
- 110 Hadoop的安全模式及权限介绍
- 22023年5月青少年软件编程等级考试(C语言)一级试卷及C语言版答案_青少年 一级c 考试
- 3windows下的win+ 快捷键_windows+下
- 4android反编译-修改别人apk(如何无视R文件,使用新增布局xml drawable等)_android studio反编译
- 5linux简单命令_finalshell命令大全
- 6人工智能-基础篇04篇-人工智能中名词LLM、NLP和GLM介绍_glm llm
- 7PHP在线客服系统IM即时通讯聊天源码_辰光客服系统源码
- 8windwos10搭建我的世界服务器,并通过内网穿透实现联机游戏Minecraft_windows server mc服务器
- 9Linux内核源码list.h解读_config_debug_list
- 10关机时没有退出clash代理,导致重启后浏览器无法访问网页
Redis的线程模型_redis线程模型
赞
踩
一、Redis为何选择单线程
在Redis6.0之前,Redis的核心网络模型选择单线程来实现
正如redis官网上说,对于一个 DB 来说,CPU 通常不会是瓶颈,因为大多数请求不会是 CPU 密集型的,而是 I/O 密集型。具体到Redis 的话,如果不考虑 RDB/AOF 等持久化方案,Redis是完全的纯内存操作,执行速度是非常快的,因此这部分操作通常不会是性能瓶颈,Redis 真正的性能瓶颈在于网络 I/O,也就是客户端和服务端之间的网络传输延迟,因此 Redis 6.0版本前选择了单线程的 I/O 多路复用来实现它的核心网络模型
实际上选择单线程原因如下
1.避免过多的上下文切换
2.避免同步机制的开销
如果选择多线程,势必会涉及到底层数据同步的问题,这时可能会引入某些同步机制,比如锁,但是我们知道Redis不仅仅提供了简单的 key-value 数据结构,还有 list、set 和 hash 等等其他丰富的数据结构,而不同的数据结构对同步访问的加锁粒度又不尽相同,可能会导致在操作数据过程中带来很多加锁解锁的开销,增加程序复杂度的同时还会降低性能
3.简单可维护
二、Redis真的是单线程么
讨论这个问题,我们可以从Redis的版本中的两个重要节点说起:
- Redis4.0:引入多线程处理的异步操作,通过非阻塞命令进行异步化,避免阻塞单进程的事件循环
- Redis6.0:在网络模型中实现多线程IO
我们平时说redis是单线程,主要指的是redis的网络IO的读取与数据库操作都在同一个线程中完成
在Redis6.0中引入多线程IO,也只是用来处理网络数据的读写和协议的解析,而执行命令依旧是单线程
三、Redis的单线程IO多路复用模型
Redis是基于reactor模型开发了网络事件处理器,这个处理器叫做文件事件处理器,
