course标签和fine标签两种标签。(比较难)

一般训练比较大的模型时才会用到这个技巧,训练的速度也会非常的慢,在我之前的实验中,没有用到,所以对这块了解也不太多。这块对应的yaml文件是yolov7-d6.yaml、yolov7-e6.yaml、yolov7-e6e.yaml、yolov7-w6.yaml,最后的输出也有所变化。

粗标签和细标签究竟是什么?
首先是细标签,网络最终输出的三个head是Lead head,会将这部分的预测结果与ground truth生成soft label,网络会觉得这个soft label得到是数据分布更接近真实的数据分布,训练得到的内容更加“细致”,再来说说粗标签,Auxiliary head由于是从中间网络部分得到的,它的预测效果肯定是没有深层网络Lead head提取到的数据或者特征更细致,所以Auxiliary head部分的内容是比较“粗糙”的,在训练过程中,会将Lead head与ground truth的soft label当成一个全新的ground truth,然后与Auxiliary head之间建立损失函数,说白了,就是让辅助head的预测结果也“近似”为Lead head
7. 一些未解决的问题
- 软标签的代码实现和他的损失函数。
- 论文实验部分的阅读。
8. 总结
本文提出了一种新的实时检测器,解决了重参化模块的替换问题和动态标签的分配问题。
主要贡献:
- 高效聚合网络架构:对ELAN扩展,提出了E-ELAN
- 重参数化卷积:将模型重参数化引入到网络架构中,并重新规划设计了RepVGGN(重参数化这一思想最早出现于 RepVGG 中)
- 辅助头检测:将 head 部分的浅层特征提取出来作为 Auxiliary head ,深层特征也就是网络的最终输出作为 Lead head
- 基于级联的模型缩放:对连接结构的网络进行尺度缩放时,只缩放计算块的深度,转换层的其余部分只进行宽度的缩放
- 动态标签分配策略: Lead head 导向标签分配方法和由粗到精的 lead head 指导标签分配方法
Reference
B站 科科带你学:YOLOv7论文,网络结构,官方源码,超详细解析
CSDN 江小皮不皮:YOLOV7详细解读(二)论文解读
CSDN 爱吃肉的鹏:YOLOv7论文部分解读【含自己的理解】

