
- 1windows 下 cudnn的安装方法_cudnn安装
- 2IOday7作业
- 3数学建模【粒子群算法】
- 4书生·浦语大模型 实战营第二节 笔记
- 5盘点2021丨年度精选教程干货全汇总,一定有你用得上的!
- 6一级缓存(默认开始sqlsession级别)和 二级缓存(testTwoCache)_sqlsession缓存
- 7计算机网络——Wireshark软件使用与协议分析(ARP协议、IP与ICMP分析)_使用网络分析仪(例如wireshark)来捕获网络数据包并分析其中的arp请求和响应
- 8某省公共资源交易公共服务平台数据解密,headers中的portal-sign加密_福建公共资源平台加密
- 9Python学习路线图(2020最新版)_python学习路图谱
- 10neo4j 节点显示名称_[Neo4j] neo4j 的python操作
【论文解读】| 通过大语言模型实现通用模糊测试
赞
踩

本次分享论文为:Universal Fuzzing via Large Language Models
论文标题:Universal Fuzzing via Large Language Models
论文作者: Steven Chunqiu, Xia, Matteo Paltenghi, Jia Le Tian, Michael Pradel, Lingming Zhang, Matteo Xia, Jia Paltenghi, Michael Le Tian, Lingming Pradel, Zhang
作者单位: University of Illinois Urbana-Champaign, USA; University of Stuttgart, Germany
关键词: Fuzzing, Large Language Models, Software Testing, Vulnerability Discovery
原文链接:
https://arxiv.org/pdf/2308.04748.pdf
论文简介:本论文提出了Fuzz4All,一个利用大型语言模型(LLMs)来实现通用模糊测试的方法。与传统fuzzing工具相比,该框架能够针对多种输入语言和特性进行模糊测试,通过生成多样化且真实的输入,显著提高软件测试的覆盖率和发现漏洞的能力。
研究背景:对软件开发的基础构建块,如编译器、运行时引擎和API库,进行高效的模糊测试尤为重要。然而,现有的模糊测试工具往往受限于特定的输入语言或特性,难以适应软件和语言的快速发展。
研究贡献:
1.提出了一个通用模糊测试框架,可以应对多种语言和特性。
