
- 1windows10激活错误_运行slui.exe以显示错误文本
- 2电子凭证 : Java 生成 Pdf
- 3oracle数据库事务的四大特性与隔离级别与游标
- 4PostgreSQL 对称加密、非对称加密用法介绍
- 5通过InputStream读取文件的常见用法_inputstream获取文件名
- 6WPF实现截屏(仿微信)
- 7java对接grpc接口详解_java调用grpc服务
- 8python四川成都旅游景点数据可视化大屏全屏系统设计与实现(django框架)_成都游客量 可视化分析
- 9STM32MP15x TF-A移植_export fip_deploydir_root = /home/qqqq/下载/stm32mp/
- 10链式队列实现(c语言)_链队列打印
深入理解LInux ELF可执行程序_分析elf可执行程序
赞
踩
认识可执行程序
一个源文件在生成可执行程序的过程中地址需要经过以下几个主要步骤。

源文件在经过编译器处理之后会生成可重定位目标文件,也就是我们常见的.o文件,经过链接器处理之后,会将多个.o文件处理成可执行文件。
- 可从定位目标
.o 称为可重定位目标,包含二进制代码和数据,其形式可以和其他目标进行合并,创建一个可执行目标文件
因为.o文件也是ELF文件的一种,所以我么可以使用readelf -h 来查看.o文件的elf头数据
$ readelf -h main.o
ELF 头:
Magic: 7f 45 4c 46 02 01 01 00 00 00 00 00 00 00 00 00
类别: ELF64
数据: 2 补码,小端序 (little endian)
Version: 1 (current)
OS/ABI: UNIX - System V
ABI 版本: 0
类型: REL (可重定位文件)
系统架构: Advanced Micro Devices X86-64
版本: 0x1
入口点地址: 0x0
程序头起点: 0 (bytes into file)
Start of section headers: 960 (bytes into file)
标志: 0x0
Size of this header: 64 (bytes)
Size of program headers: 0 (bytes)
Number of program headers: 0
Size of section headers: 64 (bytes)
Number of section headers: 14
Section header string table index: 13
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
通过与文件头结构体对比
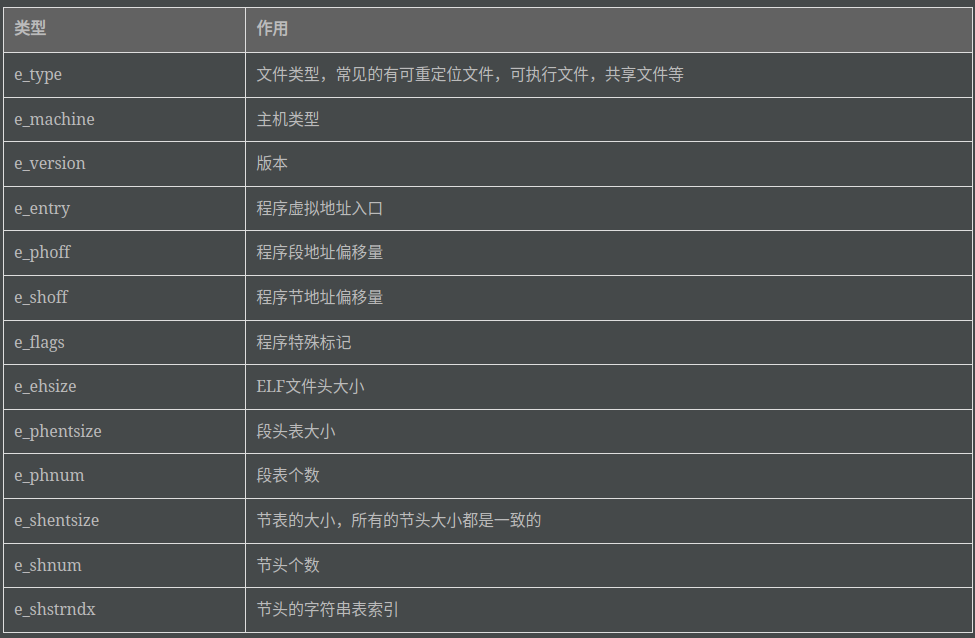
typedef struct
{
unsigned char e_ident[EI_NIDENT]; /* Magic number and other info */
Elf64_Half e_type; /* Object file type */
Elf64_Half e_machine; /* Architecture */
Elf64_Word e_version; /* Object file version */
Elf64_Addr e_entry; /* Entry point virtual address */
Elf64_Off e_phoff; /* Program header table file offset */
Elf64_Off e_shoff; /* Section header table file offset */
Elf64_Word e_flags; /* Processor-specific flags */
Elf64_Half e_ehsize; /* ELF header size in bytes */
Elf64_Half e_phentsize; /* Program header table entry size */
Elf64_Half e_phnum; /* Program header table entry count */
Elf64_Half e_shentsize; /* Section header table entry size */
Elf64_Half e_shnum; /* Section header table entry count */
Elf64_Half e_shstrndx; /* Section header string table index */
} Elf64_Ehdr;
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
首先看到的是Magic魔法数字,这些数字的大小由宏定义 #define EI_NIDENT (16) 来进行限定,Magic放在ELF文件的头部的16字节,其中各个字节的含义如下:

通过readelf -S 我们可以根据地址的偏移来大致给出可重定位文件的组成组成如下:

- 可执行文件
我们将同样的源码编译成可执行程序,然后使用readelf -h查看可执行文件的的头:
$ readelf -h a.out
ELF 头:
Magic: 7f 45 4c 46 02 01 01 00 00 00 00 00 00 00 00 00
类别: ELF64
数据: 2 补码,小端序 (little endian)
Version: 1 (current)
OS/ABI: UNIX - System V
ABI 版本: 0
类型: DYN (共享目标文件)
系统架构: Advanced Micro Devices X86-64
版本: 0x1
入口点地址: 0x1060
程序头起点: 64 (bytes into file)
Start of section headers: 14744 (bytes into file)
标志: 0x0
Size of this header: 64 (bytes)
Size of program headers: 56 (bytes)
Number of program headers: 13
Size of section headers: 64 (bytes)
Number of section headers: 31
Section header string table index: 30
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
使用readelf -S 来看一下可执行文件的段组成大致如下:

通过对可重定位文件和可执行文件的头部对比,我们可以看出主要有如下几点不同:

[IMPORTANT]
上面的过程都是通过官方的工具才看到的,那么官方工具会不会欺骗我们,真实的可执行程序真的是readelf输出的这样来组成的吗?
我们可以仿照readelf给出的信息自己来解析一下ELF文件,来从一个切实存在的ELF文件来了解ELF文件的构成
.https://github.com/zzu-andrew/note_book/src/elf_parser/elf_parser.h
// 1. 将可执行文件加载到内存中
mmap_res = ::mmap(nullptr, program_length_, PROT_READ, MAP_PRIVATE, fd_, 0);
if (mmap_res == MAP_FAILED)
{
ERROR_EXIT("mmap");
}
mmap_program_ = static_cast<std::uint8_t *>(mmap_res);
// 2. 取出文件头
file_header = reinterpret_cast<Elf64_Ehdr *>(mmap_program_);
// 3. 取出段头和表头
const Elf64_Ehdr *file_header;
const Elf64_Shdr *section_table;
const char *section_string_table;
size_t section_string_table_index;
Elf64_Xword section_number;
file_header = reinterpret_cast<Elf64_Ehdr *>(mmap_program_);
section_table = reinterpret_cast<Elf64_Shdr *>(mmap_program_ + file_header->e_shoff);
// e_shstrndx = 35
section_string_table_index = file_header->e_shstrndx == SHN_XINDEX ?
reinterpret_cast<Elf64_Shdr *>(&mmap_program_[file_header->e_shoff])->sh_link :
file_header->e_shstrndx;
section_string_table = reinterpret_cast<char *>(&mmap_program_[section_table[section_string_table_index].sh_offset]);
section_number = reinterpret_cast<Elf64_Shdr *>(&mmap_program_[file_header->e_shoff])->sh_size;
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
经过以上步骤之后将文件头的信息打印如下:
$3 = {e_ident = "\177ELF\002\001\001\000\000\000\000\000\000\000\000", e_type = 3, e_machine = 62, e_version = 1, e_entry = 4512, e_phoff = 64, e_shoff = 36184, e_flags = 0, e_ehsize = 64, e_phentsize = 56,
e_phnum = 13, e_shentsize = 64, e_shnum = 36, e_shstrndx = 35}
- 1
- 2
通过读取打开文件的大小,得出整个可执行文件的大小为: fileSize = 38488
通过文件头我们可以知道: +
ELF头大小为: e_ehsize = 64 +
段头表偏移为: e_phoff = 64 大小为 e_phentsize = 56, 个数为 e_phnum = 13 +
节头表偏移地址为 :e_shoff = 36184, 大小为 e_shentsize = 64, 个数为 e_shnum = 36 +
节地址偏移: 36184 +
ELF头在头部, 我们直接将指向头部的指针强转成 Elf64_Ehdr 之后,取出的数据完全和对应的文件相符,因此可以看出ELF头放在文件的头部确实和readelf输出的一样。
然后按照偏移量来计算,段头部应该紧跟ELF头部之后,因此,段的位置应该在头部指针向后偏移64位的地方通过查看e_phoff的值确实是64
那么我们在来验证一下尾部是否是节头表存放的地方,通过ELF头我们知道,节头的大小为64, 节头的偏移位置为36184, 节头个数为36,按照上图来说,节头在最后的部分,那么肯定会存在fileSize - e_shoff = e_shentsize * e_shnum这种等式,否则就说明节头没有把ELF可执行程序的尾部填满。
38488 - 36184 = 2304 = 36 * 64(节头长度)
- 1
经过计算,整个ELF文件的尾部确实都是节头填充的。
其他节占用的验证大家可以在原有程序的基础上进行验证,这里就不一一进行验证了
-pie && -no-pie
细心的读者有可能会发现,我上面使用readelf -h读出可执行文件的类型都显示为共享类型,这个是因为我的系统是ubuntu导致的,现在很多Ubuntu系统的默认编译器都会在编译程序是默认添加 -pie 选项而这个选项会导致生成的可执行程序被标记为共享类型
pie(Position-Independent-Executable)能用来创建介于共享库和通常可执行程序之间的程序,是一种能像共享库一样可重分配地址的程序。
PIE最早由RedHat的⼈实现,他在链接器上增加了-pie选项,这样使⽤-fPIE编译的对象就能通过链接器得到位置⽆关可执⾏程序。
标准的可执⾏程序需要固定的地址,并且只有被装载到这个地址时,程序才能正确执⾏。PIE能使程序像共享库⼀样在主存任何位置装载,这需要将程序编译成位置⽆关,并链接为ELF共享对象。
引⼊PIE的原因是让程序能装载在随机的地址,通常情况下,内核都在固定的地址运⾏,如果能改⽤位置⽆关,那攻击者就很难借助系统中的可执⾏码实施攻击了。类似缓冲区溢出之类的攻击将⽆法实施。⽽且这种安全提升的代价很⼩。
关于Linux二进制的整体分析已经放到了 [https://github.com/zzu-andrew/note_book/src/elf_parser]
全文文档见:https://github.com/zzu-andrew/note_book/Linux/Linux二进制分析.adoc
关注不迷路,微信公众号:码上有话