这个文件事件处理器是单线程的,所以Redis才叫做单线程模型;IO多路复用是IO模型的一种,多路指的是多个socket连接,复用指的是复用一个线程。
100%弄明白5种IO模型
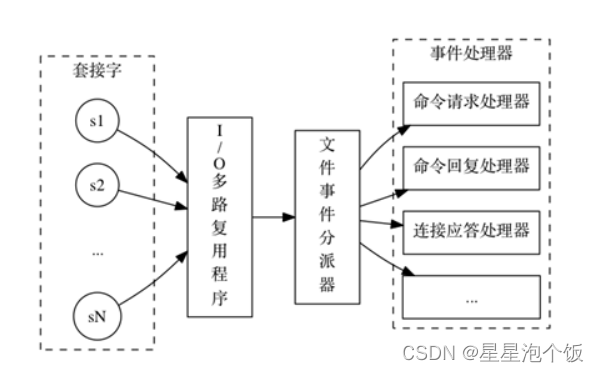
文件事件处理器的结构包含4个部分:
①多个socket
②IO多路复用程序:监听多个socket
③文件事件分派器:分派事件
④事件处理器(命令请求处理器,命令回复处理器,连接应答处理器)
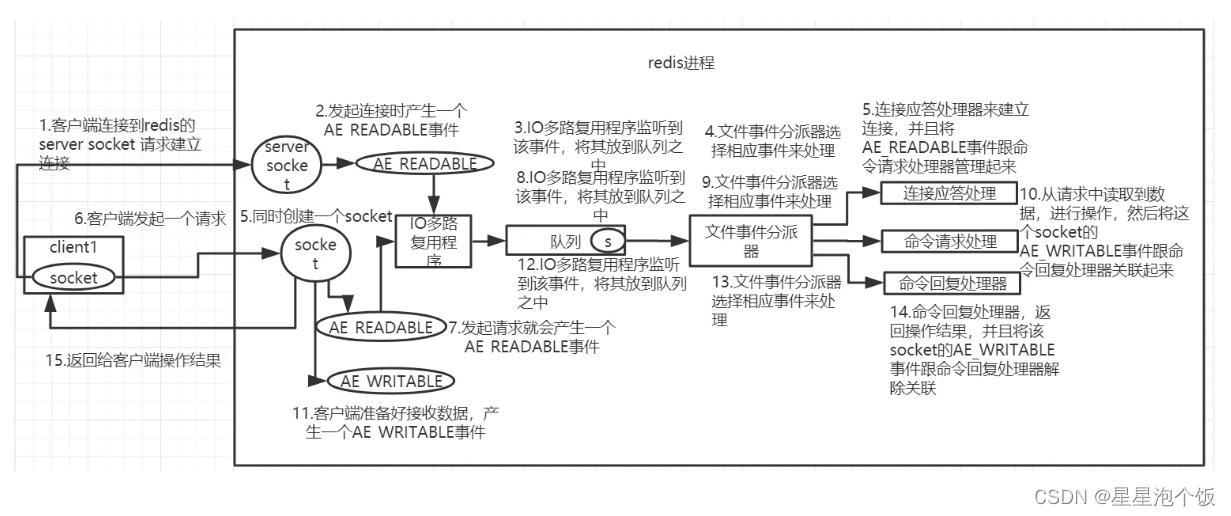
客户端与Redis通信的一次完整流程:
1.在redis启动初始化的时候,redis会将连接应答处理器跟AE_READABLE事件关联起来,接着如果一个客户端跟redis发起连接,此时会产生一个AE_READABLE事件,然后由连接应答处理器来处理跟客户端建立连接,创建客户端对应的socket,同时将这个socket的AE_READABLE事件跟命令请求处理器关联起来。
2.当客户端向redis发起请求的时候(不管是读请求还是写请求,都一样),首先就会在socket产生一个AE_READABLE事件,然后由对应的命令请求处理器来处理。这个命令请求处理器就会从socket中读取请求相关数据,然后进行执行和处理。
3.接着redis这边准备好了给客户端的响应数据之后,就会将socket的AE_WRITABLE事件跟命令回复处理器关联起来,当客户端这边准备好读取响应数据时,就会在socket上产生一个AE_WRITABLE事件,会由对应的命令回复处理器来处理,就是将准备好的响应数据写入socket,供客户端来读取。
4.命令回复处理器写完之后,就会删除这个socket的AE_WRITABLE事件和命令回复处理器的关联关系。
四、Redis6.0多线程的实现机制
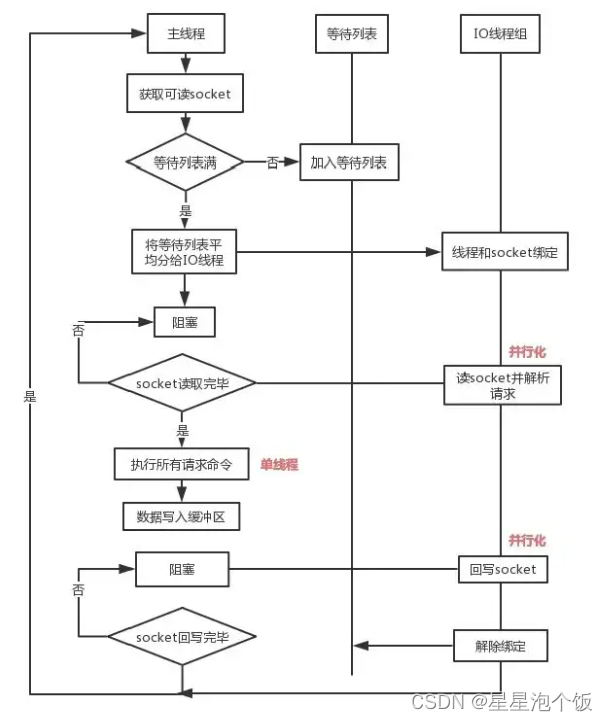
具体实现步骤:
1.主线程负责接收建立连接的多个socket放入全局等待队列中,等待读处理队列
2.主线程通过轮询将可读socket分配给IO线程
3.此时主线程阻塞等待IO线程读取socket完成
4.主线程执行IO线程读取和解析出来的redis请求命令
5.主线程阻塞等待IO线程将指令的执行结果写回socket
6.主线程清空全局队列,等待客户端的后续请求
也就是说具体命令执行还是由main线程所在的事件循环单线程处理,只是读写socket事件由IO线程来处理。虽然多线程方案能提升1倍以上的性能,但在我看来整个方案仍然比较粗糙:
- 首先所有命令的执行仍然在主线程中进行,仍然存在性能瓶颈。
- 另外IO 读写为批处理读写,即所有 IO线程先读取完请求数据并且解析为redis命令后,主线程才开始执行解析的命令;然后待主线程执行完所有的redis命令后,才让所有 IO线程再一起回复所有响应;也就是说不同请求需要相互等待,效率不高。