2.引入了自动提示(autoprompting)技术,自动提炼用户输入为高效的模糊测试提示。
3.实现了一个基于LLM的模糊测试循环,通过迭代更新提示来生成多样化的测试输入。
4.在九个不同的系统上进行了实验,展示了Fuzz4All与现有工具相比在代码覆盖率和bug发现上的显著改进。
当前软件安全领域面临的一大挑战是如何有效地发现和修复各种软件系统中的漏洞。尽管fuzzing技术在过去几十年中取得了显著进展,但大多数现有方法都集中在特定的编程语言或软件版本上,限制了它们的通用性和适应性。针对这一问题,研究者提出了一种新的fuzzing方法,该方法利用大型语言模型的能力,不仅能够理解和生成特定语言的代码,还能够自适应地学习和应对新的语言特性和版本变化。
模糊测试的两大类方法是基于生成的模糊测试和基于变异的模糊测试。基于生成的模糊测试直接合成完整的代码片段,而基于变异的模糊测试则是对一组高质量的种子进行变异操作。传统的模糊测试面临三大挑战:与目标系统和语言的紧密耦合、缺乏对语言种类的支持、以及生成能力的限制。Fuzz4All通过引入LLM作为输入生成和变异引擎,以及自动提示技术,有效应对了这些挑战。
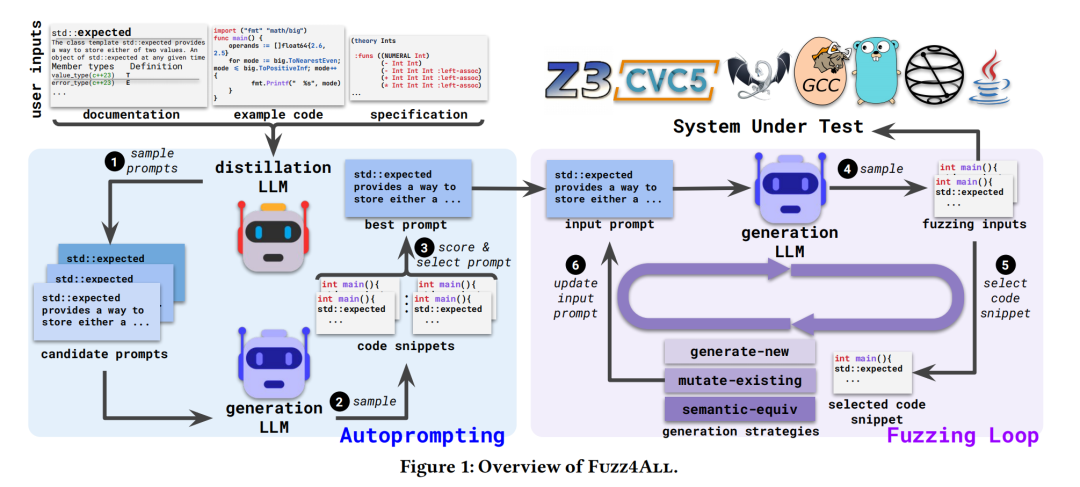
理论背景
Fuzz4All的核心在于使用大型语言模型作为生成测试输入的工具,这些模型通过大量编程语言示例的预训练,能够理解语言的语法和语义。
方法实现
1.自动提示:通过自动化的过程提炼用户输入,生成适合模糊测试的提示。
2.模糊测试循环:利用LLM迭代更新提示,生成多样化的测试输入。
a. 实验设置
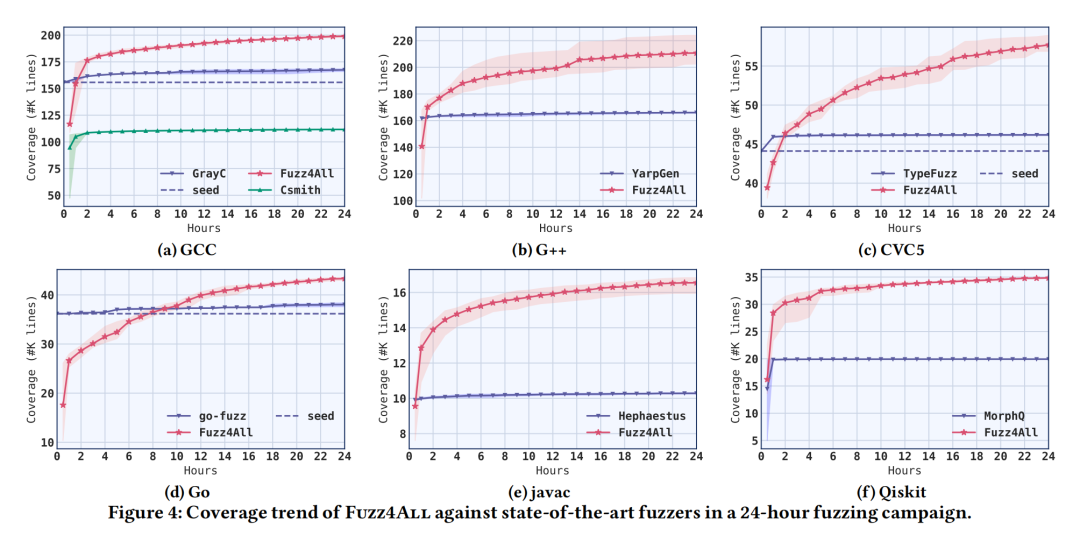
实验设计涵盖了六种输入语言(C、C++、SMT、Go、Java和Python)以及九个系统。对Fuzz4All进行了与现有基于生成和基于变异的模糊测试工具的比较,测试了24小时的模糊测试预算,并进行了五次重复。此外,实验还考察了不同组件对Fuzz4All有效性的贡献,并通过反复迭代测试来减少长时间模糊测试运行中的变异。
b.实验结果:
实验结果表明Fuzz4All在所有六种语言上均实现了比现有语言特定模糊测试工具更高的代码覆盖率。此外,Fuzz4All还发现了76个bug,其中47个被开发者确认为之前未知的。
Fuzz4All通过利用大型语言模型的强大能力,成功实现了一个通用的模糊测试框架,能够自动适应多种语言和特性。这一方法不仅提高了软件测试的覆盖率,还能有效发现之前未被发现的bug,对提升软件的可靠性和安全性具有重要意义。


