
- 13D力导向树插件-3d-force-graph学习001_3d-force-graph 加载数据方法
- 2Stable Diffusion webui安装详细教程
- 3UE4学习笔记 03_虚幻 set member
- 4STM32MP15x TF-A移植_export fip_deploydir_root = /home/qqqq/下载/stm32mp/
- 5用pytorch实现神经网络_pytorch 神经网络
- 6数据湖在爱奇艺数据中台的应用
- 7【维纳滤波】通过MATLAB自带的维纳滤波函数进行滤波_维纳滤波matlab
- 8Unity3D GUILayout_unity guilayout
- 9Unity3D 实用技巧 - Unity Shader 汇总式学习·初探篇
- 10[D3D_XD项目]D3DCamera类_d3d的camera
K-means聚类算法_分别取k=2和3,利用k-means聚类算法
赞
踩
K-means(K均值)是基于数据划分的无监督聚类算法,也是数据挖掘领域的十大算法之一。
何为聚类算法?在某种程度上可以理解为无监督的分类方法。
聚类算法可以分为哪些部分? 一般来说可以分为基于划分的方法、基于连通性的方法、基于密度的方法、基于概率分布模型的方法等。K-means就是经典的基于划分的聚类方法。
1、K-means的基本原理
对于基于划分的这一类聚类算法而言,其方法是将样本的矢量空间划分为多个区域
其中1()为指示函数,即代表样本x是否属于区域S。
不同的基于划分的聚类算法的主要区别就在于如何建立相应的映射方式
k-means算法的主要实现步骤有以下四步:
- 初始化聚类中心
C(0)1 ,C(0)2 ,C(0)3 …,,C(0)k ,可选取前K个样本或者随机选取K个样本; - 分配各个样本
xj 到最相近的聚类集合,样本分配依据为:式中i=1,2,…,k,S(t)i={xj∣∥xj−c(t)j∥22≤∥xj−c(t)p∥22} p≠j - 根据步骤2的分配结果,更新聚类中心:
c(t+1)i=1|S(t)i|∑xj∈S(t)ixj - 若迭代次数达到最大迭代步数或者前后两次迭代的差小于设定阈值
ε ,即∥c(t+1)i−c(t)i∥22<ε ,则算法结束,否则重复步骤2。
2、k-means++
k-means对聚类中心的初始化比较敏感,不同的初始值会带来不同的聚类结果,这是因为k-means仅仅是对目标函求近似局部最优解,不能保证得到全局最优解,所以不同的初始聚类中心可能会导致不同的划分结果,产生较大的偏差。
为了解决(缓解)上面这种情况,有人提出了k-means++算法。k-means++与普通的k-means算法的区别在于初始化起始点的方法不同,k-means是从样本中随机的抽取K个作为聚类的初始中心点,而k-means++算法选择初始中心点要求初始的聚类中心之间的相互距离要尽可能的远。
该算法的描述是如下:
- 从输入的数据点集合中随机选择一个点作为第一个聚类中心
- 对于数据集中的每一个点x,计算它与最近聚类中心(指已选择的聚类中心)的距离D(x)
- 选择一个新的数据点作为新的聚类中心,选择的原则是:D(x)较大的点,被选取作为聚类中心的概率较大
- 重复2和3直到k个聚类中心被选出来
- 利用这k个初始的聚类中心来运行标准的k-means算法
从上面的算法描述可以看出,k-means++与k-means的主要区别在第三步,即在确定第一个随机的聚类中心后,之后的聚类中心相互之间要尽可能的距离最远,其实这样也比较容易理解,聚类点比较分散时,能更加容易的划分出正确的分类,如果初始点比较聚集,那分类的效果肯定不理想了。
3、Kernel K-means和Spectral Clustering
经典的k-means采取二次欧氏距离作为相似性的度量,并且假设分类时的聚类误差是服从正态分布的,因此k-means在处理非标准正态分布和非均匀样本集合时聚类效果较差。
对于非标准正态分布和非均匀分布的样本,k-means聚类效果不好,其主要原因是k-means是假设相似度可以用二次欧式距离等价的衡量,但是在实际的样本集合中这个假设不一定实用。
为了有效客服这个局限性假设,k-means需要推广到更广义的度量空间。经典的两种改进框架就是Kernel K-means和Spectral Clustering(谱聚类)。
Kernel k-means将样本点
Spectral Clustering算法尝试着变换样本的度量空间,首先求取样本集合的仿射矩阵,然后计算仿射矩阵的特征向量,利用得到的特征向量进行k-means聚类。其实仿射矩阵隐含的重新定义了样本点的相似性。
笔者并未在Kernel k-means和Spectral Clustering进行过多的学习,因此可说的不多,这里给一篇讲这两种方法的文章:Kernel k-means, spectral clustering and normalized cuts
4、二分k-means聚类
按照k-means的聚类规则,其很容易就陷入局部最小值。为了解决这一问题。有人提出了二分k-means聚类算法。其中心思想是:首先把所有样本看成一个簇,而后二分这个簇,接着选择其中一个簇继续进行二分,直到选出了K个簇。至于选取哪个簇继续二分,其选取的原则是二分这个簇后会使总的误差平方和最小。这里的误差平方和可以理解为各样本到聚类中心点的距离和。
这里的主要思想其实很好理解,假设这里有三个类A、B、C,在上一次二分的时候,A和B因为靠的比较近,被划在了同一个簇
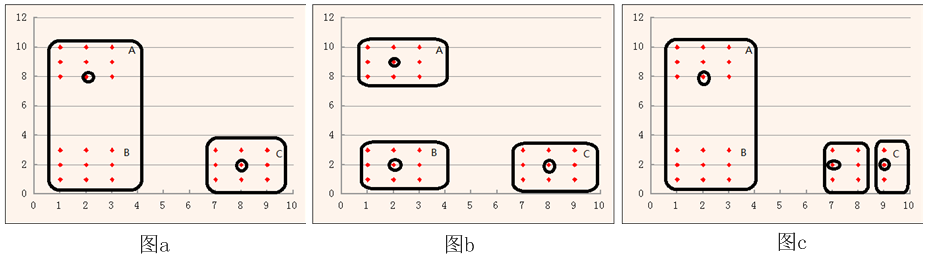
为方便解释,笔者绘制了上面这三幅图,绘图水平较差,大家凑合看。
图a中,上一次的二分,将这个样本集分为两个新的簇,左边A和B一起构成了簇
图b中,选取了簇
图c中,选取了簇
参考资料:
- 视觉机器学习20讲(最近刚出的书,写的很好)
- 机器学习算法与Python实践之(六)二分k均值聚类
- k-means++算法
kernel k-means && Spectral Clustering
我会在后面的博客贴出代码,敬请关注!

